
Data Engineering Weekly #146
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. See how it works today.
Niels Claeys: Head-to-head comparison of 3 dbt SQL engines
The blog post compares benchmarks for the popular dbt SQL engines Trino, DuckDB, and Spark. However, one could argue this is not a head-to-head comparison since all three engines are designed for different hardware constraints. You can see that DuckDB throws OOM in a few benchmarks. But the key point here is if we can shrink the incremental data processing that can fit into a single machine, the greater the cost efficiency of data infrastructure.
https://medium.com/datamindedbe/head-to-head-comparison-of-dbt-sql-engines-497d71535881
Faith Lierheimer: An appropriately unhinged deep dive into Kimball's dimensional modeling primer
An interesting article about Kimball’s dimensional modeling. The blog narrates the key concepts of the Kimball model and a modern outlook on the concepts.
My take on the Kimball model is that All the techniques defined in the Kimball model, from bus matrix and confirmed dimensions to slowly changing dimensions, conceptually remain the same. All these concepts fundamentally try to achieve data consistency across the board. However, the logical and physical data modeling is designed when there is storage scarcity. We are no longer bound by the same storage limitation when these techniques become mainstream. We need to take these concepts but should rethink to fit the data model to take advantage of both the software and hardware advancements.
https://faithfacts.substack.com/p/an-appropriately-unhinged-deep-dive
PayPal: Scaling Kafka to Support PayPal’s Data Growth
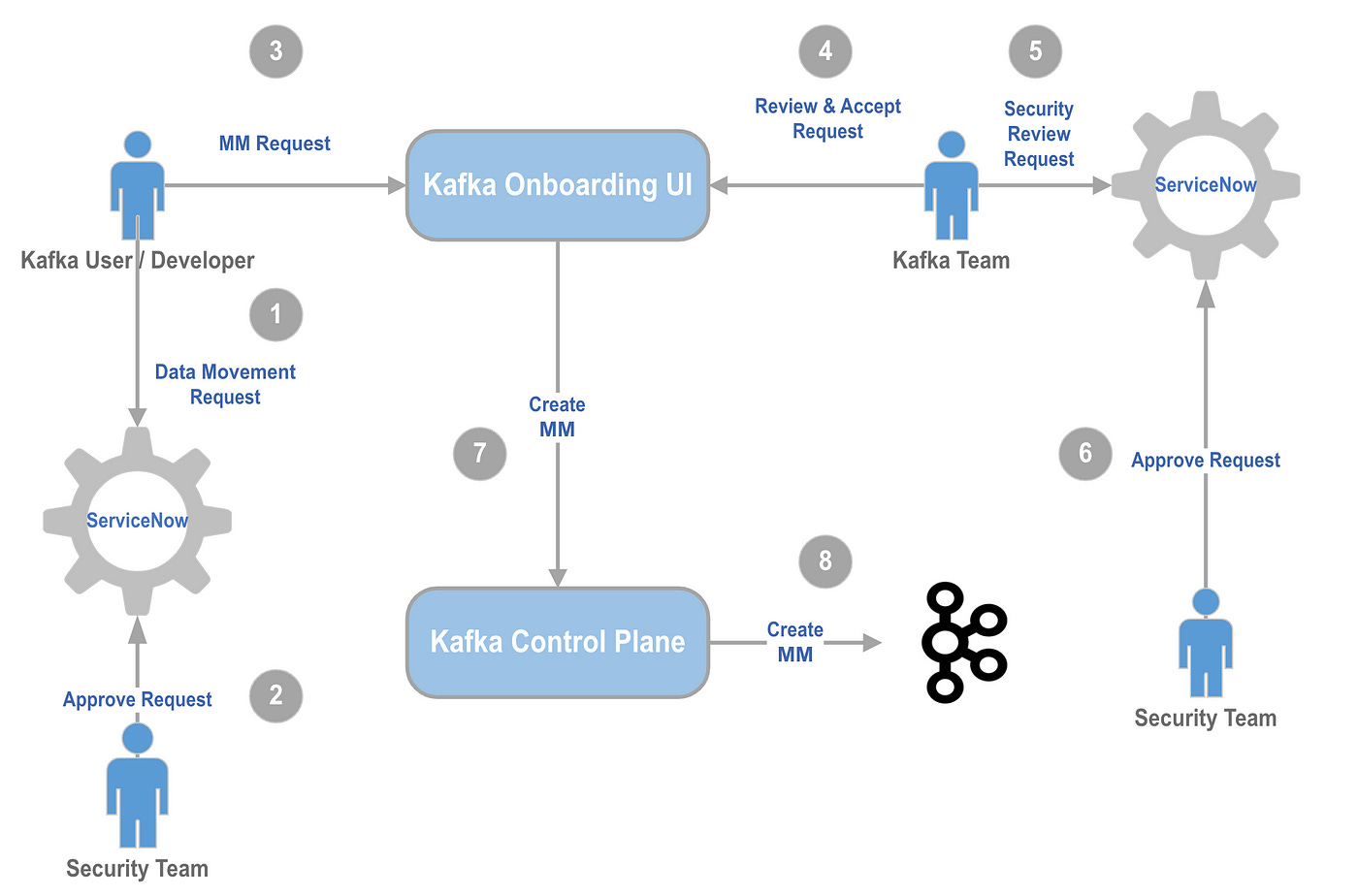
PayPal is running an impressive Kafka fleet, consisting of over 1,500 brokers that host over 20,000 topics and close to 2,000 Mirror Maker nodes that mirror the data among the clusters, offering 99.99% availability for the Kafka clusters. The blog narrates the cluster management practices focusing on ACL, config services, Kafka client SDKs, and QA environment.
