
Data Engineering Weekly #140
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles, so you can quickly ship actionable, enriched data to every downstream team. See how it works today.
Editor’s Note: DewCon.ai update
Heads up, folks! 📣 The paper submissions phase for DewCon is now wrapped up! 🎉 Thanks to each of you who has contributed your awesome proposals - you rock! 🙌💯 Right now, we're sorting out a few snags with the registration payment system, but no stress! 🚫💼 We're burning the midnight oil to get this sorted ASAP 🌙💻. Stay tuned for updates, and keep the excitement rolling! 😄🎢🚀
High Scalability: Lessons Learned Running Presto At Meta Scale

Presto, potentially ranking as one of the most influential open-source initiatives of the past ten years, stands shoulder to shoulder with the likes of Apache Kafka. With its pivotal role in the Big Data revolution, handling large datasets is so seamless that we've nearly forgotten the 'Big' in Big Data. Meta writes the story of the challenges of operating Presto at scale and its architectural choices.
http://highscalability.com/blog/2023/7/16/lessons-learned-running-presto-at-meta-scale.html
All Things Distributed: Building and operating a pretty big storage system called S3.
We handle Petabytes of data!!! All our data is in S3!!!
Oh, just throw this data in S3 and possibly apply intelligent tiering.
If you’re a. data engineer, you won’t be surprised to hear this. S3 is often quoted as the backbone of the internet. The blog from All Things Distributed goes behind the scene on the challenges of operating S3 with the data placement strategy and managing machine heat and human factors.

https://www.allthingsdistributed.com/2023/07/building-and-operating-a-pretty-big-storage-system.html
Slack: Service Delivery Index: A Driver for Reliability
By Data & Data Engineering, we often associate with business operations and product analytics. But the power of the data pipeline to systematically measure things goes beyond business analytics. Slack writes about Service Delivery Index, a simple reliability data pipeline, and its impact on operating systems at scale.
https://slack.engineering/service-delivery-index-a-driver-for-reliability/
At Data Engineering Weekly, We already discussed the importance of SPQR [Security, Performance, Quality, Reliability] metrics for operating systems at scale. In case you missed it, this is a must-watch talk
Sponsored: Great Data Debate–The State of Data Mesh
Since 2019, the data mesh has woven itself into every blog post, event presentation, and webinar. But 4 years later, in 2023 — where has the data mesh gotten us? Does its promise of a decentralized dreamland hold true?
Atlan is bringing together data leaders like Abhinav Sivasailam (CEO, Levers Labs), Barr Moses (Co-founder & CEO, Monte Carlo), Scott Hirleman (Founder & CEO, Data Mesh Understanding), Teresa Tung (Cloud First Chief Technologist, Accenture), Tristan Handy (Founder & CEO, dbt Labs), Prukalpa Sankar (Co-founder, Atlan), and more at the next edition of the Great Data Debate to discuss the state of data mesh – tech toolkit and cultural shift required to implement data mesh.
Learn more and sign up to join the Great Data Debate on August 16 →
Airbnb: Riverbed - Optimizing Data Access at Airbnb’s Scale
Lambda and Kappa are two real-time data processing architectures. Lambda combines batch and real-time processing to efficiently handle large data volumes, while Kappa focuses solely on streaming processing. Kappa’s simplicity offers better maintainability, but it poses challenges for implementing backfill mechanisms and ensuring data consistency, especially with out-of-order events.
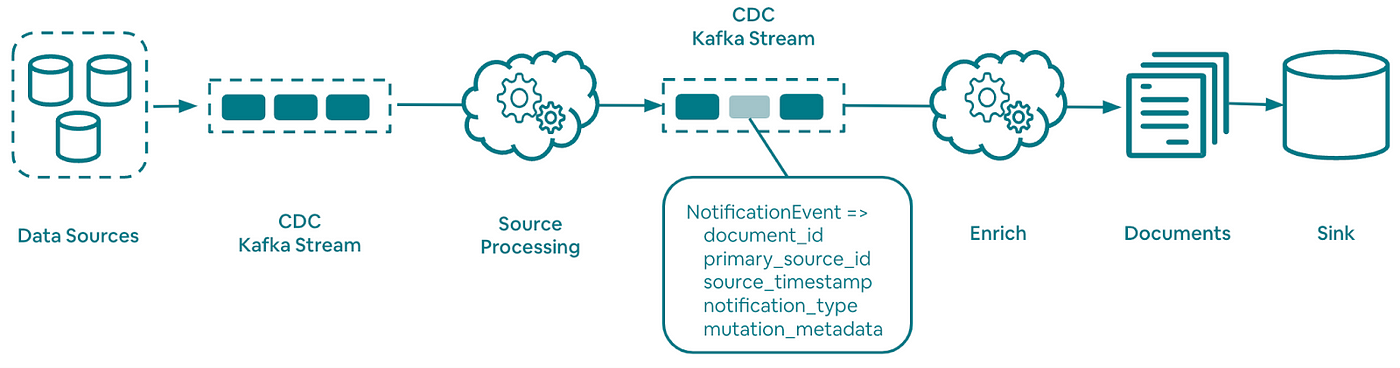
I’m sure every data engineer ran into this problem at some point while looking to bridge the gap between real-time and batch processing. Airbnb writes about Riverbed - a Lambda-like data framework that abstracts the complexities of maintaining materialized views, enabling faster product iterations.
