


Data Catalog - A Broken Promise
A critique on Data Catalog, and the future of knowledge management

Data catalogs are the most expensive data integration systems you never intended to build. Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern data workflow, not just adding “modern” in its prefix.
I know that is an expensive statement to make😊 To be fair, I’m a big fan of data catalogs, or metadata management, to be precise. I even authored a special edition capturing metadata tool’s history at Data Engineering Weekly.

What changed my thoughts on Data Catalog?
After overseeing a couple of data catalog implementations in recent times, it made me pause and started to question my belief. The question is essentially two-fold.
Why is it so expensive in terms of the level of effort to roll out a data catalog solution?
Despite the initial energy from the stakeholders, why does the usage of Data Catalogs keep declining?
Is that the experience unique to me? So I seek data community thoughts about Data Catalog in a poll on LinkedIn.
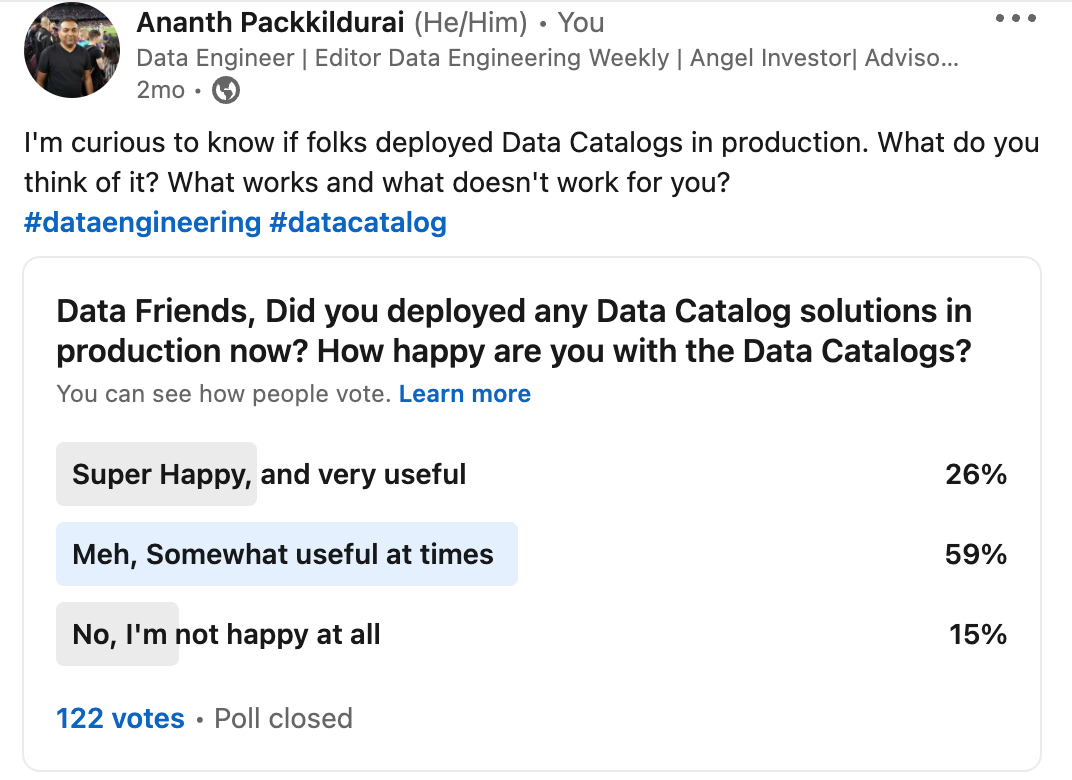
If you discount a few data catalog vendor votes from the poll, 26% shrinks to 20%. So it’s not me; 80% of people think Data Catalog is not a prime-time data workflow system but a handy tool that is sometimes somewhat useful.
The result reaffirms my experience with the Data Catalog, and also it triggers more curiosity in me to understand why so? To understand better, Let’s step back and examine the data catalog of pre-modern-era and modern-era1 Data Engineering.
