

An Engineering Guide to Data Creation - A Data Contract perspective - Part 1
An Engineering Guide to Data Creation - A Data Contract perspective - Part 1
By Ananth Packkildurai

Why should we care about Data Creation Process?
All Successful Data-Driven organizations have one thing in common; They have a high-quality & efficient data creation process. Data creation is often the differentiator between the success & the failure of a data team.
Any business in the modern digital era can be considered a workflow engine. A business process or workflow engine is a software system that enables businesses to execute well-defined steps to complete a user’s intention. It could be either booking a taxi or ordering your lunch; everything is a workflow engine.
Let’s look at the simplified business process of Uber’s ride-sharing. The real-world scenario is much more complex than this, but for the scope of this blog, let’s keep the ride-sharing business process into three simple steps.
The riders request a new ride.
The ride-share app finds the closest driver and requests to accept the ride.
Once accepted, the Rider and Driver connected to complete the journey.
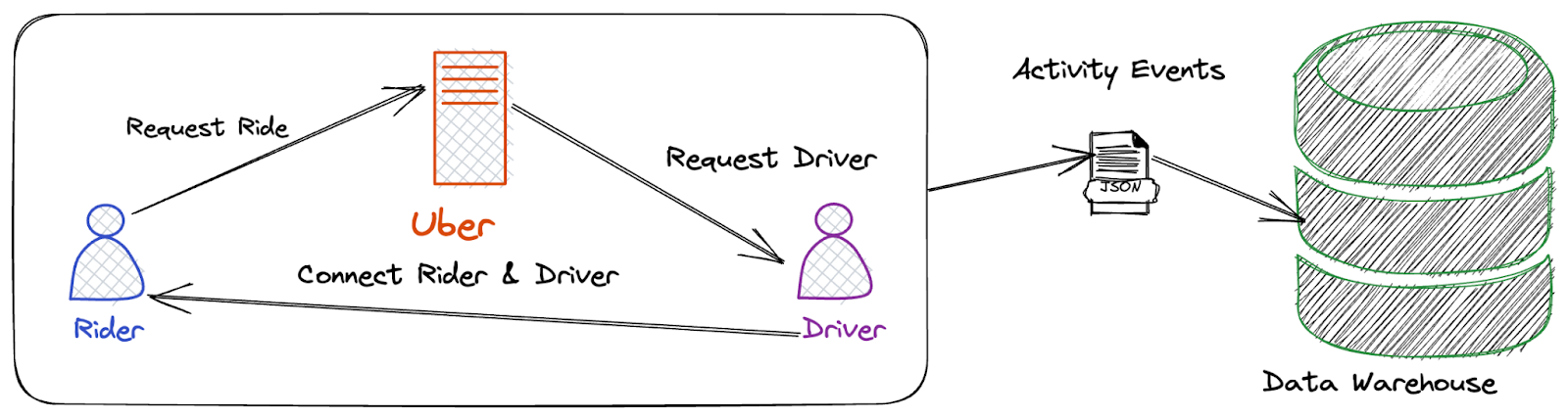
Data engineering starts to add value to the business by capturing events at each step of the business process. The events are then further enriched and analyzed to bring visibility to business operations.
From the Event Modeling perspective, In the ride-sharing example, Rider & Driver are called Entities, whereas Request for a Ride & Request for a Driver is called Events. Entities and Events are the two functional units for data creation, and the success of your data organization depends on the stability of the Entity and Event creation architecture.
Please visit https://github.com/ananthdurai/schemata#schema-classification for a more in-depth understanding of schema classifications.
Architectural patterns for Data Creation
There are three types of architecture patterns in data creation.
Event Sourcing
Change Data Capture [CDC]
Outbox pattern
1. Event Sourcing
Event sourcing is a system design pattern that writes the current state of the business process into a journal of records. The journal of records will be immutable, in an append-only format. The journal of records is usually an HTTP server that transports to further downstream consumers to process.

In the rider business process, When a rider requests a new ride, the backend system verifies the authenticity of the request & estimates the price. Before finding the driver, it writes a journal event with the following format.