https://medium.com/paypal-tech/scaling-kafka-to-support-paypals-data-growth-a0b4da420fab
Sponsored: Re: Govern
Data governance has often been misunderstood as a controlling bureaucratic process. But at its core, data governance isn’t about control. It’s about helping data teams work better together.
Atlan is hosting a virtual conference where modern data teams, like Nasdaq, HelloFresh, and SMG Swiss Marketplace Group, uncover how they are rethinking governance — and ushering in the data governance 3.0 era with automation, collaboration, and AI.
Check out the agenda and save your spot to join Re: Govern on October 05
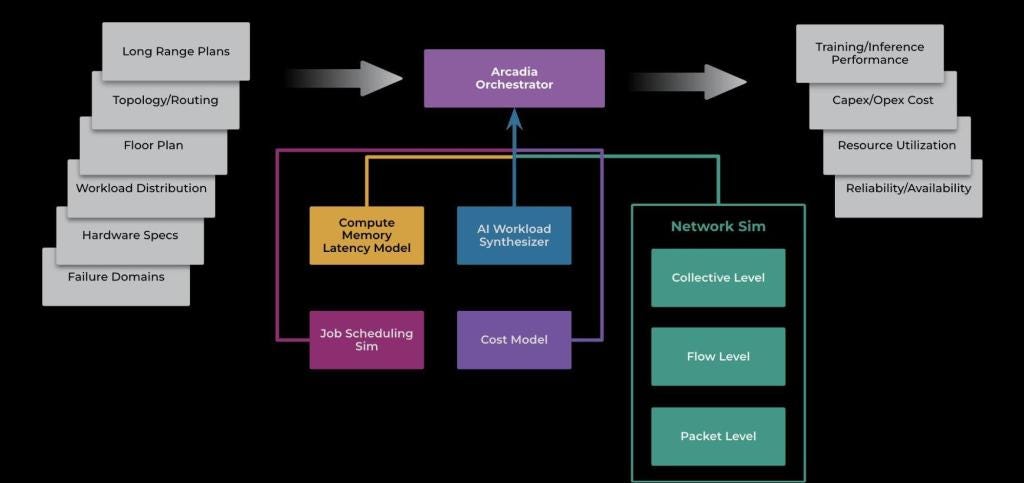
Meta: Arcadia - An end-to-end AI system performance simulator
The AI workload is a network and computationally intensive. Meta writes about Arcadia, a unified system that simulates AI training clusters' compute, memory, and network performance. The simulation of AI workload helps to accurately model the performance of compute, memory, and network components within large-scale AI training clusters.
Github: How to build an enterprise LLM application: Lessons from GitHub Copilot
Gihub shared how to build an enterprise LLM application from a product management perspective. It is an excellent read for anyone thinking of building LLM-powered product features.

Sponsored: You're invited to IMPACT - The Data Observability Summit | November 8, 2023
Interested in learning how some of the best teams achieve data & AI reliability at scale? Learn from today's top data leaders and architects at The Data Observability Summit how to build more trustworthy and reliable data & AI products with the latest technologies, processes, and strategies shaping our industry (yes, LLMs will be on the table).
