
Data Engineering Weekly #112
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack provides data pipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
McKinsey: The state of AI in 2022—and a half decade in review
McKinsey publishes the state of AI in 2022 with the last five years’ review. A few highlights
63 percent of respondents say they expect their organizations’ investments to increase in AI over the next three years.
Today, the biggest reported revenue effects are found in marketing and sales, product and service development, and strategy and corporate finance, and respondents report the highest cost benefits from AI in supply chain management
The tech talent shortage shows no sign of easing, threatening to slow that shift for some companies. A majority of respondents report difficulty in hiring for each AI-related role in the past year, and most say it either wasn’t any easier or was more difficult to acquire this talent than in years past
Jacob Matson: Modern Data Stack in a Box with DuckDB
One important characteristic of the data infrastructure is that the more recent the data more frequent the access. Given the characteristic, are we having a “Big Data” problem? Can we spin off a machine with all the data stack and run through the analysis? The author writes an exciting blog, Modern data stack in a Box!!
https://duckdb.org/2022/10/12/modern-data-stack-in-a-box.html
Data Engineering Central: Why is everyone trying to kill Airflow?
Airflow is probably one of the Top 5 breakthrough data technology in the last ten years. The author narrates the competitive landscape in the orchestration engine today by comparing some of the pros and cons of Airflow as its stands today.
https://dataengineeringcentral.substack.com/p/why-is-everyone-trying-to-kill-airflow
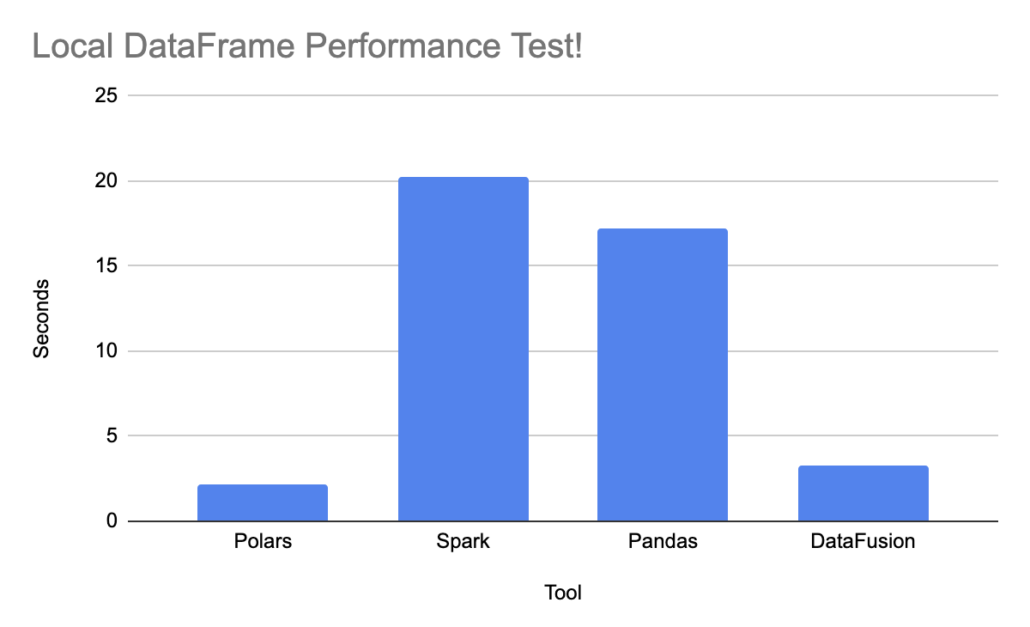
Confessions of a Data Guy: Dataframe Showdown – Polars vs. Spark vs. Pandas vs. DataFusion. Guess who wins?
Dataframe is mainstream data abstraction now, and as the popularity increases, the innovation around the tools to run efficiently increases. Looking at the test results, Polars implementation performs much better than Apache Spark.
Sponsored: Upsolver - Write a SQL Query, Get a Data-in-Motion Pipeline!
Pipelines for data in motion can quickly turn into DAG hell. Upsolver SQLake lets you process fast-moving data by simply writing a SQL query.