{
"event_timestamp": "2023-03-24T14:30:00Z",
"event_type": "ride_request",
"event_id": "1234567890",
"rider_id": "987654321",
"pickup_location": {
"latitude": 37.7749,
"longitude": -122.4194,
"address": "123 Main St, San Francisco, CA"
},
"destination_location": {
"latitude": 37.7749,
"longitude": -122.4113,
"address": "456 Broadway, San Francisco, CA"
},
"ride_options": {
"uber_x": {
"price_estimate": "$10-15",
"wait_time": "5 minutes"
},
"uber_pool": {
"price_estimate": "$5-8",
"wait_time": "10 minutes"
}
}
}The event is a structured data exchange format. It carries all the business context to the downstream consumers and enables them to run multiple analytical processes.
However, Event sourcing comes with a few major limitations.
Limitation #1: Unpredictable Quality of Events
In complex applications, the ride-sharing request can happen via a partner network or back office system where riders call and book a cab or any other possible channel. It leads to a need where a developer should instrument multiple code paths to generate the ride-sharing event. As the developers frequently change the code, it can introduce various bugs in the data generation code. The event may not trigger, have poor instrumentation quality, or have schema incompatibility.
Limitation #2: Lack of Transaction Guarantee
The application logic that changes the code path and event-sourcing systems will not be bound to the same transaction boundary. So there will be a case an event might trigger a ride request, but the transactional database may fail the request and vice versa. It leads to an inconsistent state between the downstream systems and the transactional database.
2. Change Data Capture [CDC]
The Change Data Capture (CDC) is a technique where instead of applications instrumenting the events, the CDC system monitors and records data modifications, such as insertions, updates, and deletions in the transaction storage and pipe into the downstream systems.
