
Data Engineering Weekly #139
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles, so you can quickly ship actionable, enriched data to every downstream team. See how it works today.
Editors’ Note: Update on DewCon | Data Eng + Gen AI Conference in Bengaluru - October 12th, 2023
Data Engineering Weekly is back in action after a week of summer break. I tried my best to write last week, but the travel took its toll. While on travel Aswin & I were busy preparing for DewCon.
I'm happy to see the wide variety of talk proposals from people management, Gen AI, Machine Learning, modern data stack, and more!!!
We are extending the call for speakers for three more days!!! The last day to submit the proposal is now July 26th, at midnight EST!!!
Submit Your Conference Talk Proposal Here
Tim Dettmers: Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning
Deep Learning and Gen AI are speculated to impact software architecture greatly. Investing in AI also means reserving GPU computation capacity.

Source: https://twitter.com/theinformation/status/1681639525125181442
But what features are important if you want to buy a new GPU? GPU RAM, cores, tensor cores, caches? How to make a cost-efficient choice? This blog post will delve into these questions, tackle common misconceptions, and give you an intuitive understanding of how to think about GPUs.
https://timdettmers.com/2023/01/30/which-gpu-for-deep-learning/
Piethein Strengholt: Data Management at Scale
Data Mesh is a widely discussed and debated topic on the possibility of decentralized data management at scale. The author unpacks the federated design for data management in a phase-by-phase manner by adding more components as expanding.

https://piethein.medium.com/data-management-at-scale-91118a1a7d83
Whatnot: Data Contracts in the Modern Data Stack
Data Contract is gaining traction in the industry as we witness implemented strategies published by the companies. The reference architecture published by Whatnot is probably the cleanest one I’ve seen for Data Contracts.

I heard a similar adoption success story for Schemata, which I was unaware that they have been using Schemata for a long time!!! Overall an exciting time for a data contract in 2024.
https://medium.com/whatnot-engineering/data-contracts-in-the-modern-data-stack-d42cb2442dbd
Sponsored: Atlan AI – The First Copilot for Data Teams
How do you create documentation for 1000s of data assets in minutes? Write SQL queries without learning SQL? Find the right, trusted data by simply asking a question. If you’re searching for an answer, it’s Atlan AI.
Atlan AI leverages metadata that Atlan captures across the data stack to make AI part of your data stack. Now, you can get hours back by letting Atlan AI draft your documentation and write your queries. And you won’t have to ask 3 different people in your team just to find the right, trusted data — you just need your AI copilot.
Watch the Atlan AI demo and join the Atlan AI waitlist →
Github: A developer’s guide to prompt engineering and LLMs
Converting between the user domain and document domain is the realm of prompt engineering
Github writes an excellent blog on a developer’s guide to prompt engineering & LLM by walking through the prompt engineering pipeline for Github CoPilot. The blog classifies the pattern of prompt engineering from its experience building Github CoPilot.