Instacart: Scaling Productivity with Ava — Instacart’s Internal AI Assistant
Instacart writes about Ava, its internal productivity tool built on GPT 4. I love the prompt exchange feature where users can browse popular prompts, search for something specific, or create their own and share them with the rest of the company.
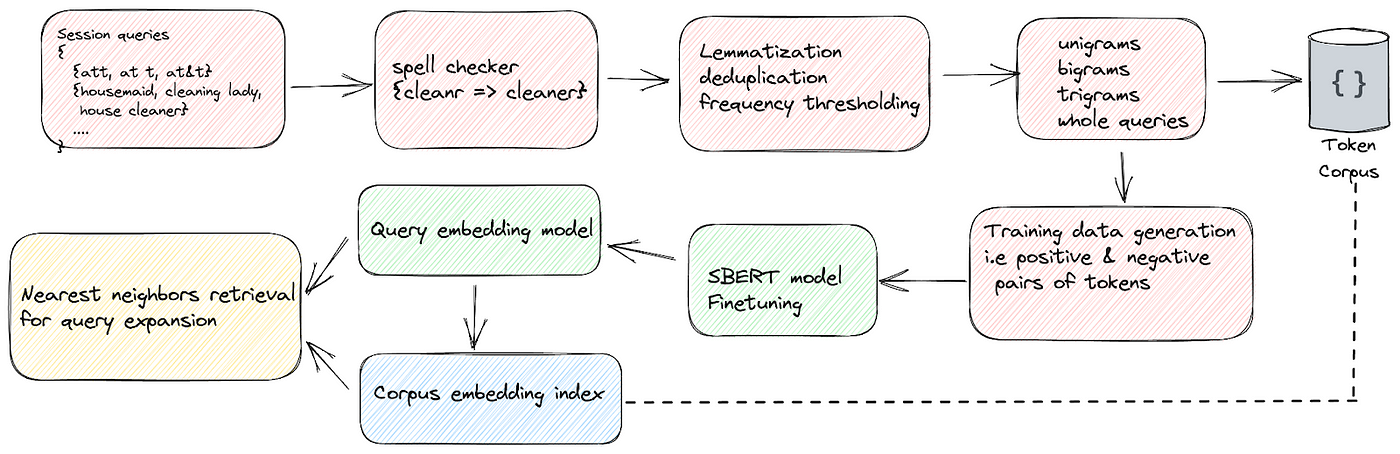
Nextdoor: From Pre-trained to Fine-tuned: Nextdoor’s Path to Effective Embedding Applications
Nextdoor writes about its embedding model journey from using pre-trained to fine-tuning the embedding applications. The blog discusses its usage with the pre-trained model and how it uses historical user interactions to fine-tune the embedding from unlabeled data and the labeled user feedback.
Sponsored: How To Create a Customer 360
“Without stitching each unique identifier to the user, systems and teams will wrongly assume that these three transactions are from three distinct users. Worse yet, you are unable to calculate — or inaccurately calculate — important computed traits like user_total_revenue because of the fragmented user identities.”
Customer 360 is, at the end of the day, a data problem. Here, the team at RudderStack details how to solve identity resolution in the warehouse and build user features to create activation-ready customer profiles.
https://www.rudderstack.com/blog/how-to-create-a-customer-360/
Etsy: The So-fine Real-time ML Paradigm
Etsy writes about its attempt to build a stateful real-time ML model training over a hackathon. The author acknowledges it is far from in the production but made enough case on the benefit of having an incremental model building. The initial estimation of saving $212k annual cloud cost and latency reduction from 40 hours to near real-time is an impactful case study for a hackathon project.

https://www.etsy.com/codeascraft/the-so-fine-real-time-ml-paradigm
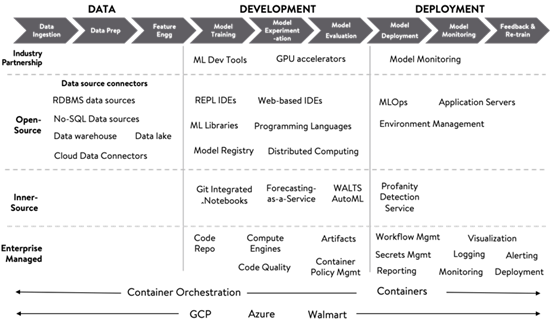
Walmart: Machine Learning Platform at Walmart
Walmart writes about its Machine Learning platform architecture following the best-of-the-breed model. The hybrid cloud platform builds on Kubernetes, Airflow, and a set of microservices. The platform focuses on data ingestion & preparation, feature engineering & model training, model experimentation, model evaluation & deployment with monitoring and governance.