The CDC system reduces the unpredictable quality & completeness of the events since manual instrumentation is not applied here.
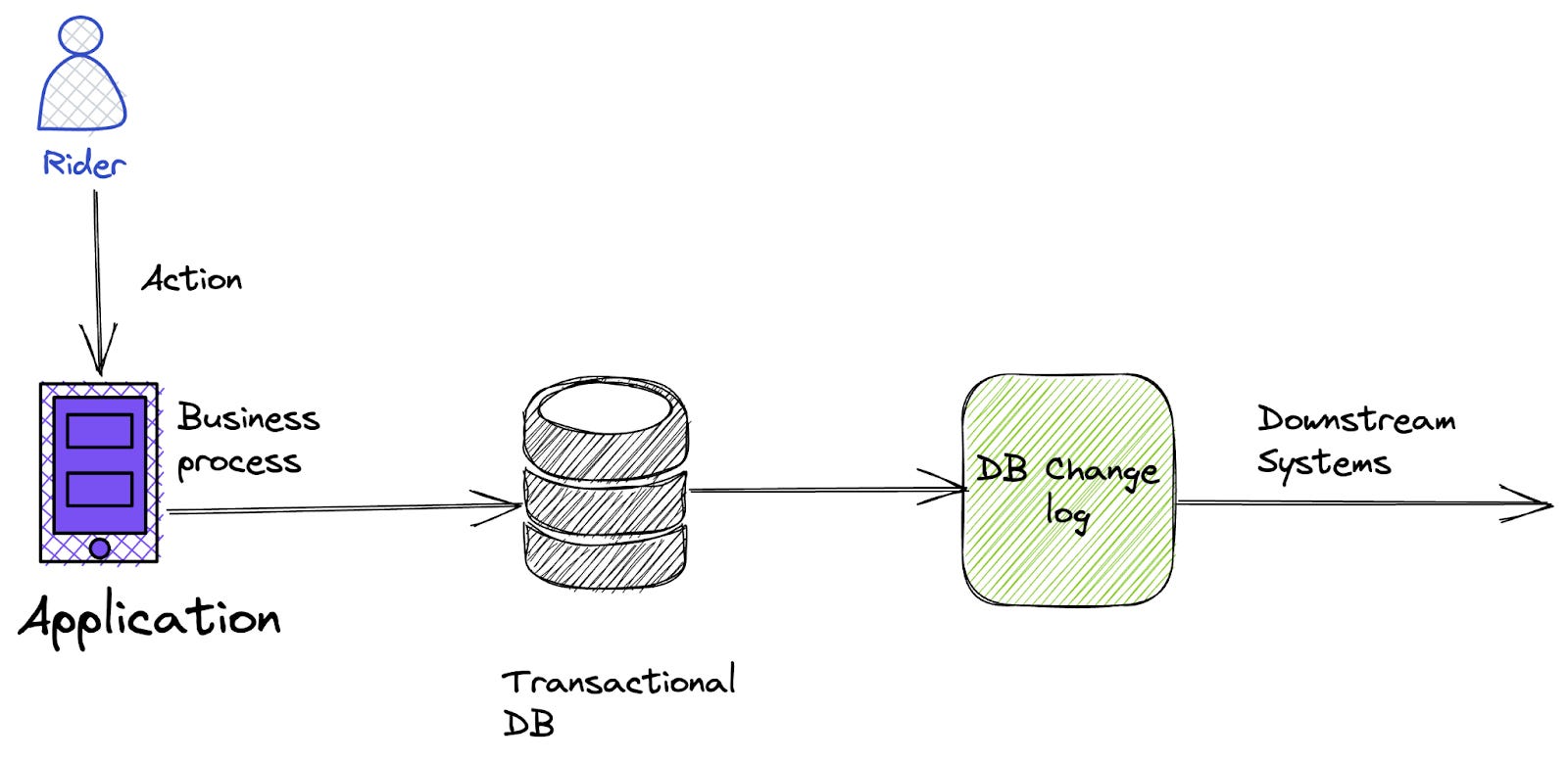
However, CDC has also come up with its own set of problems.
Drawback #1: Expensive re-Creation of Business Logic
CDC mirrors the transactional data models, a non-ideal data modeling format for the analytical downstream consumers. Let's take the same example of the ride-sharing event. The transactional db might be a model with a list of possible tables.
rider
location [pickup/ destination]
price
services
The CDC system monitors and continuously streams change data from each table. A downstream streaming middleware should join all the needed streams and create the ride-sharing event for downstream analytical consumption. Stream-stream, combined with a repetitive business logic implementation, is a solution any company wants to avoid.
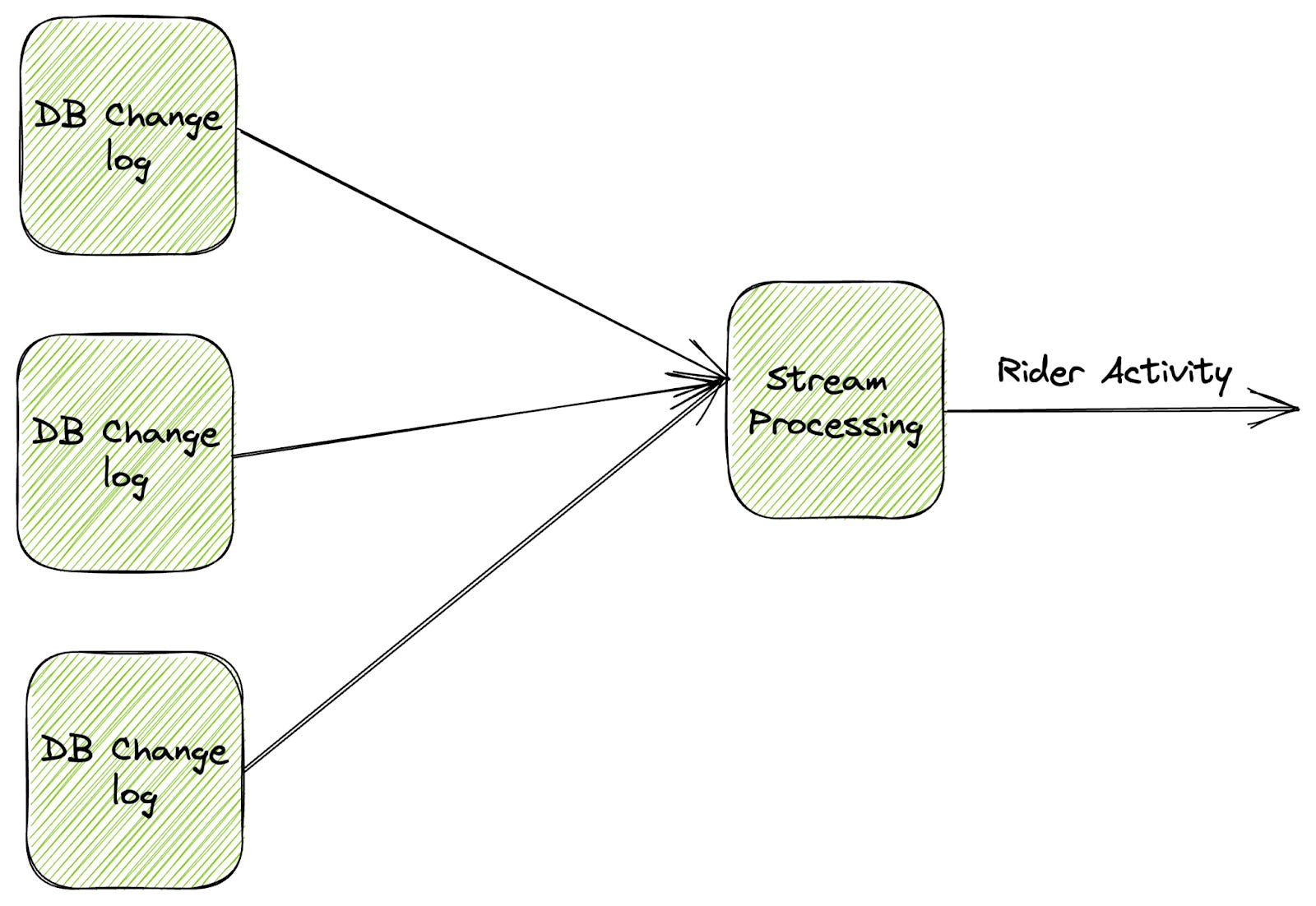
Other challenges with CDC include introducing a systematic load on the operation store. There are enough optimization techniques, like reading from isolated replicas and so on, to optimize the infrastructure complexity.
