
An Engineering Guide to Data Quality - A Data Contract Perspective - Part 2
An Engineering Guide to Data Quality - A Data Contract Perspective - Part 2
By Ananth Packkildurai

In the first part of this series, we talked about design patterns for data creation and the pros & cons of each system from the data contract perspective. In the second part, we will focus on architectural patterns to implement data quality from a data contract perspective.
Why is Data Quality Expensive?

I posted this LinkedIn post that sparked some exciting conversation. I won’t bore you with the importance of data quality in the blog. Instead, Let’s examine the current data pipeline architecture and ask why data quality is expensive.
Instead of looking at the implementation of the data quality frameworks, Let's examine the architectural patterns of the data pipeline. Those patterns will slowly reveal the answer to our burning question. But before doing that, let's revisit some of the basic theories of the data pipeline.
Theories of the Data Pipeline
1. Speed vs. Correctness vs. Time [SCT theorem]
Just like the CAP theorem, there's a balance to be struck between speed, correctness, and Time in a data pipeline. You can prioritize either speed or correctness, but not both simultaneously.
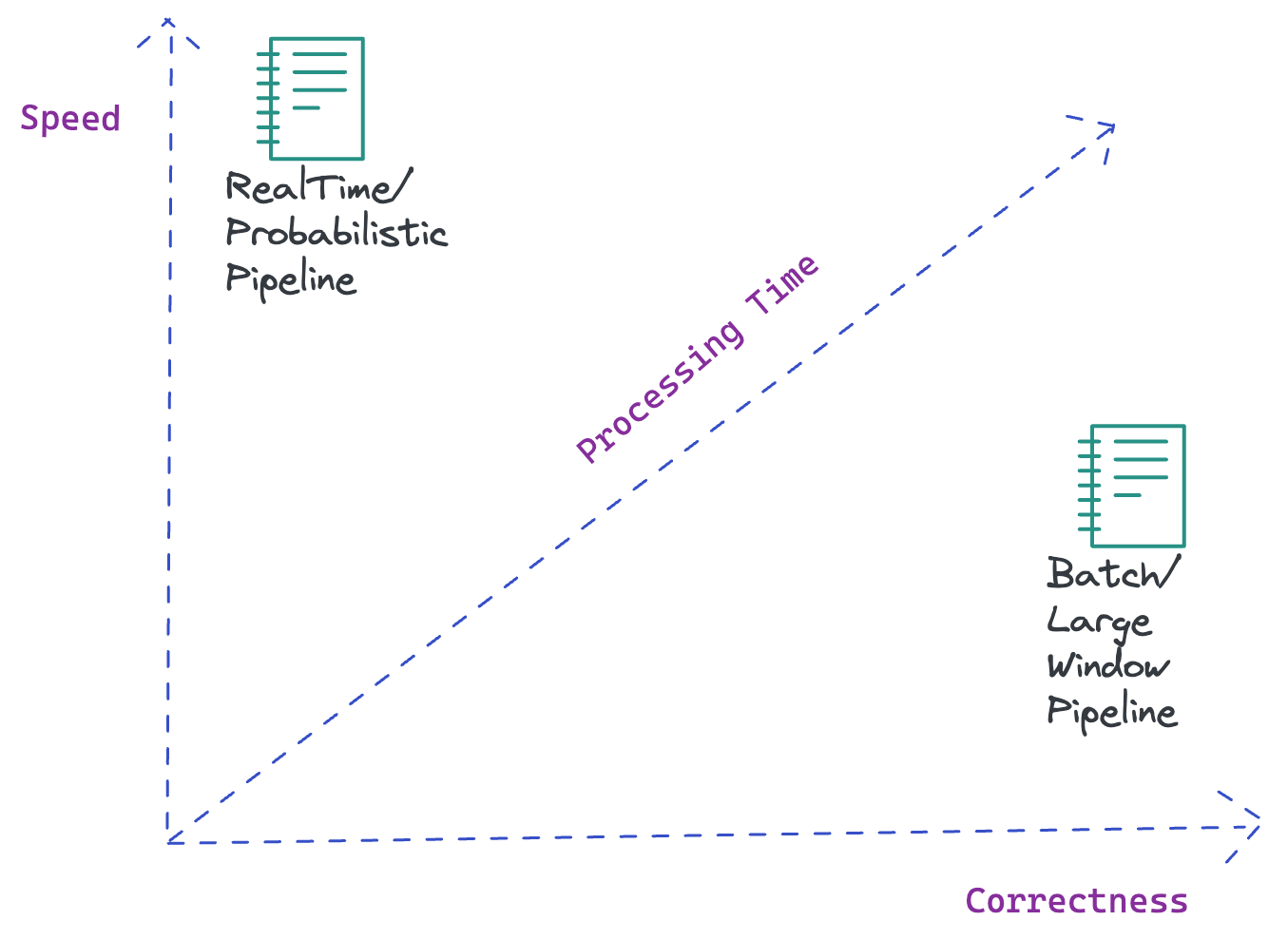
Why I’m making this claim? Ensuring correctness can slow down the pipeline. It involves thorough checks and balances, including data validation, error detection, and possibly manual review. The bias toward correctness will increase the processing time, which may not be feasible when speed is a priority.
