
Data Engineering Weekly #144
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack Profiles takes the SaaS guesswork, and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. See how it works today.
Editor’s Note: DewCon.ai - October 12, Bengaluru, India Update
Hey folks! 📣 Exciting news! We've finalized the agenda for the conference and we will be launching middle of this week. 🎤 And guess what? We've given our conference website a fresh look. 🌐
Tickets are selling fast; use the code DATAHERO for a special discount. 🎟️ Oh, and if your company's thinking of bulk booking, drop an email to ananth@dataengineeringweekly.com to get some awesome discounts. 📩
Looking forward to seeing you all! 👋🙂
Tomasz Tunguz: The Paradox of AI and Data Teams: How Automation Will Increase Demand for Data Professionals
AI will automate 25-50% of white collar work including data analysis. Does that will data teams shrink in size? On the contrary, while AI can automate some work, it will also demand much more from data teams.

Though it is a short essay, the author remind is AI & data team relationship is a typical Braess's paradox. The ease of data access and democratization increase the need for better quality with contextual data. So all in data folks, Let’s do it.
https://www.linkedin.com/pulse/paradox-ai-data-teams-how-automation-increase-demand-tomasz-tunguz/
AnyScale: Llama 2 is about as factually accurate as GPT-4 for summaries and is 30X cheaper
The rise of Open Source LLM model giving tough fight with the proprietary LLM models like OpenAI. AnyScale published LLM accuracy comparison among Llama 2 vs GPT 4 and Human, it is amazing to see all models almost equal at the human level.

Netflix: Lessons Learnt From Consolidating ML Models in a Large Scale Recommendation System
Netflix writes about consolidating multiple machine learning models used for different recommendation tasks into one multi-task model. This approach simplified the system's architecture, improved model performance, and enhanced maintainability. Netflix narrates how it addressed the challenges in both offline (training) and online (deployment) phases, introducing a unified request context and a generic API.

Sponsored: [New Report] State of Data Quality: 2023 Edition
Data trust is at an all-time low, and teams are feeling the pain. Our latest report highlights the impact of bad data on your bottom line (did you know that poor data quality impacts 31% of revenue?!) and how the best teams are reducing incident resolution times?
Booking.com: How good are your ML best practices?
Software engineering practice have tons of best practices, all the way from code formating to code coverage to API design patterns. Machine Learning Systems pose their own specific challenges, and Booking.com narrates its quality model for Machine Learning.
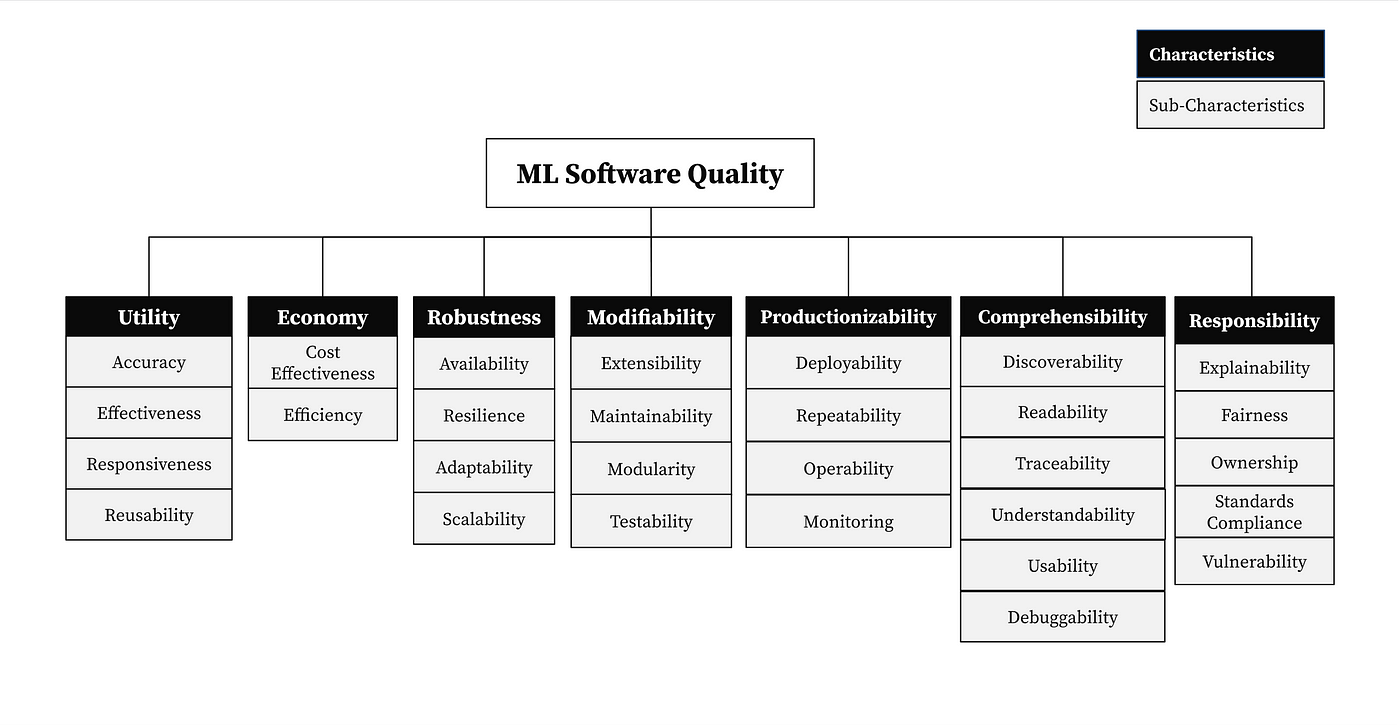
https://booking.ai/how-good-are-your-ml-best-practices-fd7722262437
Joe Naso: DBT vs SDF vs SQLMesh
The competition in the data transformation layer is heating up. While dbt is certainly the most popular transformation layer, we’ve seen emerging alternatives like SQLMesh and SDF [Semantic Data Fabric]. You can’t say that one is better than the others; the author gives an excellent walkthrough of all three transformation engines.
https://datajargon.substack.com/p/dbt-vs-sdf-vs-sqlmesh
Sponsored: Webinar: Unlock AI-driven personalization with RudderStack & Snowflake
August 30, Join Wyze’s Director of Data Engineering, Wei Zhou, and Senior Data Scientist, Pei Guo, to learn how they’re using RudderStack and Snowflake to collect clean, comprehensive data, quickly model it into an identity graph and customer 360 tables, then make that data available to their AI team for modeling directly inside of Snowflake’s Data Cloud.
DataCoves: An Overview of Testing Options for dbt (data build tool)
Data Testing is an integral part of data transformation lifecycle. DataCoves writes an excellent article comparing various data testing options available to use with dbt. I like the approach of categorizing the testing strategy as generic test & singular tests.
https://datacoves.com/post/dbt-test-options
Enigma: Dev/Stage/Prod is the Wrong Pattern for Data Pipelines
Data engineering has missed the boat on the “devops movement” and rarely benefit from the sanity and peace-of-mind it provides to modern engineers. They didn’t miss the boat because they didn’t show up, they missed the boat because the ticket was too expensive for their cargo.
Maxime Beauchemin - The Downfall of the Data Engineer
I still see many data teams trying to mimic the dev/ stage/ prod environment in the data pipeline, which brings more confusion than solving the problem. The author argues why dev-stage-prod is bad and encourages data sandbox/ branching strategy to test the pipeline.

