
Data Engineering Weekly #135
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack provides data pipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
Sanjeev Mohan: How to Use Large Language Models (LLMs) on Private Data: A Data Strategy Guide
Despite all the attention AI garners, some high-profile missteps have reminded the world once again of “garbage in, garbage out.” If we ignore the underlying data management principles, then the output can’t be trusted.
I can’t agree more on this. Data management is critical for any organization to succeed in this AI world. Sanjeev highlights three options for an organization to adopt with their private model.

The blog narrates LLM training options, Storage & retrieval, and the value chain to use LLM in your private data.
LinkedIn: Open Sourcing AvroTensorDataset: A Performant TensorFlow Dataset For Processing Avro Data
An exciting article from LinkedIn is about optimizing the Avro format reader & writer for efficient TensorFlow data processing.

The optimization around prefetching data with a separate thread, the decision not to support complex data types, and the complexity around Avro’s sequential block read are informative to know more about Avro.
Spotify: Experimenting at Scale, the Spotify Home Way
The quality and velocity in the experimentation truly will differentiate a product from its competitors. Spotify shares one such story of how it increases the velocity & quality of the experimentation on its home page. TIL, Spotify runs 250+ experimentation annually on its home page!!!

https://engineering.atspotify.com/2023/06/experimenting-at-scale-the-spotify-home-way/
Nils Skotara: Sequential Testing at Booking.com
Most often, hypothesis testing is done by calculating how much data is needed to reach a decision. This calculation must be done upfront and requires waiting until sufficient data has been collected. A major benefit of sequential testing is that it does allow for interim analyses while maintaining the correct alpha error rate.

Staying on experimentation and AB testing, Booking.com narrates the types of sequential testing and its variations, especially focusing on Group Sequential Design.
https://booking.ai/sequential-testing-at-booking-com-650954a569c7
Sponsored: [dbt + Monte Carlo Webinar] 5 Critical Steps for Building Impactful Data Organizations
Building a data strategy from scratch? You're not alone! Join Monte Carlo, dbt, and Shiftkey's VP of Data & Analytics, John Steinmetz. on June 20th as he shares his experiences building the technologies, team structure, and KPIs necessary to align data and analytics success with larger business objectives.
Leo Godin: Understanding DBT Runtime Environment
One of my favorite way to learn new systems is to tail its logs and starring at it for some time. Then start chasing where these logs are coming from the code; you know the system much better now.

I’m super thrilled to see the blog. I found fewer blogs focus on a technical deep-dive into the internals of dbt, and this one follows my favorite way of learning!!! Kudos to the author.
https://leo-godin.medium.com/understanding-dbt-runtime-environment-1fd28592bbd
Ritika Srivastava: PII data privacy in Snowflake
PII detection & prevention plays a critical role in data governance. The blog narrates the journey of PII engineering from the discovery phase, creating policies around PII data, Snowflake roles hierarchy to prevent unauthorized access, and dbt macros to enable data masking.

https://medium.com/voi-engineering/pii-data-privacy-in-snowflake-b523d38b02ff
Sponsored: Webinar: 2 Keys to Overcoming the Limitations of GA4
Join RudderStack, Snowflake, and BlastX on Wednesday, 6/21, to learn how to set up a hybrid implementation to get the most out of Google Analytics 4. Plus, learn how to build web analytics on your data cloud to go beyond Google Analytics and answer harder questions.
https://www.rudderstack.com/events/2-keys-to-overcoming-the-limitations-of-ga4/
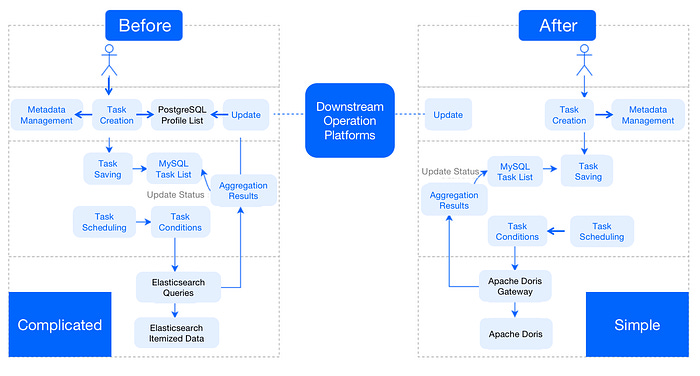
Apache Doris: Replacing Apache Hive, Elasticsearch, and PostgreSQL with Apache Doris
The analytical databases, especially the one focusing on customer-facing applications, started to support multiple index types. It significantly increases the efficiency of the systems and provides more flexibility for faster delivery of analytical products. Apache Pinot is one such system that provides such capabilities, and thrilled to read about Apache Doris too.
Cockroach Labs: Forward Indexes on JSON columns
Okay, I’ve to admit. Eventually, I came to terms with JSON. It is inevitable in data processing whether we like it or not. Of late, I started to explore more JSON indexing, and I found an informative article from Cockroach DB on supporting forward indexes on JSON data and its challenges.
https://www.cockroachlabs.com/blog/forward-indexes-on-json-columns/
Shashank Mishra: AWS Redshift - Robust and Scalable Data Warehousing
Okay, folks, I’ve never seen any positive article about Redshift in the past. All I noticed was, “Our migration journey from Redshift to <insert your db>. 😊 Is it a sympathetic selection? It could be. Also, the author explains Redshift architecture and various types of nodes and the key features.
https://m.mage.ai/aws-redshift-robust-and-scalable-data-warehousing-4d0083904ca7
Muhammad Ahsan: From MySQL to Greenplum: Lessons and Insights from an ETL Pipeline Migration Journey
The first time hearing of migration to Greenplume, even though it is from MySQL. The modern data stack is dead indeed :-)
However, what is interesting to me is that the migration challenges listed by the author are true for any one database to another. SQL, in theory, should be a standard, but unfortunately, that is not the case in the real world.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.