2. Data Testing vs. Data Observability
Data testing and data observability are two important aspects of data quality. Data testing ensures that data meets specific requirements. Data observability monitors data to identify and troubleshoot issues.
Data testing and data observability are complementary approaches to data quality. Data testing helps to prevent problems from occurring, while data observability helps to identify and troubleshoot problems that do occur.

Architectural Patterns for Data Quality
Now we understand the trade-off between speed & correctness and the difference between data testing and observability. Let’s talk about the data processing types. The industry follows two categories of data processing techniques to handle the trade-off between speed and correctness.
Real-Time Data processing
Batch Data Processing
Though there are two categories of data processing techniques, they follow the same pattern for the data quality architecture. We call this pattern as WAP [Write-Audit-Publish] Pattern.
WAP [Write-Audit-Publish] Pattern

The WAP pattern follows a three-step process
Write Phase
The write phase results from a data ingestion or data transformation step. In the 'Write' stage, we capture the computed data in a log or a staging area.
Audit Phase
The 'Audit' phase follows, where we audit the data changes against specific rules or conditions. The audit process can include a variety of checks, such as schema compatibility, data constraints, and other forms of data contract.
Publish Phase
Publish is the final stage, assuming the Audit phase successfully evaluates the data contract. The system can fail or apply a circuit breaker in the pipeline if the data contract fails.
