


Data Engineering Weekly #134
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack provides data pipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
Metis: Building Airbnb’s Next-Generation Data Management Platform
Airbnb writes about its next-generation data management platform, “Metis,” with a modernized data catalog approach.

The architecture resembles any typical modern data catalog with search and integration features. The data quality score and per-column-based popularity measure are exciting usage metrics for streamlining data management.
AWS: Choosing an open table format for your transactional data lake on AWS
The adoption of the Lakehouse architecture increasing, but what format to choose? AWS writes a comprehensive analysis of all the Lakehouse formats and their support within the AWS ecosystem.
Clemens Mewald: The Golden Age of Open Source in AI Is Coming to an End
Mostly thanks to AWS, which had mastered the craft of taking open-source infrastructure projects and building commercial services around them, many open-source projects exchanged their permissible licenses for “Copyleft” or “ShareAlike” (SA) alternatives.
The recent frenzy around large language models (LLM) increases the dilemma around the open source vs. non-commercial use licensing model. The author highlights the recent trend of increasing non-commercial & restrictive licenses.

https://towardsdatascience.com/the-golden-age-of-open-source-in-ai-is-coming-to-an-end-7fd35a52b786
Achim Plueckebaum: Unlocking the potential of data: lessons learned from leading data42
Exciting article on lessons learned from the pharma industry on building data infrastructure. Though some of the learning is specific to the pharma industry, we can also draw parallels to other industries. Satisfying regulatory requirements like Sox2, Hippa, and many enterprise orgs dream of Fedramp compliance requires much effort. The author advocates avoiding the time-consuming regulatory process during the initial stages of the team by restricting data sourcing to its velocity. As an industry, we must build better tools to bring this compliance out of the box.
Sponsored: New eBook - Why You Need A Good Data Product Manager (And What They Do)
More data teams are putting data product managers at the helm of their most important data projects and assets. Should you? Our latest guide defines the roles and reponsibilities of data product managers, key differences between managers and engineers, how to measure success, and more.
Yingjun Wu: Why You Shouldn’t Invest In Vector Databases?
I’m experimenting with a few vector databases and found this article provides an interesting perspective.

