
Data Engineering Weekly #105
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack provides data pipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
Editor’s Note: The current state of the Data Catalog
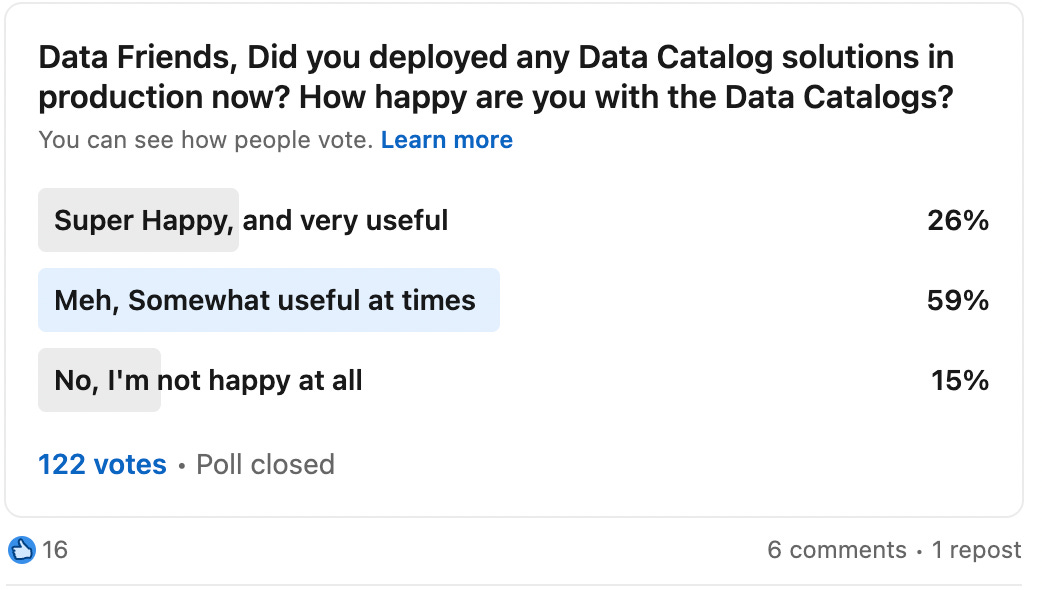
The results are out for our poll on the current state of the Data Catalogs. The highlights are that 59% of folks think data catalogs are sometimes helpful. It means Data Catalogs still not find their place in the data workflow, where 15% of folks are unsatisfied with them. Only 1/4th of the people are happy with the data catalogs [well, 20% of the responders are the data catalog vendors, so]
In the coming weeks, I will reach the responders to gain more insights and share more as I learn. Thank you to everyone who participated in the poll.
Luis Velasco: Data Contracts - The Mesh Glue
I'm excited about the Schemata & Data contract because it perfectly stitches catalogs, data quality, and glossary. The current state of these systems is inherently passive systems. We saw in the Data Catalog poll how far it has to go to be helpful and active within a data workflow.
The author narrates the data contract, why it is the foundation for building data mesh, and how it glue data catalogs, glossary and data quality systems.
https://towardsdatascience.com/data-contracts-the-mesh-glue-c1b533e2a664
Tomasz Tunguz: 9 Predictions for data in 2023
It is almost the end of 2022, and it's time for 2023 predictions. I found the nine predictions exciting and spot on in most cases. My thoughts,
I'm 100% on WASM or similar technology becoming an integral part of the data ecosystem.
I'm a bit skeptical about #5, where Notebook capture Excel. It is reciprocal of the other two predictions where in-memory & WASM are gaining popularity. I expect spreadsheets to gain more adoption with these advancements than Notebooks.
There is no mention of data management in general, but mainly of usage and operational factors. Nothing groundbreaking will happen on data management in 2023, but I expect a little momentum behind data management towards the end.
https://pitch.com/public/1115d675-9e2e-4c03-ab3c-aa91fb0bf4be/d6c34fc4-d7c7-40b8-837d-e09c9c6e187f
Iris Sun: Anything and Everything about Generative Models
The generative AI is on everyone’s lips. In the past few years, the power of the foundation model has stretched our imagination of what is possible: the model can be trained on a surrogate task and later apply the learned knowledge from that task to many other downstream tasks. I found the blog helpful in understanding the generative model’s historical development and the path forward.
https://irissun.substack.com/p/anything-and-everything-about-generative
Sponsored- [New eBook] The Ultimate Data Observability Platform Evaluation Guide
Considering investing in a data quality solution? Before you add another tool to your data stack, check out our latest guide for 10 things to consider when evaluating data observability platforms, including scalability, time to value, and ease of setup.