Streaming plus batch unified in a single platform.
Stateful processing at scale - joins, aggregations, upserts
Orchestration auto-generated from the data and SQL
Templates with sample data for Kafka/Kinesis/S3 sources -> S3/Athena/Snowflake/Redshift
Wayve: Wayve's End-to-End Deep Learning Model for Self-Driving Cars
Wayve, the autonomous driving technology based on computer vision and machine learning, writes about its end-to-end deep learning model for self-driving cars. I found the tech forum from Scale AI very informative about the various approaches in self-driving car efforts.
https://www.infoq.com/news/2022/12/wayve-deep-learning-model/
Percona: JSON and Relational Databases – Part One
Whether we like it or not, most data engineering and modeling challenges will be handling semi-structured data in the coming years.
SaaS companies like Salesforce and Zendesk are increasingly processing and emitting sem-structure data. We have already seen systems like Apache Pinot; Apache Druid improves their JSON support. The Percona blog walkthrough JSON support in the relational databases.
https://www.percona.com/blog/json-and-relational-databases-part-one/
Sponsored: Monte Carlo - [New Guide] Data Pipeline Monitoring 101
Minimize data downtime, and maximize data trust. As data becomes increasingly important to modern companies, it’s crucial for it to be trusted and accessible. Learn how to stop missing incidents and spending precious engineering hours maintaining static tests and learn how data pipeline monitoring can help take your team to the next level by accessing this new "Data Pipeline Monitoring 10" guide.
Etsy: Mitigating the winner’s curse in online experiments
I enjoy reading Etsy blogs about A/B testing, TIL about the winner’s curse in the experimentation, and the blog narrates how Etsy approaches to mitigate the winner’s curse.
https://www.etsy.com/codeascraft/mitigating-the-winners-curse-in-online-experiments
Neil Raden: We need a real semantic layer - but something is missing
Will the semantic layer induce more challenges than the problem it solves? The author explains the problem with customer mapping. Who is a customer? The question remains the same but will have a different answer from marketing, sales, and products. The author gives a fresh perspective to the semantic layer!!
https://diginomica.com/we-need-real-semantic-layer-something-missing
Sponsored: Take Control of Your Customer Data With RudderStack
Legacy CDPs charge you a premium to keep your data in a black box. RudderStack builds your CDP on top of your data warehouse, giving you a more secure and cost-effective solution. Plus, it gives you more technical controls, so you can fully unlock the power of your customer data.
Take control of your customer data today.
Motherbrain: Disrupting private capital using machine learning and an event-driven architecture
The blog is an exciting one giving a peak into the private capital ventures approach to finding startup investment strategy. The blog doesn’t leave any traces of the data sources they consume, but curious
What are the data sources the private venture capital firms depend on? Let me know in the comments or DM me on LinkedIn
Monzo: Building an extension framework for dbt
Possibly one of the most brilliant pieces of engineering I read this year
Kudos to the Monzo data team. The blog narrates bringing a platform approach to dbt, lessons learned, tracking back, and pragmatic hacking into dbt core to build the extension framework; A great joy to read.
I hope we will see dbt-core support the extension framework out of the box
https://monzo.com/blog/2022/12/15/building-an-extension-framework-for-dbt.
Shopify: 3 (More) Tips for Optimizing Apache Flink Applications
Shopify writes three more practical tips for optimizing Apache Flink. TIL about the Hybrid Source support from Apache Flink and the role in Backfilling. I recently had to design for a similar problem and vaguely arrived at a similar strategy, but I thought it might be complicated. Seeing Shopify implement it gives much hope to explore the option further. Thank you, Shopify data team.
https://shopifyengineering.myshopify.com/blogs/engineering/optimizing-apache-flink-tips-part-two
First part: https://shopify.engineering/optimizing-apache-flink-applications-tips
Microsoft: Search and ranking for information retrieval (IR)
The blog is a good summarization of the searching and ranking problem domain. The author narrates techniques to adopt finding the best matching document [search] and order them [rank]. TIL about Pointwise, Pairwise, and Listwise learning methods.
All rights reserved ProtoGrowth Inc, India. Links are provided for informational purposes and do not imply endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.