
Data Engineering in Retrospect: Key Trends and Patterns of 2023
Analyzing the Evolution and Breakthroughs in Data Engineering Throughout 2023

Wow, can you believe it's almost time to wave goodbye 👋 to 2023? This year still feels like a fresh newbie, especially since we just bounced back from the pandemic rollercoaster 🎢 of last year. The past few months have been a bit of a health hiccup for me 🤒, but hey, I'm all smiles 😊 about how things are turning out.
It’s the end of the year, and there will be a lot of buzz about what the next five years in data engineering might bring. But here's a thought - why not look back to uncover the patterns? 🤔 Reflecting on the past is crucial; it gives us a solid foundation to understand how trends have evolved and what's worked (or not). It's like piecing together a puzzle from history to get a clearer picture of the future. So, instead of guessing what's ahead, let's explore the past and those patterns. Who knows what insights we might uncover? 🕵️♂️📈
Before we delve into the patterns, it's important to remember that data infrastructure maturity model.
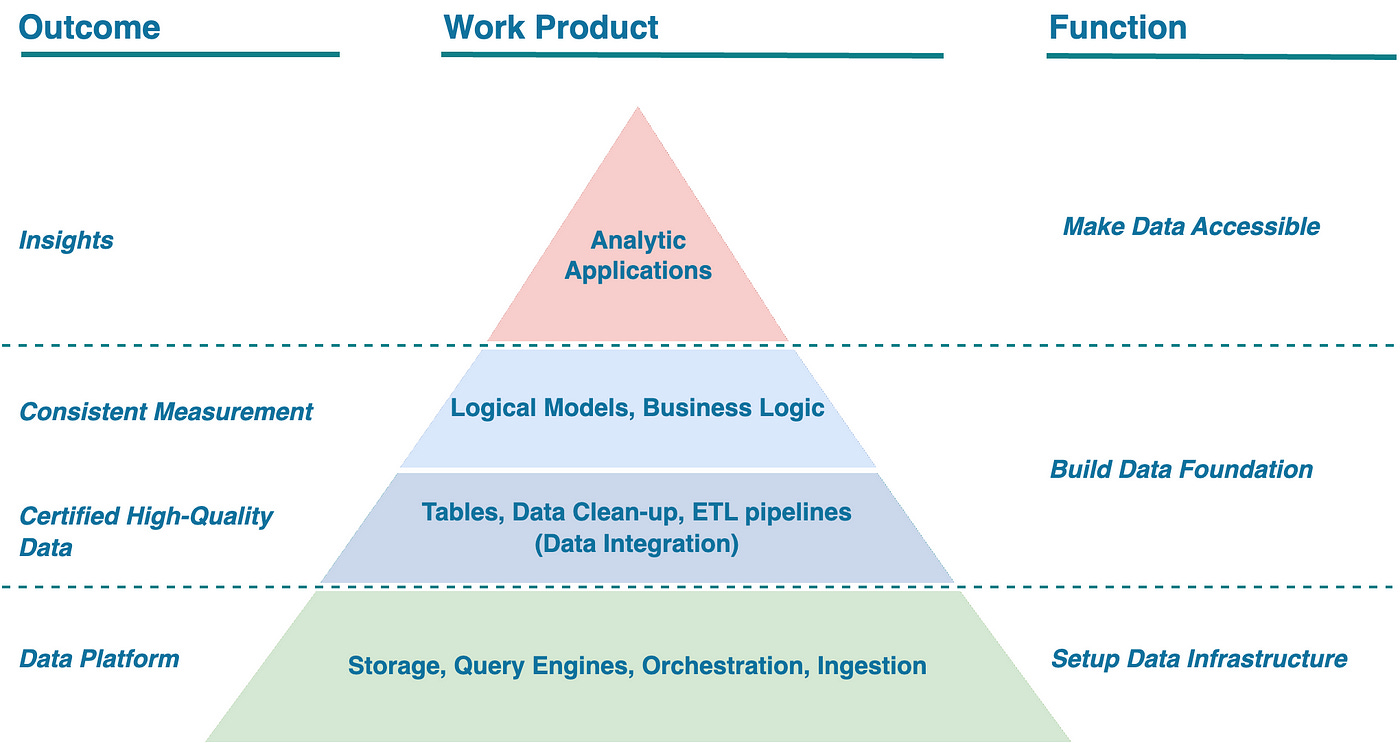
Companies are at various stages of this model, which means certain patterns and predictions may align with your organization's maturity level while others might not. It's essential to consider your specific context and not follow trends and buzzwords unthinkingly. Remember this as we explore these patterns to make the most informed decisions for your situation.
1. Revolution in AI: Large Language Models Take the World by Storm
I’m not certainly talking about OpenAI boardroom drama. LLM is indeed starting to make an impact on the way we work. We saw a fleet of announcements from Data Catalogs tools on how LLM can help to auto-generate documentation [See: How Generative AI Is Making Data Catalogs Smarter]. We’ve seen a fleet of tools like TextToSQL; Slack bots to ask questions to your data warehouse, Chat interface for spreadsheets, and even the English SDK for Spark!