https://medium.com/walmartglobaltech/machine-learning-platform-at-walmart-b06819825ef7
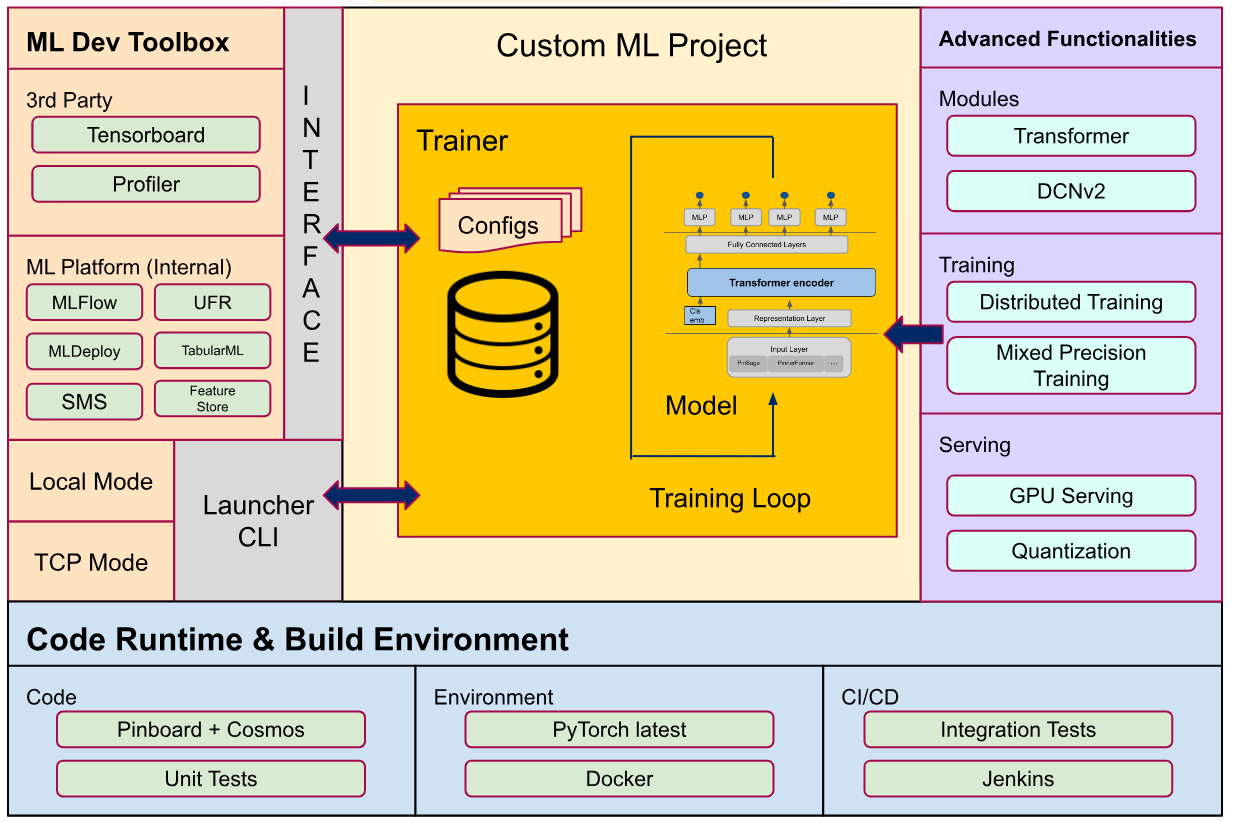
Pinterest: MLEnv: Standardizing ML at Pinterest Under One ML Engine to Accelerate Innovation
In 2021, ML was siloed at Pinterest with 10+ different ML frameworks relying on different deep learning frameworks, framework versions, and boilerplate logic to connect with our ML platform.
Pinterest discusses the challenges of running disjointed ML infrastructure in an organization and how it stale the innovation speed. The author narrates about MLEnv, a full-stack ML developer framework that aims to make ML engineers more productive by abstracting technical complexities irrelevant to ML modeling.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.