WAP Implementation Patterns
There are two types of WAP pattern implementation in the industry. Let’s dive into both architectural patterns and see how to adopt them in real-time and batch data processing.
Two-Phase WAP
The Two-Phase WAP, as the name suggests, follows two copy processes.
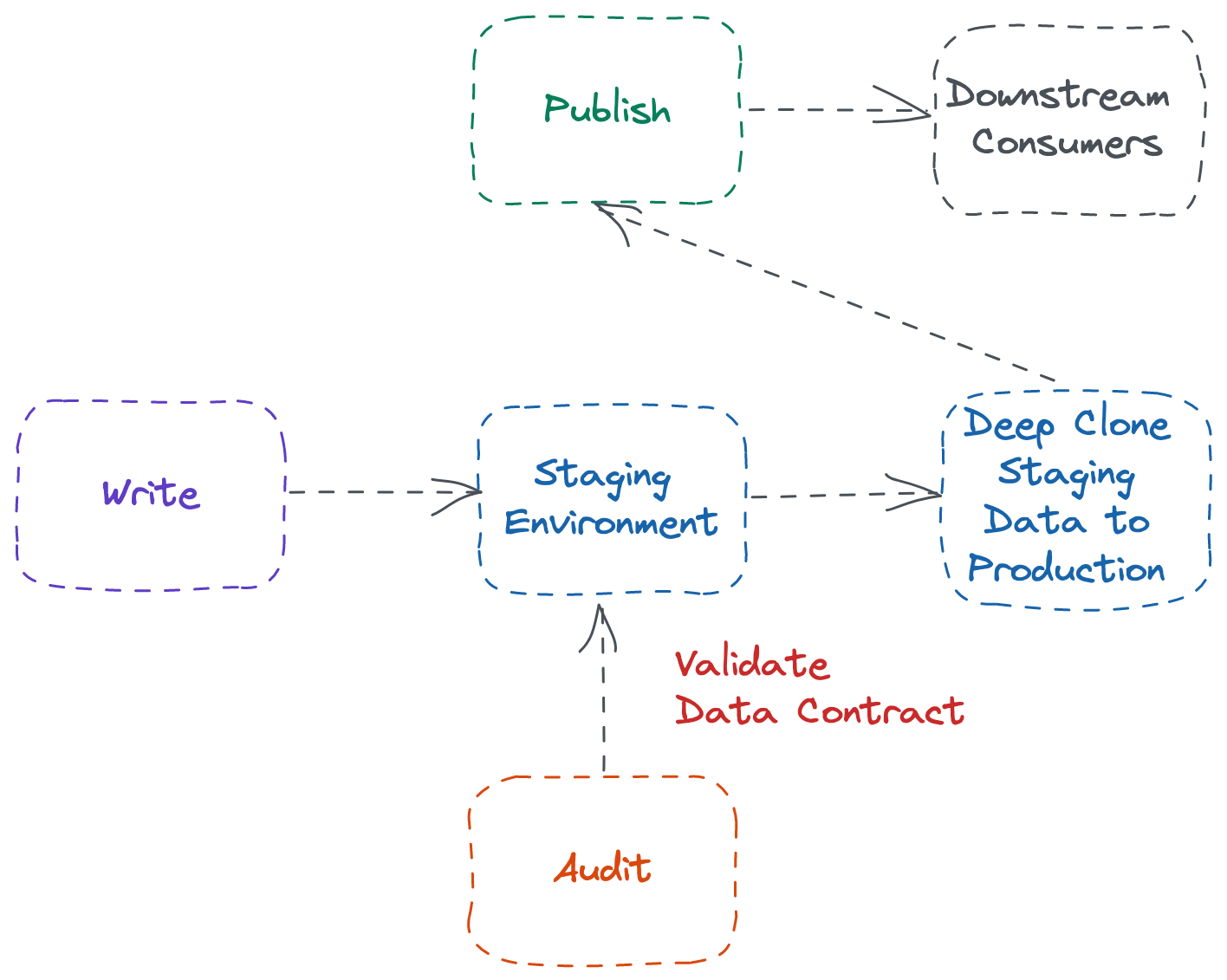
The Write phase writes the data into a staging environment.
The Audit step then kicks in, which runs through all the data contract checks.
If the Audit step succeeds, the data in the staging environment gets copied to the production. The staging environment then gets cleaned up as part of the pipeline or as a scheduled clean-up job.
Two-Phase WAP in Real-Time Data Processing
The Two-Phase WAP pattern follows the “Fronting Queue” pattern. Since Kafka is almost synonymous with real-time data processing, we often call this a “Fronting Kafka” pattern.
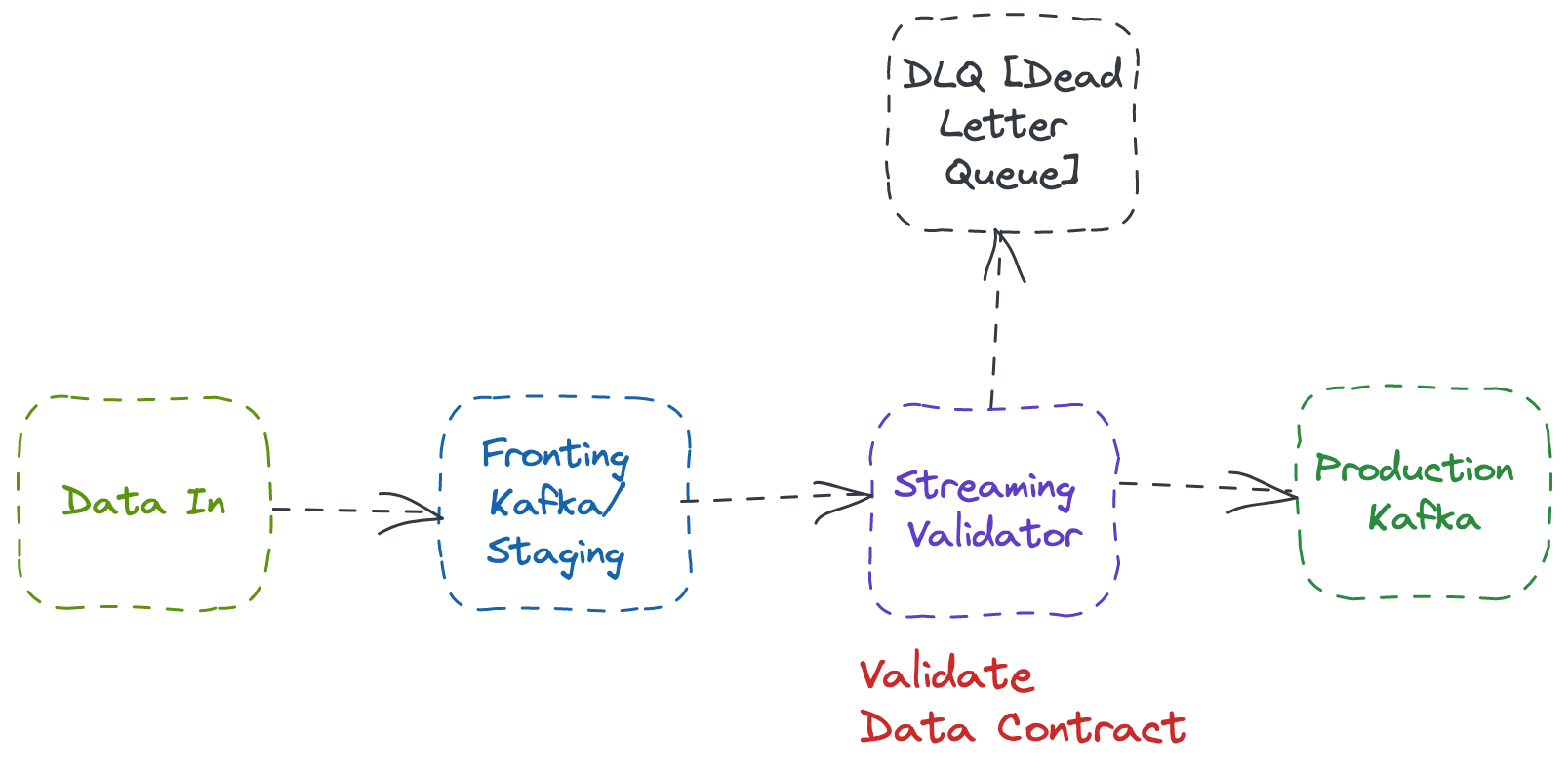
The Fronting Kafka pattern follows a two-cluster approach.
Like the staging environment, Fronting Kafka receives all the events without validation.
A streaming consumer, often implemented in stream processing frameworks like Flink or Spark, consumes the events from the fronting Kafka and runs through data contract validation.
Netflix’s Data Mesh is a classic example Two-Phase Fronting Kafka pattern implementation.
One-Phase WAP
The One-Phase WAP adopts a Zero-Copy data contract validation approach.
The One-Phase WAP is structurally similar to the Two-Phase WAP, except in the One-Phase WAP, there is no deep copy from staging to the production environment.
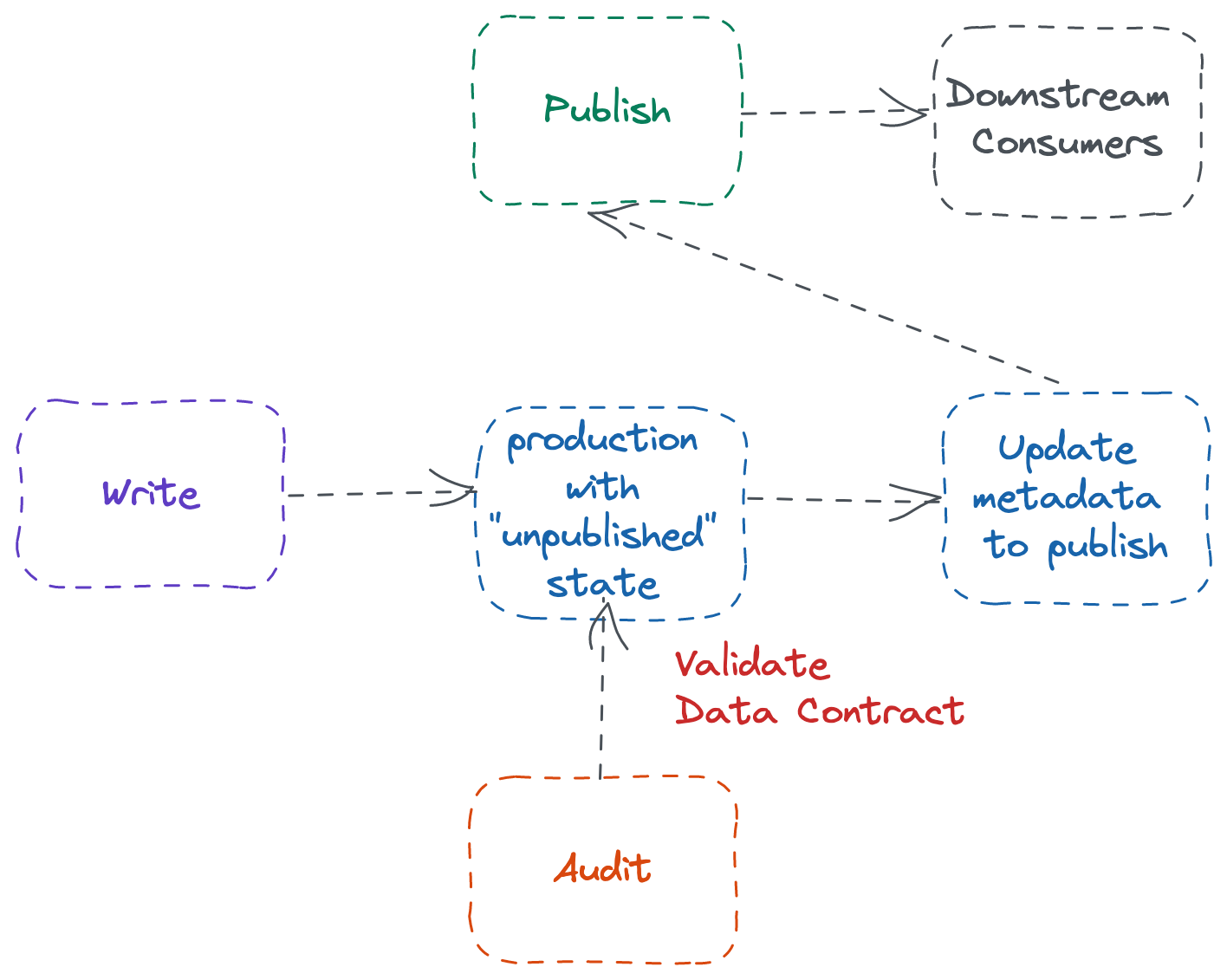