Outbox Pattern
While the CDC is trying to solve the unpredictable quality of events problem, The outbox pattern is trying to address the transactional guarantee of the events.
The outbox pattern enables the application developers to write events as part of the transaction while modifying the transactional database. Hence it guarantees consistency between the system of records modification and the events maintained.
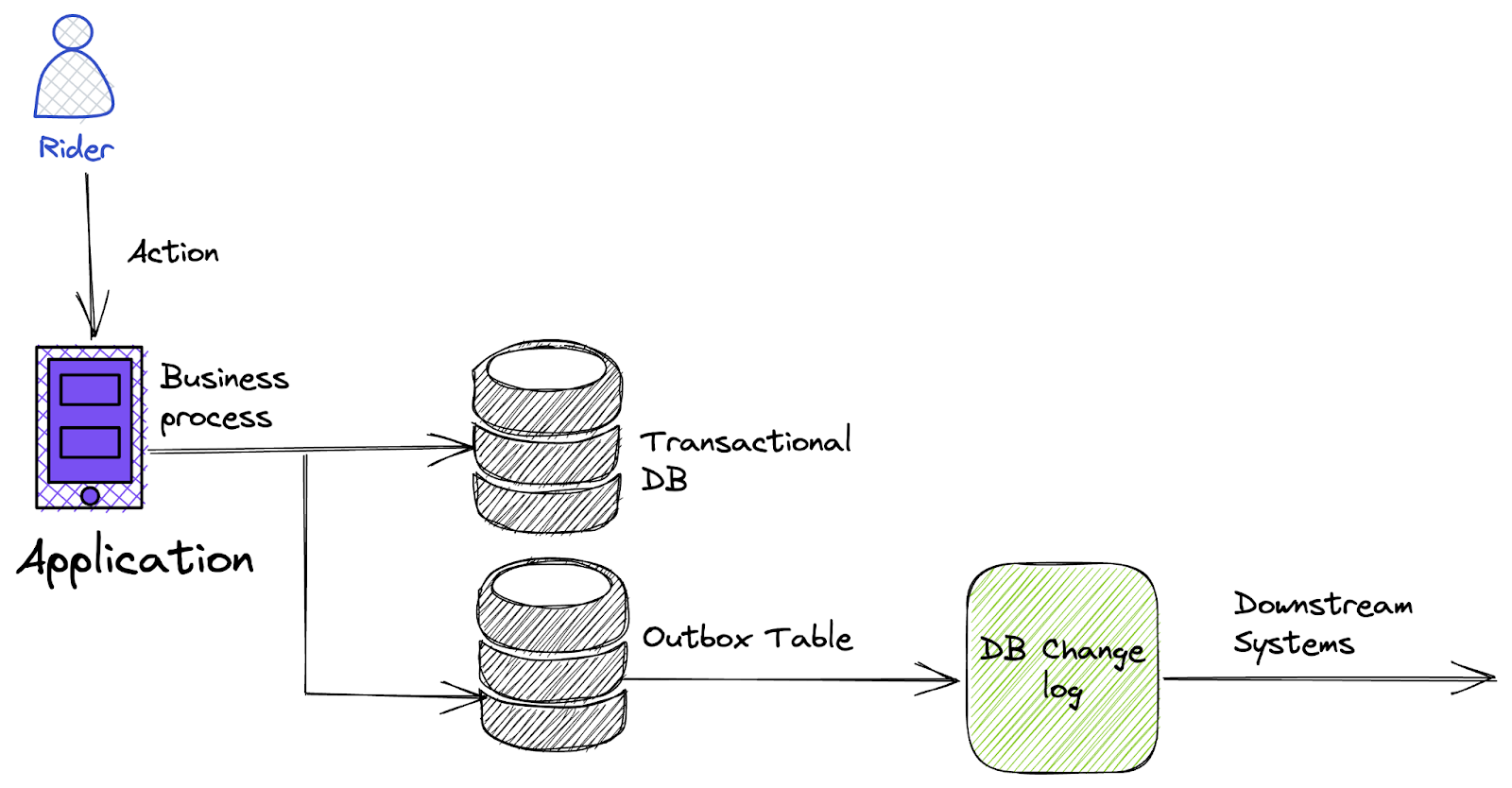
The outbox pattern also helps resolve the causal relationship of events. We can reuse the outbox table timestamp as the event timestamp. Hence any clock drifts in the source system that breaks the causal relationship in the event sourcing method can be averted using an outbox pattern.
A typical outbox table will look like the following.
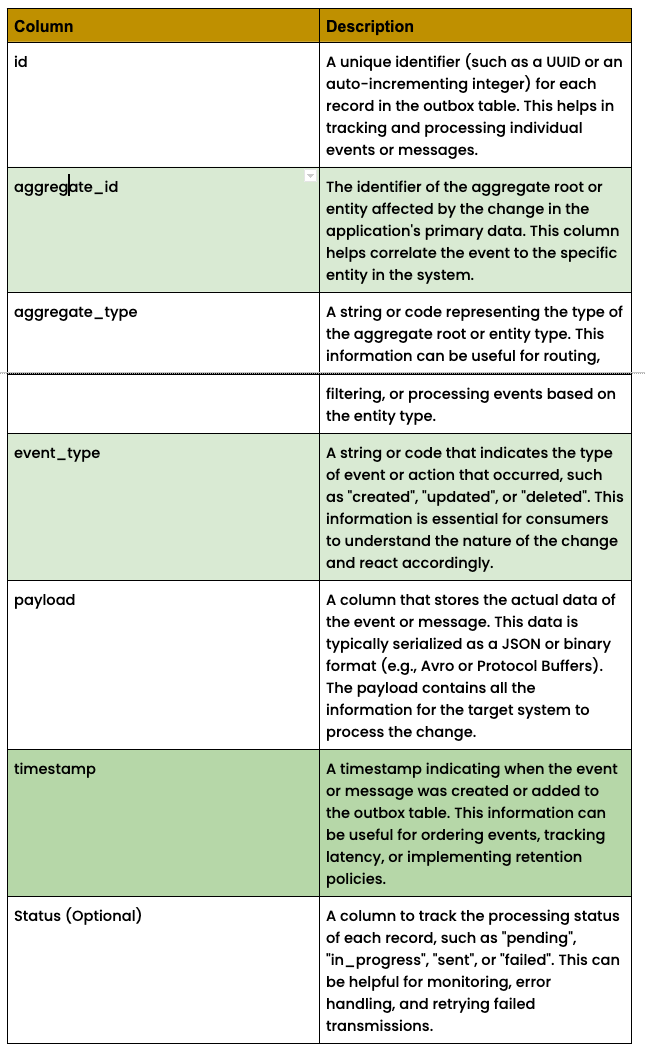
As with any other system, the outbox pattern has its problems too.