Access You Free Copy for Data Engineering Weekly Readers
LinkedIn: Super Tables - The road to building reliable and discoverable data products
The self-service is not free and brings challenges, as the LinkedIn data team narrates.
1) multiple similar datasets often led to inconsistent results and wasted resources,
2) a lack of standards in data quality and reliability made it hard to find a trustworthy dataset among the long list of potential matches, and
3) complex and unnecessary dependencies among datasets led to poor and difficult maintainability.
LinkedIn writes about how it builds “Super Tables” [Is that another name for the semantic layer?] to solve some of the challenges with self-serving.
Dagster: Build a poor man’s data lake from scratch with DuckDB
The value of the data is directly proportional to the recency of the data. Can we use an in-memory database to increase the speed and the value generation? DuckDB is gaining much attention on this promise, and the Dagster team writes about its experimental data warehouse built on top of DuckDB, Parquet, and Dagster.
https://dagster.io/blog/duckdb-data-lake
Sponsored: Why You Should Care About Dimensional Data Modeling
It's easy to overlook all of the magic that happens inside the data warehouse. Here, Brian Lu details the core concepts of dimensional data modeling to give us a better appreciation of all the work that goes on beneath the surface. He covers the speed vs. granularity tradeoff, highlighting the denormalized table and why it's today's technique of choice, and he clarifies how to think about the benefits of immutability.
Sarah Krasnik: The Analytics Requirements Document
The first critical step to bringing data-driven culture into an organization is to embed the data collection and analytical requirement part of the product development workflow. The author narrates how the analytical requirement document can help to define a better data strategy.
https://sarahsnewsletter.substack.com/p/the-analytics-requirements-document
Deezer: How Deezer built an emotional AI
Deezer writes about Flow moods, an emotional jukebox recommending personalized music at scale. The approach to learning the presence of certain types of instruments, the choice of tempo, complex harmonies, and loudness to construct a song's musical mood is an exciting read.
https://deezer.io/how-deezer-built-the-first-emotional-ai-a2ad1ffc7294
Expedia: Categorising Customer Feedback Using Unsupervised Learning
Expedia writes about its approach to categorizing customer feedback using unsupervised learning. Part of me wonders, shouldn’t it be a solved problem where the cloud providers can give these solutions out-of-the-box?
ABN AMRO: Building a scalable metadata-driven data ingestion framework
Data ingestion is a heterogenous system with multiple sources with its data format, scheduling & data validation requirements. The modern data stack is trying to address this problem in a silo; the org eventually has to tie everything to make it work. ABN AMRO shares its case study on how it built a metadata-driven data ingestion platform to preserve lineage, quality, and scheduling.
Bart Maertens: A new Execution Information Logging Platform in Apache Hop
Profiling and auditing the workflow is essential for operating the data pipeline at scale. In the past, I try to use the "airflow.log" table and the "profiling" feature to achieve the same. Surprisingly, the Airflow profile and the logs table are not widely popular. I'm excited to see Apache Hop added it as an integrated feature with the information logging framework.
https://bartmaertens.medium.com/a-new-execution-information-logging-in-apache-hop-92534f8a306c
Anton Bryzgalov: How to Export a Full History of Ethereum Blockchain to S3
How to think about starting Ethereum blockchain analytics? The author explains how to dump the history of blockchains into S3. Til about https://github.com/blockchain-etl/ethereum-etl.
Thank you, Anton Bryzgalov, for contributing the blog to the Data Engineering Weekly.
https://betterprogramming.pub/how-to-dump-full-ethereum-history-to-s3-296fb3ad175
Please find the instruction here if any of our readers would like to contribute to DEW.
https://github.com/ananthdurai/dataengineeringweekly#how-can-i-contribute-articles
Tom Klimovski: Serving dbt docs on Gitlab (Static) Pages
Simplicity is the art of excellent engineering. The title is self-explanatory about what it is doing, and I found this exciting hack. Kudos to Tom Klimovski.
https://medium.com/@tom.klimovski_90944/serving-dbt-docs-on-gitlab-static-pages-3365416c8b22
All rights reserved Pixel Impex Inc, India. Links are provided for informational purposes and do not imply endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.