The modern LakeHouse format, such as Apache Iceberg & Apache Hudi, support a Zero-Copy WAP pattern implementation. In the Iceberg case, it is a simple two-step config change.
Set write.wap.enabled=true in the table
Set spark.wap.id=<UUID> in the Spark job
One-Phase WAP in Real-Time Data Processing
One-Phase WAP removes the need for an intermediate queue by adopting the event router pattern derived from the message router pattern.
The event routers typically follow a few characteristics
Event Routers can broadcast the same events from one-to-many destinations.
Event Routers typically don’t alter the payload.
Event Routers can add additional metadata to the envelope of the event.
Now, Why is Data Quality Expensive?
Data Quality is expensive because almost all the available data tools don’t support data quality as a first-class semantics, which leads to bespoke two-phase WAP pattern implementation.
If you look at the popular data transformation dbt, the model building lacks in-build one-phase WAP support. The same goes for the popular orchestration engine Airflow, where the Airflow has separate operators (SQLCheckOperators) for the data quality check. These design patterns lead to disjointed data quality tools that add more cost to the pipeline operation than solving the problem.
How to Fix It?
The steps dbt is taking to introduce data contract semantics are welcoming and positive progress. This is where the data processing engines and the data warehouse require more integration to minimize the data creation cost, enable fast backfilling, and promote the data quality as the first-class semantics in the data pipeline.