https://medium.com/airbnb-engineering/riverbed-optimizing-data-access-at-airbnbs-scale-c37ecf6456d9
Pinterest: Securely Scaling Big Data Access Controls At Pinterest
An efficient data access control significantly simplifies the data infrastructure and brings a seamless user experience. Pinterest writes about its design choices of designing an access control system by migrating from restricting access to data in S3 using dedicated service instances where different clusters of instances were granted access to specific datasets. The tiered dataset access to individual users is a much simpler and scalable solution from my recent experience designing access control systems.

Sponsored: [New eBook] Gartner Innovation Insight: Data Observability Enables Proactive Data Quality
In 2023, data observability is a must-have for companies seeking to reduce time, resources, and budget spent firefighting unreliable or anomalous data while unlocking new opportunities to cut costs and drive growth. Not sure where to start or what to look for in a data observability tool? Look no further than the Gartner latest report.
Lilian Weng: LLM Powered Autonomous Agents
A couple of months back, AutoGPT - an AI agent that utilizes OpenAI's GPT-4 or GPT-3.5 APIs to execute tasks based on natural language goals autonomously, showed the power of LLM-powered autonomous agents. What are the steps and considerations to consider while building such autonomous AI agents? The author writes a complete guide to building LLM-powered autonomous agents.
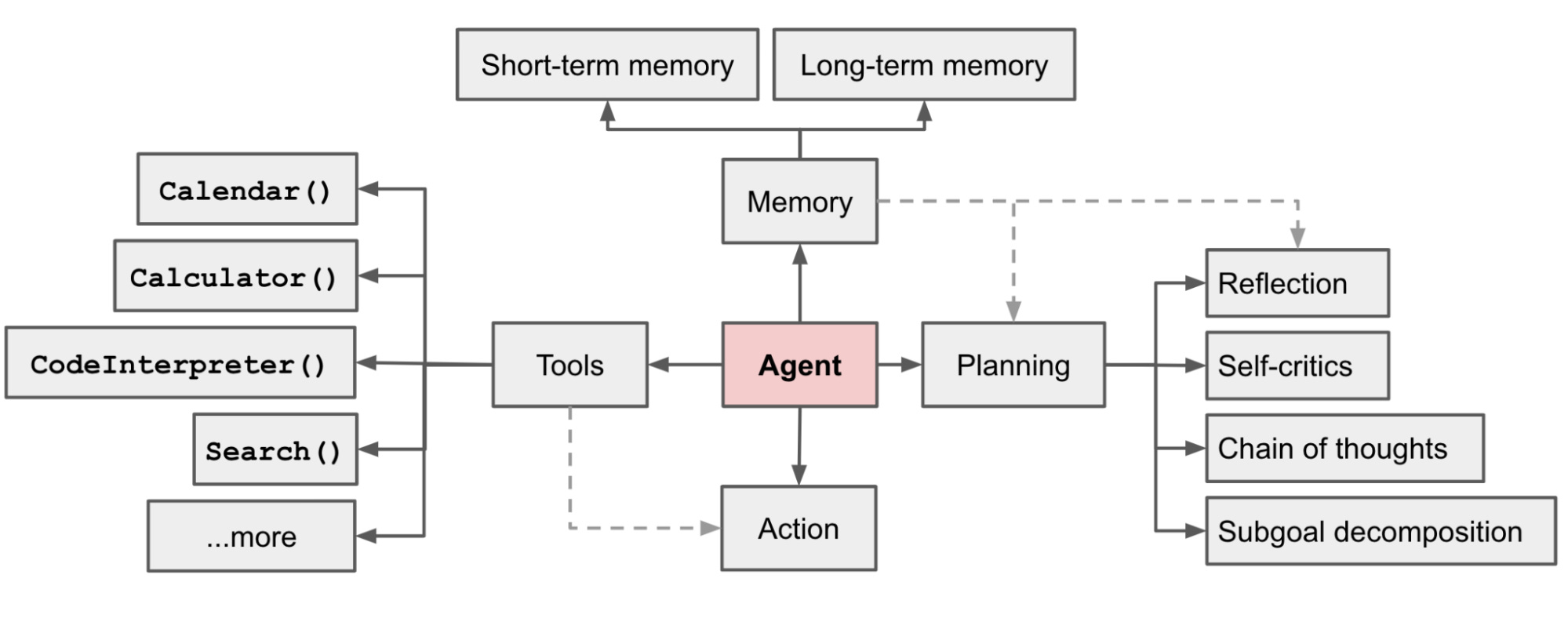
https://lilianweng.github.io/posts/2023-06-23-agent/
Sebastian Raschka: Finetuning Large Language Models
In essence, we can use pre-trained large language models for new tasks in two main ways: in-context learning and finetuning.