https://enigma.com/blog/post/dev-stage-prod-is-the-wrong-pattern-for-data-pipelines
Sponsored: Great Data Debate–The State of Data Mesh
Since 2019, the data mesh has woven itself into every blog post, event presentation, and webinar. But 4 years later, in 2023 — where has the data mesh gotten us? Does its promise of a decentralized dreamland hold true?
Atlan is bringing together data leaders like Abhinav Sivasailam (CEO, Levers Labs), Barr Moses (Co-founder & CEO, Monte Carlo), Scott Hirleman (Founder & CEO, Data Mesh Understanding), Teresa Tung (Cloud First Chief Technologist, Accenture), Tristan Handy (Founder & CEO, dbt Labs), Prukalpa Sankar (Co-founder, Atlan), and more at the next edition of the Great Data Debate to discuss the state of data mesh – tech toolkit and cultural shift required to implement data mesh.
Watch the Recording of the Great Data Debate →
Paul Fry: How to Create CI/CD Pipelines for dbt Core
The major selling point of dbt cloud is its robust CI/CD pipeline support, but can you achieve the same without a commercial license from dbt labs, using only the open-source dbt core? dbt cloud natively designs the 'Slim CI' job pattern to test only the modified dbt models when someone creates a pull request in your dbt Git repository. The author explains how to implement the `Slim CI` pattern using dbt core.

HelloFresh: Data driven Snowflake optimisation at HelloFresh
Cost fit function is vital for the architecture decision, and often plays a significant role in the choice of technology and the success of an organization.
As we noticed in Instacart’s S1 filling, the Snowflake billing trends,

It would be an amazing case study to see how Instacart lower the Snowflake billing, on a similar line HelloFresh writes about its approach to drive the cost optimization in Snowflake.
https://engineering.hellofresh.com/data-driven-snowflake-optimisation-at-hellofresh-55a5b56aa9af
Alibaba: All You Need to Know About PyFlink
Python making its way to real-time stream processing, but I’ve seen less articles about the usage of PyFlink. Alibaba team writes a comprehensive article about PyFlink from the basics to managing the python dependencies.
https://www.alibabacloud.com/blog/all-you-need-to-know-about-pyflink_600306
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.