The current landscape demonstrates a dedicated vector database vs. exciting databases that support vector search.
One thing to note here, search infrastructure is always separate data storage from the operational data store in any org. The newer vector databases have a great chance of success if they can simplify the operational burden and maximize the out-of-the-box feature.
https://medium.com/data-engineer-things/why-you-shouldnt-invest-in-vector-databases-c0cd3f59d23c
Mikkel Dengsøe: Activating ownership with data contracts in dbt
Data Ownership is a hard problem to solve. As the organization grows, the complexity increases, and so does the ownership. A typical application can have 6 to 8 different code paths managed by different teams that can lead to user sign-up. All can emit the same event schema [assuming we successfully standardize schema, that is another hard problem]; now, who owns the sign-up event?
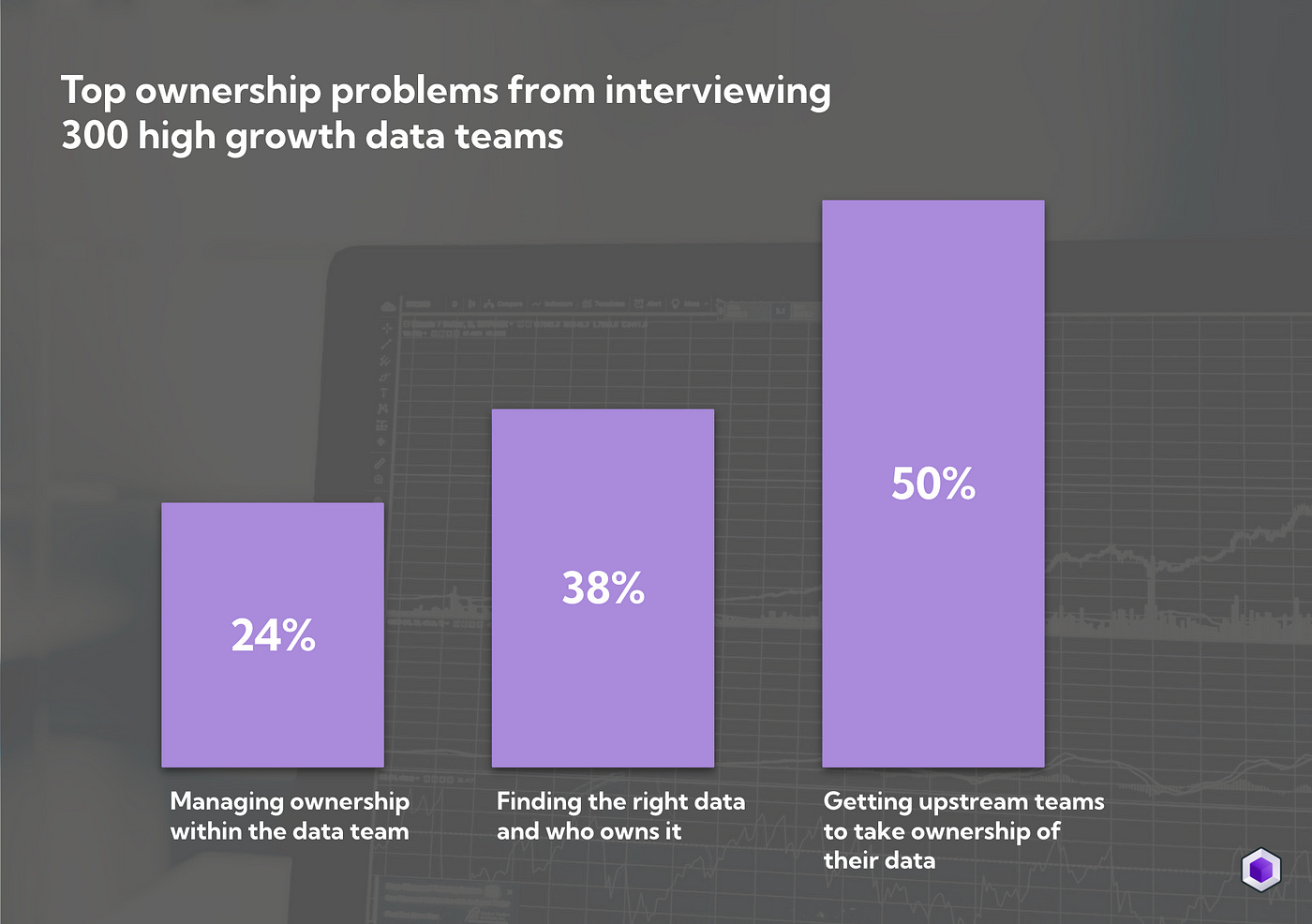
The recent poll mentioned in the article demonstrates the same. The author demonstrates why data contract is a hard problem and how we can use dbt to bring data contract to the data engineering teams.
https://medium.com/@mikldd/activating-ownership-with-data-contracts-in-dbt-4f2de41c4657
Sponsored: The Evolution of the Customer Data Platform
Like the composable approach, The Warehouse Native CDP solves the data silo problem by building around the warehouse, but it deploys the integration, real-time transformation, and activation layers as a connected, governable, and observable end-to-end system.
Here, the RudderStack team examines prevailing approaches to the Customer Data Platform, including the recent composable CDP movement, and introduces a new approach that they believe best delivers the end goal — easy activation of complete customer profiles.
https://www.rudderstack.com/blog/evolution-customer-data-platform/
Lyft: Gotchas of Streaming Pipelines: Profiling & Performance Improvements
A must-read article if you are into the operational efficiency of streaming data pipelines. The author narrates the optimization process starting with the right questions, and drills down further on each profiling and performance optimization aspect.
Is there a bottleneck?
Is the pipeline performing optimally?
Will it continue to scale with increased load?
The questions are the founding block for any system optimization.
https://eng.lyft.com/gotchas-of-streaming-pipelines-profiling-performance-improvements-301439f46412
Tomaz Bratanic: Knowledge Graphs & LLMs: Fine-Tuning Vs. Retrieval-Augmented Generation
LLM is certainly the town's talk, but it comes with its limitation.
Knowledge cutoff [ChatGPT has a "knowledge cutoff" in 2021, which means it knows nothing about the events of 2022 and 2023]
Hallucinations [LLMs train to deliver results in an authentic tone, even if the result can be wrong]
The lack of user customization
The blog narrates Fine-Tuning and Retrieval-Augmented Generation, two techniques to bridge these gaps.
Criteo: PETs for Attribution and Reporting: Key Insights to Take Away
The direct cross-site tracking of user activity brings more harm to the consumer than good. We have seen the browsers and mobile operating systems preventing third-party tracking. Criteo writes about the attribution & reporting proposal by various browsers that leverages Privacy Enhancing Technology [PET].
Maneesh Bhide: Open vs. Portable
Databricks recently announced the extension of its UnityCatalog to Hive Metastore API, which brings an interesting discussion in the open vs. portable article. The author narrates the difference between open and portable systems.
The larger question is, at what point does a commercial company build a portable system? The answer is obviously to capture an exciting, successful open-source framework. It is true for Kafka protocol, Hive metastore, and many others. Open is the first step to bringing portable systems into the industry.
https://medium.com/@mbhide/open-vs-portable-c1beda131ab6
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.