Drawback #1: Not Every Database Supports Transaction
The relational database support transaction for multiple mutation statements. However, if you use systems like DynamoDB, the transaction support falls under the application or the Data Access Layer. It is expensive to complex to maintain transaction support at the application level.
Drawback #2: Not Every Event Requires a Transactional Guarantee
cache invalidation; distributed financial transactions, search indexing, and similar application integration patterns require distributed transactional support.
In many cases, transactional support for analytical events may not be a higher priority since completing the business transaction is vital for an application.
Drawback #3: Outbox patterns still suffer from Unpredictable Quality of Events
All the issues we discussed regarding the unpredictable quality of events in the event sourcing pattern still apply to the outbox pattern.
Given the transactional guarantee depends on the operational data store, the outbox pattern can either support the transaction or not support the transactions. The outbox pattern without transaction support is almost equivalent to event sourcing systems.
A Schemata Approach to Data Creation - Modeling-First & Contract-Driven Approach
The fundamental question remains, what is the efficient strategy for event creation? Is it event sourcing or CDC, or outbox pattern?
Instead of thinking of the problem from the technology perspective, Let's think from the business impact perspective. I recently ran this poll to understand the prime pain point in the event sourcing technique.
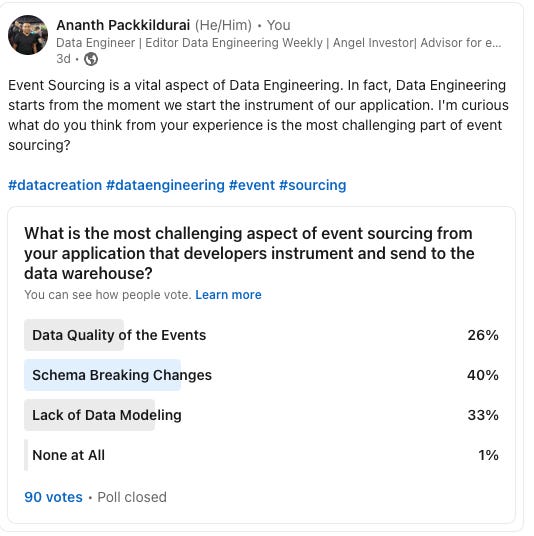
The data engineers say these are the prime concerns in the data creation process.
Lack of Data Modeling
Schema Breaking Changes
Data Quality
Schemata build from the ground as a data-modeling-first, data-contract-driven platform. Schemata enables domain-oriented data modeling techniques with a programmatic way to measure how interconnected your data model is.
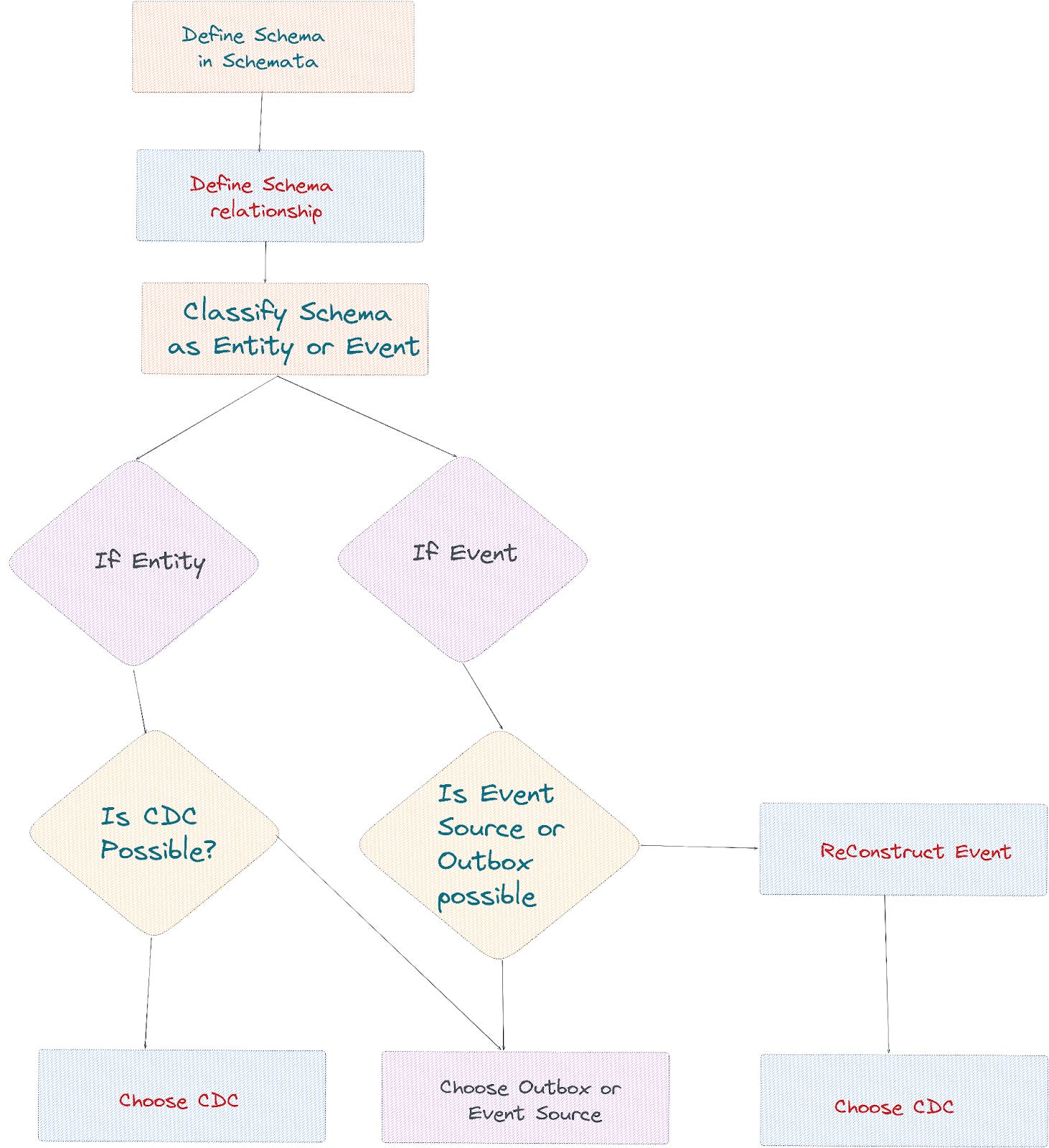
