
Data Engineering Weekly #142
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack Profiles takes the SaaS guesswork, and SQL grunt work out of building complete customer profiles, so you can quickly ship actionable, enriched data to every downstream team. See how it works today.
Editor’s Note: DewCon.ai Registration is Now Open
Great news! We've overcome some unexpected hiccups, and guess what? Conference registration is officially OPEN! 🎉
Mark your calendars: DEWCon is happening on October 12th at the luxurious Taj Hotel on MG Road. 🏨
We got some exciting keynotes lined up. Joe Reis, author of "The Fundamentals of Data Engineering," and Vinoth Chandar, creator of Apache Hudi and founder of OneHouse.ai. 📚💡 will be diving into the latest industry buzz. 🚀 Stay tuned for all the details! 🔍
Meta: Scaling the Instagram Explore recommendations system
AI plays an important role in what people see on Meta’s platforms. Meta writes about mult—stage ranking approach with several well-defined stages, each focusing on different objectives and algorithms.
Retrieval
First-stage ranking
Second-stage ranking
Final reranking

Weiting Chen: Accelerate Spark SQL Queries with Gluten
SparkSQL is a stop-gap to bride Spark RDD accessible to a mass audience, and ever since, there has been a constant effort to improve its SQL performance. Databricks attempt to solve this by Photon. Gluten from Intel & Kyligence is taking an open-source attempt to accelerate Spark SQL queries.
https://medium.com/intel-analytics-software/accelerate-spark-sql-queries-with-gluten-9000b65d1b4e
Github: https://github.com/oap-project/gluten
Vimeo: From idea to reality - Elevating our customer support through generative AI
The application of GenAI has huge potential to disrupt the customer support industry. Vimeo writes about indexing Zendesk’s articles in a vector database to improve search performance and use ConversationalRetrievalQAChain to connect to the Vector store and LLM.

Sponsored: Great Data Debate–The State of Data Mesh
Since 2019, the data mesh has woven itself into every blog post, event presentation, and webinar. But 4 years later, in 2023 — where has the data mesh gotten us? Does its promise of a decentralized dreamland hold true?
Atlan is bringing together data leaders like Abhinav Sivasailam (CEO, Levers Labs), Barr Moses (Co-founder & CEO, Monte Carlo), Scott Hirleman (Founder & CEO, Data Mesh Understanding), Teresa Tung (Cloud First Chief Technologist, Accenture), Tristan Handy (Founder & CEO, dbt Labs), Prukalpa Sankar (Co-founder, Atlan), and more at the next edition of the Great Data Debate to discuss the state of data mesh – tech toolkit and cultural shift required to implement data mesh.
Learn more and sign up to join the Great Data Debate on August 16 →
OLX Engineering: Machine Learning for Delivery Time Estimation

An accurate delivery time estimation has become crucial in ensuring customer satisfaction and building trust in e-commerce platforms. OLX writes an exciting article discussing every step of a data science project, from defining the problem and success criteria to taking the solution to production and identifying the next steps.
https://tech.olx.com/machine-learning-for-delivery-time-estimation-1-591c8df849a0
Swiggy: Predicting Food Delivery Time at Cart
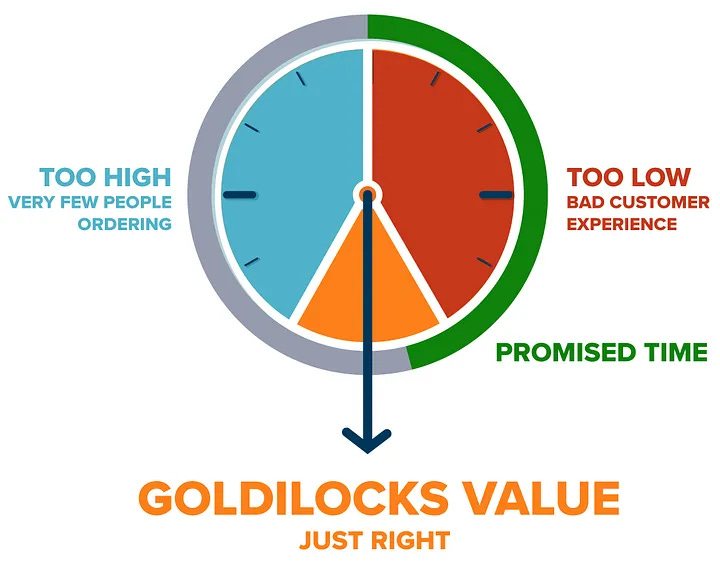
Continue discussing the delivery time estimation problem, Swiggy writes about challenges in building a food delivery estimation service. The food delivery service is a multi-stage business process where each step has its feature to predict the delivery estimation.
Food Preparation Features
Assignment and First Mile features
Last Mile Features
https://bytes.swiggy.com/predicting-food-delivery-time-at-cart-cda23a84ba63
Sponsored: IMPACT - The Data Observability Summit is back! | November 8, 2023
Interested in learning how some of the best teams achieve data & AI reliability at scale? Join us for the third annual IMPACT - The Data Observability Summit. Hear from today's top data leaders and architects on how to build more trustworthy and reliable data & AI products with the latest technologies, processes, and strategies shaping our industry (yes, LLMs will be on the table).
Just Eat: Building a Listwise Ranking TF recommender - A step-by-step guide.
Breaking from the delivery estimation, Just Eat, a food delivery service writes about a step-by-step guide to building a listwise ranking TF recommender. Listwise ranking, often referred to within the context of Learning to Rank (L2R) in the machine learning domain, is an approach to ranking where entire lists of items are used as training examples rather than individual items or pairs of items.
DraftKings: Intro — Sports Intelligence at DraftKings
Sports Analytics is an exciting domain, and I’m sure many of our readers are interested. DraftKings writes an in-depth article about its Sports Intelligence team mission, a high-level architectural overview, and the data science software development lifecycle for MLOps.

https://medium.com/draftkings-engineering/intro-sports-intelligence-draftkings-51c285bb3737
Sponsored: Webinar: Data Engineering for Customer 360
Monday, August 7, join the RudderStack engineering team to learn the foundational principles of constructing a high-performance, scalable architecture for identity resolution using SQL. The team will give an overview of customer 360 architecture, detail the mechanics of using SQL for identity resolution in the warehouse, and demonstrate using declarative YAML to simplify the process.
https://www.rudderstack.com/events/data-engineering-for-customer-360/
Faire: The building blocks of Faire’s Data Team onboarding
Onboarding is a vital aspect that defines the engineering culture of a company. A best-in-class onboarding process is a reflection of inclusive and empathetic engineering culture.
Faire writes about their onboarding process and course structure to better educate engineers and stakeholders to be familiar with data engineering.

https://craft.faire.com/the-building-blocks-of-faires-data-team-onboarding-628229b043b6
Sivabalan Narayanan: Different Query types with Apache Hudi
Incremental data processing & Time Travel are the core access patterns of Data Pipelines, and that is the foundation of transactional LakeHouse formats like Apache Hudi. However, I do think SQL is not fully reflecting the underlying pattern. The author narrates different types of queries with Apache Hudi is a good foundational understanding of thinking about LakeHouse access patterns.
https://medium.com/@simpsons/different-query-types-with-apache-hudi-e14c2064cfd6
Lucas Gabriel: Dask, Dagster, and Coiled for Production Analysis at OnlineApp
Dask is a flexible parallel computing library for analytics. As Python takes center stage in AI computing, reading about parallel processing engines like Dask is fascinating. The blog narrates the integration of Dask with Dagster for analytical pipeline design.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.