The pre-modern(?) era of Data Catalog
Let’s call the pre-modern era; as the state of Data Warehouses before the explosion of big data and subsequent cloud data warehouse adoption. Applications deployed in a large monolithic web server with all the data warehouse changes go through a central data architecture team.
A couple of important characteristics of a Data Warehouse at this time
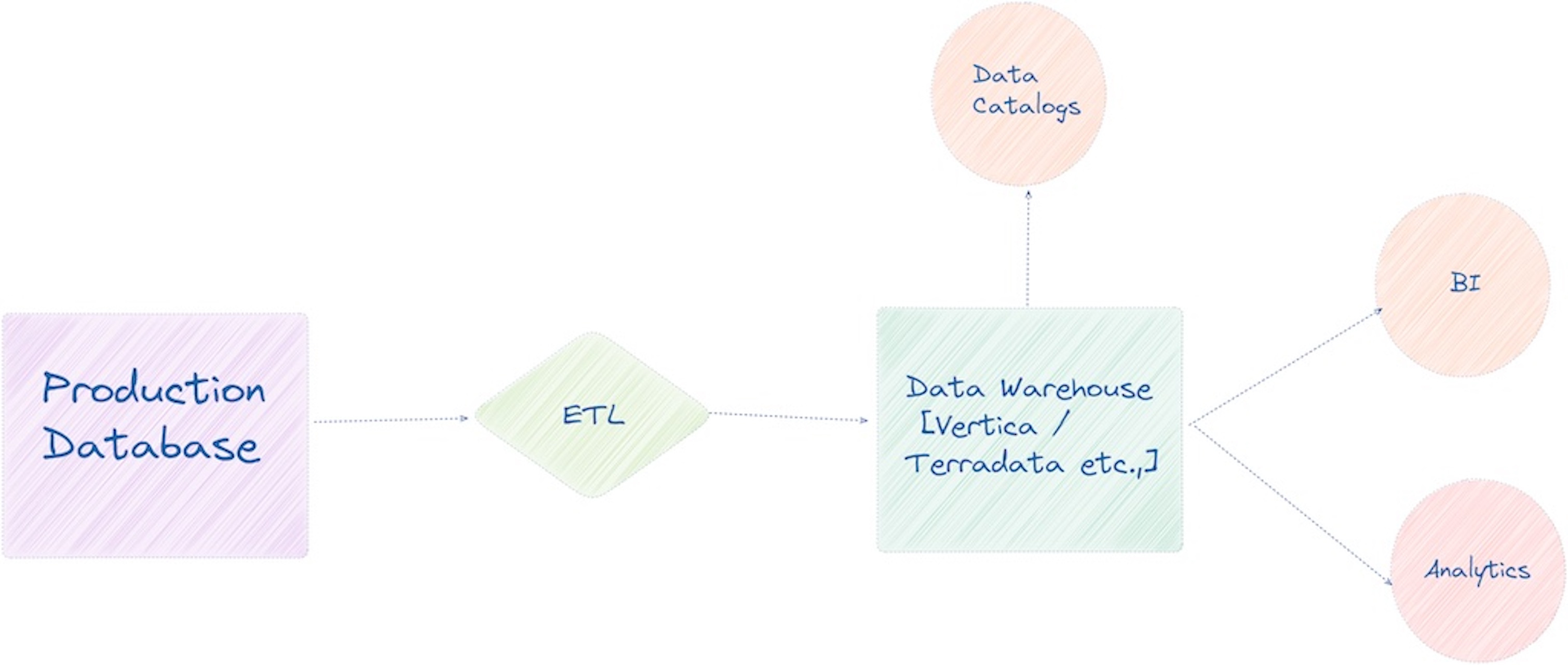
The ETL tools and Data Warehouse appliances are limited in scope. There are not many sources to pull the metadata.
The footprint of people in an organization directly accessing the Data Warehouse is fairly limited; getting access to query the Data Warehouse directly is a privilege and a specialized skill.
The modern(?) era of Data Catalog
Hadoop significantly reduced the barrier to storing and accessing large volumes of data. The cloud Data Warehouses & LakeHouse systems further accelerate the ease of access to the data. It also opens up data for multiple use cases such as A/B testing2, AI/ML3, Growth Engineering4, and Data-Driven product features5, etc.,
All combined, two important characteristics changed in the modern data infrastructure.
Data Warehouses now ingest data from multiple data sources6, which was not possible before, giving unprecedented insights.
The ease of access and multiple use cases expose data warehouses to multiple organizational stakeholders and specialized tools to get the job done.
At a high level, we can define modern data engineering as Fn(work) in your favorite tool.