Schemata recommended Data Creation Process.
Schemata recommends adopting the combination of CDC + (Event Sourcing / Outbox Pattern).
Capturing Entities and their lifecycle events, such as new rider registration and address change, is easier to source from the CDC pipeline. An Entity change often happens in a single table of the operational system. So it is relatively simpler and reliable to source using the CDC pattern.
Complex business transactions, on the other hand, can impact multiple tables. Any recreation process from the CDC is expensive. Hence Schemata recommends either the Event Sourcing or the Outbox Pattern for creating events.
About Schemata
Schemata is a schema modeling framework for decentralized domain-driven ownership of data. Schemata combine a set of standard metadata definitions for each schema & data field and a scoring algorithm to provide a feedback loop on how efficient the data modeling of your data warehouse is.
You can find more information about it by visiting
In part 2, We will discuss data creation & the role of data quality. Until then, please share your thoughts in the comments about the Schemata approach to data creation.
Reference
Capturing Every Change From Shopify’s Sharded Monolith
https://shopify.engineering/capturing-every-change-shopify-sharded-monolith
Transactional Events Publishing At Brex
https://medium.com/brexeng/transactional-events-publishing-at-brex-66a5984f0726
Distributed Data for Microservices — Event Sourcing vs. Change Data Capture
https://debezium.io/blog/2020/02/10/event-sourcing-vs-cdc/
Introducing Schemata - A Decentralized Schema Modeling Framework For Modern Data Stack

Tulip: Schematizing Meta’s data platform
https://engineering.fb.com/2022/11/09/developer-tools/tulip-schematizing-metas-data-platform/
Using Log-Time Denormalization for Data Wrangling at Meta
Creating a React Analytics Logging Library
https://slack.engineering/creating-a-react-analytics-logging-library-2/
Pattern: Transactional outbox
https://microservices.io/patterns/data/transactional-outbox.html