
Data Engineering Weekly #132
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack provides data pipelines that make collecting data from every application, website, and SaaS platform easy, then activating it in your warehouse and business tools. Sign up free to test out the tool today.
Editor’s Note: DEW featured in AirByte’s State of the Data & Slack’s usage of Kafka
DEW has been recognized as the number one individually run data newsletter in the industry, according to the latest AirByte poll! I am truly humbled and overwhelmed by your continuous support and encouragement.
Over the last six months, many readers contacted me and asked about growing in their career as a data engineer or how to switch to data engineering. More qualified people than me are here to write and guide our audience. If you want to write a career guidance series for Data Engineering Weekly, Please DM me on LinkedIn. I'm more than happy to collaborate and help the community.
Over the weekend, I found this an excellent thread on how Slack uses Kafka; I want to highlight this one piece.

I’m thrilled to see this and the design choices we made at that time still echoing. The fundamental design principle that made possible the cut-over operational model is
The producer [Murron] builds with dynamic routing capabilities to reroute traffic to multiple dest.
Treat Kafka as immutable infra
Adopt multi-instance over multi-tenant
We discussed Murron's design in detail here if anyone wants to know more about it.
Cowboy Ventures: The New Generative AI Infra Stack
Generative AI has taken the tech industry by storm. In Q1 2023, a whopping $1.7B was invested into gen AI startups. Cowboy ventures unbundle the various categories of Generative AI infra stack here.
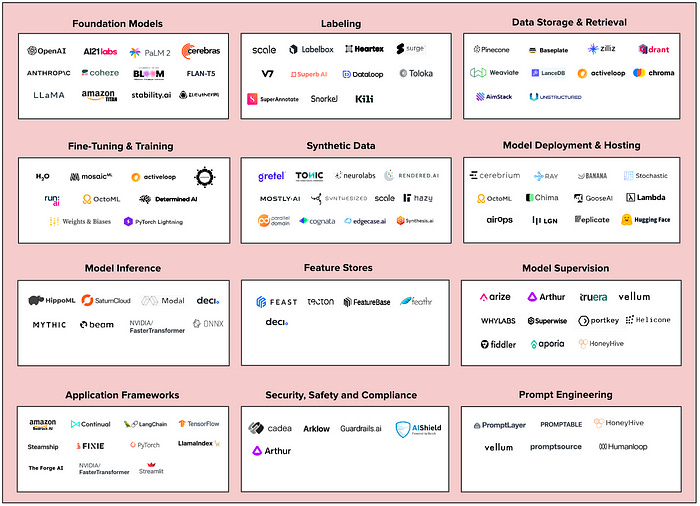
https://medium.com/cowboy-ventures/the-new-infra-stack-for-generative-ai-9db8f294dc3f
HoneyComb: All the Hard Stuff Nobody Talks About when Building Products with LLMs
Continue to focus on LLM; every company in the world is trying to find how LLM fit into their product offering and user experience. HoneyComb writes an excellent article from a developer perspective showing the hard part of integrating LLM into a product experience.
https://www.honeycomb.io/blog/hard-stuff-nobody-talks-about-llm
Coinbase: Databricks cost management at Coinbase
Effective cost management in data engineering is crucial as it maximizes the value gained from data insights while minimizing expenses. It ensures sustainable and scalable data operations, fostering a balanced business growth path in the data-driven era. Coinbase writes one case about cost management for Databricks and how they use the open-source overwatch tool to manage Databrick’s cost.
https://www.coinbase.com/blog/databricks-cost-management-at-coinbase
Walmart: Exploring an Entity Resolution Framework Across Various Use Cases
Entity resolution, a crucial process that identifies and links records representing the same entity across various data sources, is indispensable for generating powerful insights about relationships and identities. This process, often leveraging fuzzy matching techniques, not only enhances data quality but also facilitates nuanced decision-making by effectively managing relationships and tracking potential matches among data records. Walmart writes about the pros and cons of approaching fuzzy matching with rule-based and ML-based matching.
Sponsored: [Virtual Data Panel] Measuring Data Team ROI
As data leaders, one of our top priorities is to measure ROI. From tracking the efficacy of marketing campaigns to understanding the root cause of new spikes in user engagement, we’re tasked with keeping tabs on the business's health at all levels. But what about the ROI of our own teams? Watch a panel of data leaders as they discuss how to build strategies for measuring data team ROI.
Watch On-demand
Zendesk: dbt at Zendesk — Part I: Setting foundations for scalability
Every new technology starts somewhere small in adoption and grows over time, especially complex systems like Zendesk. It is exciting to see the case study of dbt coming out from Zendesk, focusing on foundations and scalability.
https://zendesk.engineering/dbt-at-zendesk-part-i-setting-foundations-for-scalability-34b55e6a6aa1
Instawork: Unlocking the Power of Data: How we scaled our analytics with in-house Event Logging
Event Collection at scale brings its challenges. Instawork writes about its in-house solution for event logging systems. The blog narrates the working on the event collector, writing to Kafka, and the S3 storage with Lambda triggers.
Sponsored: Your Google Analytics Account Needs Immediate Attention 😱
Get this email recently? Love it or hate it, GA4 is a fact of life for many of us. Getting the most out of the tool requires a hybrid implementation to capture data server-side and client-side, but the tools Google provides make this setup complicated and unfulfilling. That’s why RudderStack built a hybrid deployment option for their GA4 integration. It’s a single-step deployment that makes capturing all the data you need for attribution easy while ensuring optimal site performance and ad blocker resiliency.
Learn how to implement GA4 for ad blocker resilience and accurate attribution.
Florian Trehaut: Ensuring GDPR Compliance on GCP BigQuery: Efficiently Managing the Right to Be Forgotten
As a community, I was always concerned that we seldom discussed designing data engineering for regulatory requirements. I'm glad to see the article where the author explains what is Right to Be Forgotten (RTBF) and discusses the architectural pattern in Google BigQuery.
Matt Palmer: What's the hype behind DuckDB?
So DuckDB, Is it hype? or does it have the real potential to bring architectural changes to the data warehouse? The author explains how DuckDB works and the potential impact of DuckDB in Data Engineering.
https://mattpalmer.io/posts/whats-the-hype-duckdb/
Hugo Lu: Why Orchestration is the next hot thing in Data
If I put on a purist Data Engineer hat, The Data Orchestration, Data Lineage, Data Testing, and Data Catalogs all of them should be one system. They are not a separate category.
I’m glad to read the take on the orchestration engine expressing similar thoughts and questioning why there is little innovation in the orchestration space.
https://medium.com/@hugolu87/why-orchestration-is-the-next-hot-thing-in-data-69bc32402446
Sam Moris: Crafting your DBT development workflow
Adopting technology is not only about the individual tool; you need an ecosystem of supporting tools. The author writes about such an ecosystem of tools for dbt, narrating the usage of
dbt-project-evaluator
sql-fluff
pre-commit-dbt
dbt-coverage
PR Template
https://medium.com/cts-technologies/crafting-your-dbt-development-workflow-35577d3b573d
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
Interesting article on the orchestration part, think is more than data 👌🏽