What does that mean? Let’s expand a bit more to demonstrate the current state of the data catalog with the modern data stack.

As you can see, We still adopt the age-old metadata integration strategy to build data catalogs. It makes rolling out the data catalogs.
Expensive and time-consuming
It creates a disjointed workflow which makes folks rarely use the tool
Is Data Catalog a 1980s Solution for 2020’s Problems?
Anthony Algmin writes an interesting perspective reflecting many of the things we sketched in the article with a title, Make An Impact: The Data Catalog is a 1980s Solution for 2020’s Problems. The author nailed the fundamental problem with the Data catalog.
“There’s a bigger problem (*with Data Catalogs). It is that we now need to make potential data catalog users aware that the data catalog exists and then train them how to use it! A system that neither creates the data nor does the analysis—not exactly what most sane people want to spend a lot of time learning. A big strike two!”
The author proposes two ways the Data Catalog can evolve further.
Lose the Interface and embedded into the data creation tools
Expand from Data Catalog to Knowledge Engine - Aka not just a passive web portal, but integrate into the data creation process, aka Data Contract platform.
Conclusion
I don’t think data catalogs are going away soon, but the data catalog tools should acknowledge the underlying system dynamics changes. We can’t design a system that works for 20-year-old infrastructure.
What do you all think about the future of Data Catalogs? I look forward to your comments.
References

https://vwo.com/blog/cro-best-practices-booking/
https://research.netflix.com/research-area/recommendations
https://engineering.gusto.com/what-is-growth-engineering/
https://slack.engineering/recommend-api/
https://airbyte.com/connectors
Ananth, very nicely written article. Data catalog / hub (whatever name we give) is always a gigantic data integration effort. In my opinion, even pre-modern era was no different. There were too metadata producers.
When I initiated WhereHows project project in 2013 at LinkedIn, we had at least 3 orchestration engines - Azkaban, Appworx (UC4) & Informatica. Then data moved through HDFS into MPP database with some of the heavy lifting ETL happening in Java map-reduce, Pig and finally Teradata SQL (final aggregation) ending up with reports using MicroStrategy and Tableau.
I give the example of Google Map - it is a wonderful application not just because it helps me to get from a source (one data entity) to a destination (another data entity) but can superimpose nearby coffee shops with ratings when I need to wait somewhere. Often bare backbone data lineage may not be able to answer all questions. What I noticed at LinkedIn, data lineage mashed with process lineage (which pipelines / tasks where involved in the transformations, pattern of data volume that they carry everyday) provide interesting insights for support, operational excellence, initial troubleshooting etc
We kept extending this notion to source code repository because we needed to know the code owners, who made latest changes etc. To complicate the scenario, some metadata producers like UC4, Informatica were very proprietary in nature - so yes, it was a very large, complex and fragile data integration project and we needed to remember breakage anywhere would make the lineage graph unusable.
I like Kendall Willets' comment "the data catalog brings out the inner bureaucrat in all of us"... A data catalog can no longer just be internal wikidata (although documentation is still an important aspect of data governance)... I am co-founder of DAWIZZ, a company that publishes 'MyDataCatalogue' a data catalog which finally after 6 years has become more of a data discovery platform in structured data sources (databases, APIs, . . .) and in unstructured data sources (files, messaging, . . .). We usually say that we create additional metadata from the data itself