https://github.blog/2023-07-17-prompt-engineering-guide-generative-ai-llms/.
Thoughtworks: GenAI practical governance: How to reduce information security risk
There is a growing list of companies banning ChatGPT, and Apple is the latest company to join the list. There is a growing concern about data governance, with information leakage considered a significant security leakage. The blog overviews potential information leakage and how to minimize it.
Sponsored: [New Report] The State of Data Products, 2023 Edition
Data trust is on every data team’s mind, but how do you create and maintain it? To help answer those questions, we surveyed over 200 data teams to benchmark data product adoption rates and how data leaders can improve them. Access the guide today to see how your peers are boosting data adoption and maximizing the return on their data products.
Expedia: Demystifying Technical Program Management in Data Science at Expedia Group
There is a lot of conversation about engineering management for data, how undervalued data analysts are, and democratizing data access. However, we focused very little on implementing data science projects from a program management perspective. Kudos to the author; the blog is an excellent narration of technical program management for data science and its challenges.
Airbnb: Chronon — A Declarative Feature Engineering Framework
We always strive to simplify the ETL process with more abstraction to increase the velocity of data creation and the management process. Aibnb writes about one such declarative framework to simplify the feature engineering process.
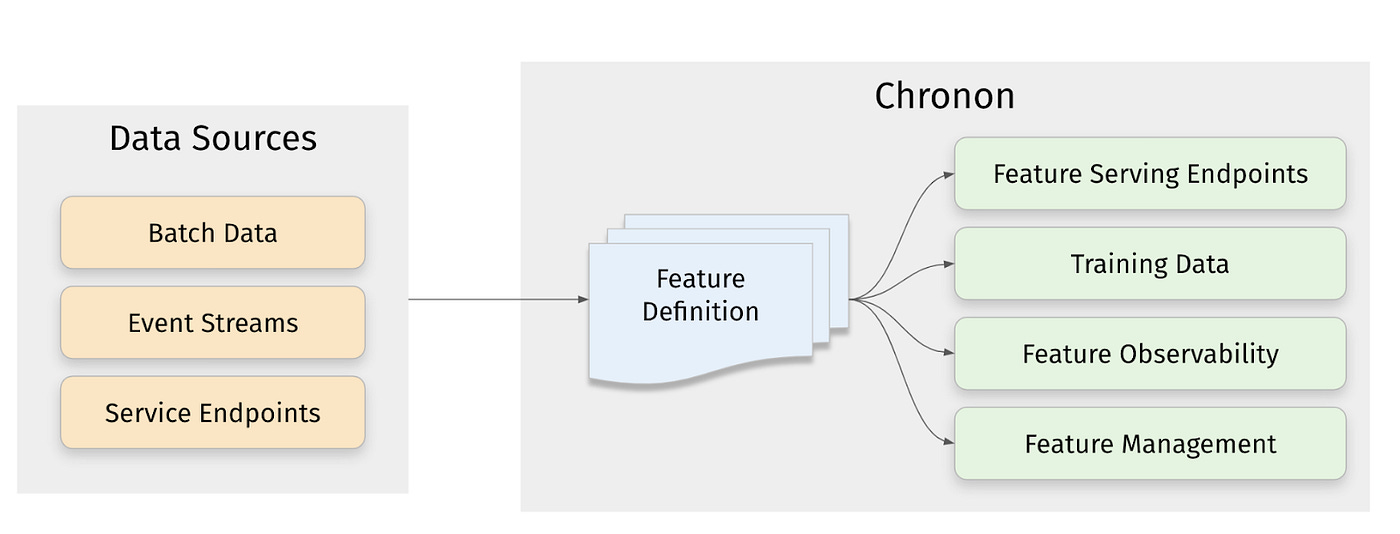
Combining data sources from batch, event stream, and service endpoints as an api is an excellent abstraction for acquiring the data sources.
Sponsored: Introducing RudderStack Profiles: Easily Build Complete Customer Profiles in Your Warehouse
With Profiles, you can create features using pre-defined projects in the user interface or a version-controlled config file, and all of the queries and computations are taken care of automatically.
Now every team can build a customer360 in Snowflake with RudderStack Profiles. The new product is a data unification tool that handles the heavy lifting of identity resolution for you, streamlines user feature development, and automatically builds a customer 360 table so that you can ship high-impact projects faster.
https://www.rudderstack.com/blog/introducing-rudderstack-profiles/
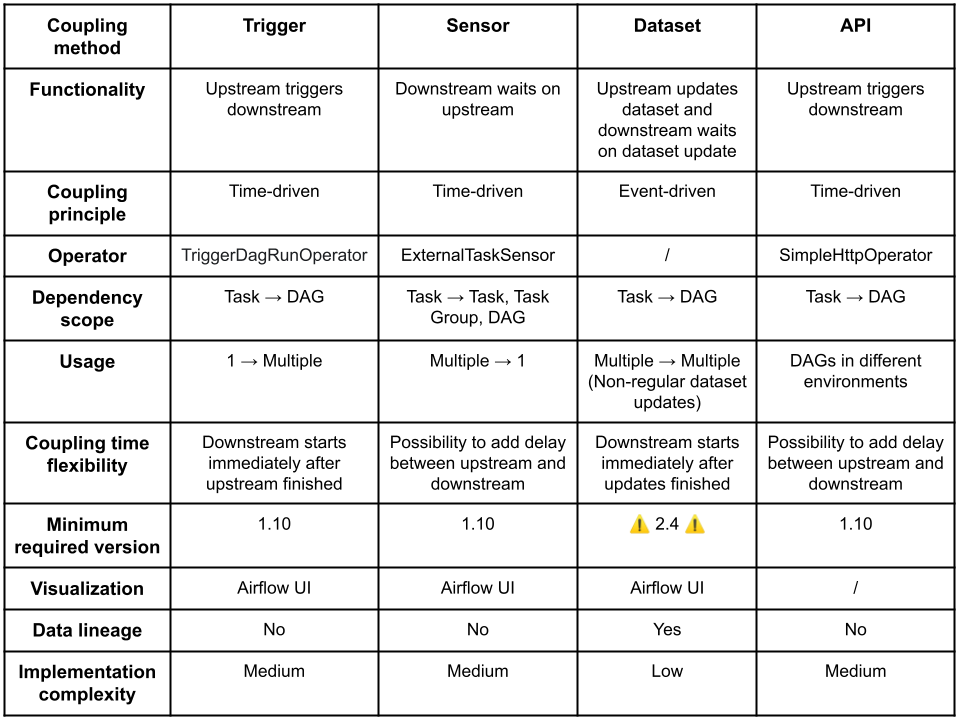
Frederic Vanderveken: Cross-DAG Dependencies in Apache Airflow: A Comprehensive Guide
Is one DAG to rule all, or multiple DAGs working together is a good approach? It is inevitable in Airflow to have multiple DAGs coordinate with each other. The blog talks about the pros and cons of cross-DAG dependency management options in Airflow, such as,
Triggers
Sensors
Datasets
API
LinkedIn: Taking Charge of Tables - Introducing OpenHouse for Big Data Management
OneHouse recently announced OneTable, an interoperable format for all three major LakeHouse formats, such as Hudi, DeltaLake, and Iceberg. Databricks also announced UniForm, similar to OneTable. It is exciting to see LinkedIn arrive at a similar solution with the data vendors and write about OpenHouse API to bring interoperability among the LakeHouse formats.
Are we reinventing Hive Metastore?!! 😊
Pinterest: Tuning Flink Clusters for Stability and Efficiency
Pinterest runs 130+ Flink jobs across eight multi-tenant production YARN clusters, and the largest Flink job is 2,000+ cores!!! The blog is an excellent overview of problems running multi-tenant data processing systems without CPU isolation. The solution overview with container placement in YARN is an exciting read.

All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.