Should We Build a New Tool?
The batch data processing, we do have many mature tools. I think it is a question of improving the functionality of it.
However, on the real-time event routing side, I’m not convinced that we are there yet. There is not enough tool available to make the data creation process efficient.
So We decided to write one for event routing that can validate data contracts [schema & data quality], route the events to multiple destinations, and enable faster debugging. We code name it “Nobu,” and I can’t write more about Nobu in the last part of this series. Stay Tuned.
References
Yerachmiel Feltzman: Action-Position data quality assessment framework
Claus Herther: Blue-Green Data Warehouse Deployments (Write-Audit-Publish) with BigQuery and dbt
https://calogica.com/assets/wap_dbt_bigquery.pdf
Sandeep Uttamchandani: How we deal with Data Quality using Circuit Breakers
https://modern-cdo.medium.com/taming-data-quality-with-circuit-breakers-dbe550d3ca78
Netflix: Data Mesh — A Data Movement and Processing Platform at Netflix
https://netflixtechblog.com/data-mesh-a-data-movement-and-processing-platform-netflix-1288bcab2873
Netflix: Kafka Inside Keystone Pipeline
https://netflixtechblog.com/kafka-inside-keystone-pipeline-dd5aeabaf6bb
Netflix: Evolution of the Netflix Data Pipeline
https://netflixtechblog.com/evolution-of-the-netflix-data-pipeline-da246ca36905
Enterprise Integration Pattern: Message Router
https://www.enterpriseintegrationpatterns.com/patterns/messaging/MessageRouter.html
This article is awesome. How you put in words the difference between testing and observability, and the details of the patterns is just amazing. Thanks!