I believe the impact of LLM will go further down in the stack with data storage formats in the coming years. Let me know your thoughts in the comments.
2. The Battle for Supremacy: Inside the Fierce Lakehouse Architecture War
One of the hot topics in the data industry is which LakeHouse format to choose. The data industry clearly understands the power of blob storage, and using S3 as a database is not a new concept either. We saw back-to-back articles comparing the features and the performance of Delta Lake, Apache Hudi, and Iceberg. Companies started to invest in either format. The companies backing Apache Hudi and Iceberg write articles about comparative ACID support in both the platforms here and here. There are attempts to bring interoperability among the LakeHouse format, such as OneTable.
I believe capturing the mindshare of the file format is vital for any of these companies. Once captured, there are a lot of market opportunities to move up the stack with Data Catalog, Data Governance, and Data Quality. Databricks is already doing a lot of these move-up stack products. However, I do believe there is tons of innovation left in the deep engineering of LakeHouse, such as

In a way, you can think of DuckDB-like systems as a feature of LakeHouse rather than a separate product.
3. Bundling vs. Unbundling: The Rise and Fall in the Modern Data Stack
Bundling vs. UnBundling is one of the hotly debated topics in 2023. There were many comparisons of the Modern Data Stack (MDS) as the follower of Unix Philosophy. But I had my doubts.

As Benn Stancil noted in his blog, “The data industry is going to consolidate” is a pretty boring prediction to make these days.

The categories are merging. Data Catalogs, for instance, step into Data Quality & Data Observability. Data Catalogs is no longer a standalone category. Databricks announced a fleet of features for catalogs, governance, observability, and orchestration. Microsoft is entering into the integrated infrastructure with Fabric. Unless the Fed reduces the interest rate to zero, the unified platform is the trend for foreseeing.
4. Shifting Focus: Embracing Cost Optimization as a Priority
In 2023, we have seen companies shifting their focus to cost optimization; data infrastructure is the center of cost optimization. The Instacart S1 filling set the data industry a hot debate on Snowflake billing, known as Snowflake Tax.
I also noticed a common pattern where many companies write about their migration journey from Redshift. It is Databricks vs. Snowflake, where both companies ran their data conference on the same day.

The Modern Data Stack categories certainly fall in with the cost sensitivity of the companies. You have a $1M budget; $700K goes to data warehouses such as Databricks or Snowflake. All the modern data stack companies are fighting for the remaining budget, which puts them a commodity product to sell. The cost of integrating the Modern Data Stack is also pretty high. The cost sensitivity in the market and the rise of integrated solutions like Databricks and Microsoft are where the companies will go in 2024. The sequence of Redshift migration is one part of it.
5. Apache Flink Triumphs: The Undisputed Leader in Streaming Wars
We can safely say that in 2023, Flink will be the undisputed leader in streaming frameworks. It is one of the less tracked patterns, but if you noticed deeply, a fleet of companies are offering “Flink as a Service.” Confluent, the company behind Kafka, Kafka Stream, and KSQL, launched Flink as a Service on its cloud product.
However, I believe there is tons of innovation left on the streaming side of it. It is still operationally expensive, and the feature parity with batch analytics is not there yet. LinkedIn is trying to bridge the gap with the Apache Beam adapter for streaming and the batch layer.

We will continue seeing innovation in streaming in the coming days. One of the engines I’m excited to watch is an alternative to Apache Spark. Snowflake recently acquired Ponder to bring some alternatives to Apache Spark. 2024 will be an exciting year, and I look forward to watching how it shapes together.
These are some of the patterns I thought of. Please leave comments on the trends you’ve noticed in 2023. Let’s chat.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.