


Data Engineering Weekly #130
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack provides data pipelines that make collecting data from every application, website, and SaaS platform easy, then activating it in your warehouse and business tools. Sign up free to test out the tool today.
Editor’s Note: Data Contract in the Wild with PayPal’s Data Contract Template
PayPal this week released its data contract template. It is exciting to see reference architectures now coming out from different companies. There are eight main sections, including a catch-all section. The pricing part is a surprising addition.
I noticed a few interesting LinkedIn comments about whether YAML is the right format. I prefer IDL solutions like ProtoBuf, Avro, or Smithy. However, Data Contract is a productivity software. It is a tooling problem to convert one data format to another, so any format that can make your team productive, go for it.
(e.g.) Schemata's internal data format is protocol agnostic. You can do document.sh to convert any data format to json format. Even better, you can turn the ProtoBuf format into a data modeling tool—an example schema definition with Schemata.




Schemata Github: https://github.com/ananthdurai/schemata/
PayPal Data Contract Template: https://github.com/paypal/data-contract-template/tree/main/docs
Hannes R5: Six Reasons Why Data Mesh Will Fail
We started seeing increased reference articles from companies about adopting the Data Mesh concept. I found the author well articulated the skepticism which is worth a debate. The author highlights the following six points, which have a lot of merit.
Not all data is valuable.
Data productization is one more thing to do.
There’s not enough data competence around.
Unfettered federated governance won’t work.
Then there’s this central self-service platform.
Most people don’t find data sexy.
Let me know what you all think in the comments.
https://medium.com/@hannes.rollin/six-reasons-why-data-mesh-will-fail-195886c89bdd
Microsoft Azure: Headless Lakehouse
Are you ready to adopt Headless Lakehouse? What is Headless Lakehouse?
A headless lakehouse (aka configurable compute) can be defined as a unified data architecture that provides a seamless way to access and manage data across different computing systems, storage locations, and formats. It enables different systems and users to access, analyze and use the data easily, promoting agility and scalability in data management and analysis.
It is a valid problem statement with the existing LakeHouse format. The LakeHouse format is often tightly coupled with the vendors, leaning towards a vertically integrated data platform.
https://medium.com/microsoftazure/headless-lakehouse-63b0a5d27068
Walmart: Lakehouse at Fortune 1 Scale
Staying on the LakeHouse format, Walmart writes about its choice of the Lakehouse format by comparing all three major formats. The winner for them is Apache Hudi.
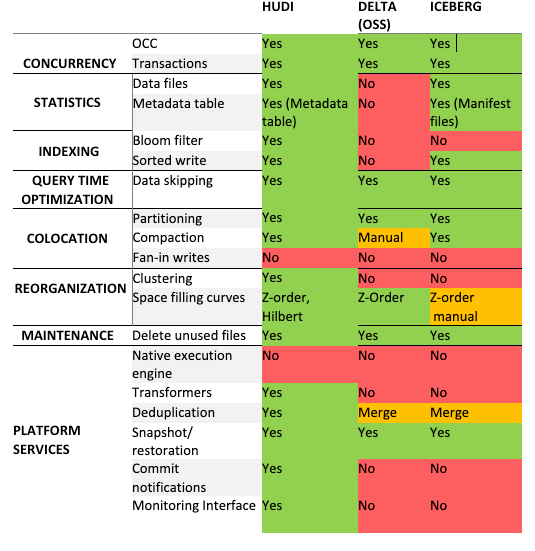
https://medium.com/walmartglobaltech/lakehouse-at-fortune-1-scale-480bcb10391b
Sponsored: [Virtual Data Panel] Measuring Data Team ROI
As data leaders, one of our top priorities is to measure ROI. From tracking the efficacy of marketing campaigns to understanding the root cause of new spikes in user engagement, we’re tasked with keeping tabs on the business's health at all levels. But what about the ROI of our own teams? Watch a panel of data leaders as they discuss how to build strategies for measuring data team ROI.
Watch On-demand
eBay: eBay’s Blazingly Fast Billion-Scale Vector Similarity Engine
eBay writes about its architecture to build similarity product search engine using vector similarity. The blog discusses the batch and the near-real-time data pipeline, the adoption growth, and how it generates millions of dollars in annual revenue.
https://tech.ebayinc.com/engineering/ebays-blazingly-fast-billion-scale-vector-similarity-engine/
Intuit: Democratizing AI to Accelerate ML Model Development in Weeks vs. Months
Intuit shares its journey towards democratizing AI and accelerating ML model development from months to weeks. The article highlights their use of AutoML to automate ML model building which leads to the creation of a centralized ML platform. This approach enables rapid development and improved collaboration and drives significant business impact across various Intuit product lines.
Sponsored: How We Optimized RudderStack’s Identity Resolution Algorithm for Performance
We realized we didn’t need an edge-cluster mapping table with the left and right nodes as columns. We could instead use a node-cluster mapping table and have each edge add a mini-cluster to it upon initialization.
Principle AI/ML Engineer, Justin Driemeyer, details the steps the team at RudderStack took to optimize their identity resolution algorithm for performance after an update to meet a requirement for point-in-time correct materials that resulted in unacceptably long runtimes.
Xavier Gumara Rigol: From Support to Growth Oriented Data Teams (Scaling Your Data Team, Transition #1)
Is Data a support organization in your company? I’ve seen this happen many times. How can a data team move beyond a support team to a growth-oriented team? The author shares an elegant 4-step mantra for all the data teams.

https://xgumara.medium.com/from-support-oriented-to-growth-oriented-data-teams-1d6b7c692b7e
Chad Isenberg: The SQL Unit Testing Landscape - 2023
The article is an excellent summarization of the current SQL unit testing landscape. The author left with a few thought-provoking comments in the end.
Are we there to standardize the data testing?
Do we have a data testing culture?
Data mocking is still an unsolved problem.
https://towardsdatascience.com/the-sql-unit-testing-landscape-2023-7a8c5f986dd3
Funding Circle: How we manage documentation at Funding Circle for our Data Platform
When people approach me for suggestions for implementing Data Catalog & Data Documentation, I always suggest following a few things.
Adopt Documentation as a Code principle.
Build a static site using any static site generator, Voila; your data catalog is ready.
I’m delighted to see Funding Circle writes the same principle in building and maintaining data documentation.
Canva: How Canva saves millions annually in Amazon S3 costs
Though the blog does not directly discuss the data warehouse, the article is an excellent reference implementation to save S3 cost in your data lake. It is vital to know the S3 storage classes, the distribution of your data, and when to apply tiered storage.
https://www.canva.dev/blog/engineering/optimising-s3-savings/
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.