The blog is an excellent guide to thinking about finetuning methods, with three categorizations of approaches.

Feature-Based Approach
Finetuning I – Updating The Output Layers
Finetuning II – Updating All Layers
https://magazine.sebastianraschka.com/p/finetuning-large-language-models
Sponsored: Real-Time Event Streaming: RudderStack vs. Apache Kafka
If your operations involve managing large-scale databases and you can dedicate resources for Kafka's administration and maintenance, then Kafka is your tool. RudderStack, on the other hand, is an excellent choice for businesses that are looking for a streamlined solution to collect, unify, and activate customer data from various sources to various destinations without Kafka's complexities.
Here’s an interesting breakdown of event streaming approaches that compare RudderStack to Apache Kafka. While it may be comparing apples and oranges, the two platforms can be used to achieve the same ends, and this piece provides a helpful framework to determine when it's appropriate to use each tool.
https://www.rudderstack.com/blog/real-time-event-streaming-rudderstack-vs-apache-kafka/
Gradient Flow: Ten Keys to Accelerating Enterprise Adoption of LLMs
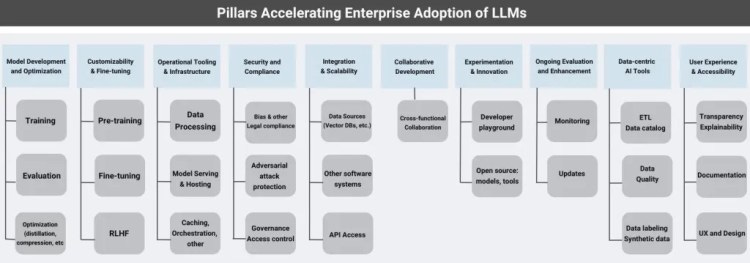
The promise of LLM in enterprise applications is immense, but many companies don’t have a clear product and compliance strategy to adopt LLM in their architecture. The blog is an excellent checklist for companies to think about LLM and how to integrate it into the product and collaborative software development process.
https://gradientflow.com/enterprise-generative-ai-unfolded/
AWS: The role of vector datastores in generative AI applications
Do we need a separate data store for Vector storage? Can Vector Datastore simplify the entity resolutions? Can it democratize the recommendation engine? There are many potential possibilities and questions on vector databases. AWS writes a blog to extend these questions on demonstrating the role of vector data stores in Gen-AI applications.
https://aws.amazon.com/blogs/database/the-role-of-vector-datastores-in-generative-ai-applications/
Walmart: DuckDB vs. The Titans: Spark, Elasticsearch, MongoDB — A Comparative Study in Performance and Cost
The world would be in a better place if all the computing problems could be solved in a single computing instance.
The author demonstrates the same, comparing DuckDB with other industry-leading data processing frameworks. However, comparing DuckDB with Spark or Elasticsearch is not exactly an Apple-to-Apple comparison since DuckDB is an in-memory data processing engine. In contrast, the like of Spark is designed to run in a massively parallel distributed data processing.
DuckDB brings an exciting data architecture challenge to the industry. Do you really need massively parallel data processing engines all the time? Can you design your data architecture in such a way as to utilize in-memory data processing efficiently?
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.