


Data Engineering Weekly #147
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. See how it works today.
Thoughtworks: Measuring the Value of a Data Catalog
The cost & effort value proportion for a Data Catalog implementation is always questionable in a large-scale data infrastructure. Thoughtworks, in combination with Adevinta, published a three-phase approach to measure the value of a data catalog.
Search and Discrimination!
Request Access to Data
Validate with Exploration

https://www.thoughtworks.com/insights/blog/data-strategy/measuring-the-value-of-a-data-catalog
Ramp: How Ramp Accelerated Machine Learning Development to Simplify Finance
Ramp writes about its machine learning infrastructure and the choice of Metaflow for running the ML workload. The exciting part of the article is about the comparison of Metaflow with Airflow and the decision not to use Airflow for ML workload.
Airflow isn’t meant to process the data. It instead, say, triggers a Spark job that processes the data. It’s the same with machine learning.

https://engineering.ramp.com/metaflow-production-ml
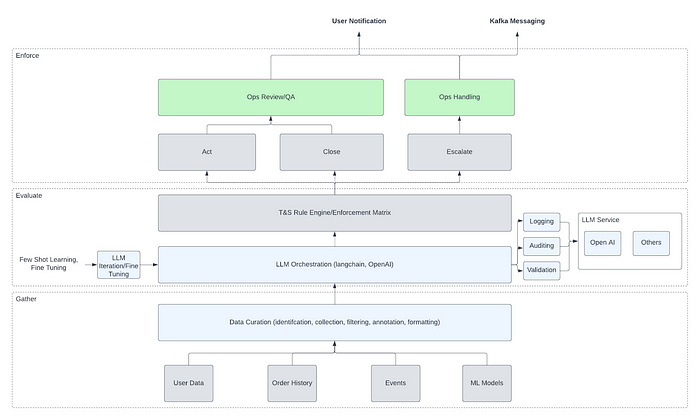
Whatnot: How Whatnot Utilizes Generative AI to Enhance Trust and Safety
Whatnot writes about its LLM usage to enrich multimodal content moderation, fulfillment, bidding irregularities, and general fraud protection. The blog talks about the limitations of rule engines and how LLM can enrich additional context to make the rule engine more effective.
Sponsored: You're invited to IMPACT - The Data Observability Summit | November 8, 2023
Interested in learning how some of the best teams achieve data & AI reliability at scale? Learn from today's top data leaders and architects at The Data Observability Summit on how to build more trustworthy and reliable data & AI products with the latest technologies, processes, and strategies shaping our industry (yes, LLMs will be on the table).
Microsoft: Why is it so hard to ship a simple LLM feature?
Though the possibility of LLM is very attractive, it is still hard to ship a simple LLM feature. The blog specifically focuses on the following areas of LLM implementations.
which model to pick
when LLM responses don’t match the desired output
when edge cases are pointy
the importance of implementing responsible AI
Atlassian: Responsible AI: Building Trustworthy AI Apps
LLM commoditizes the usage of AI features in the applications. It also brings a lot of attention to the Responsible AI. Atlassian writes about the importance of responsible AI and how an enterprise can think about it.
Your app and its documentation should be very clear about:
The models or third-party AI providers you're using.
The customer data that is being processed by AI and for what purpose?
The situations where users will interact with AI in your app.
https://blog.developer.atlassian.com/responsible-ai-building-trustworthy-ai-apps/
Sponsored: Re: Govern
Data governance has often been misunderstood as a controlling bureaucratic process. But at its core, data governance isn’t about control. It’s about helping data teams work better together.
Atlan is hosting a virtual conference where modern data teams, like Nasdaq, HelloFresh, and SMG Swiss Marketplace Group, uncover how they are rethinking governance — and ushering in the data governance 3.0 era with automation, collaboration, and AI.
Check out the agenda and save your spot to join Re: Govern on October 05
Pinterest: Last Mile Data Processing with Ray
Pinterest writes about its assessment of the ML developer velocity bottlenecks and delves deeper into the adoption of Ray, the open-source framework to scale AI and machine learning workloads. The blog is an excellent read about the “Scale First, Learn Last” problem in the data processing world.

https://medium.com/pinterest-engineering/last-mile-data-processing-with-ray-629affbf34ff
Leo Godin: Are You Using Elementary for DBT?
In the last couple of weeks, I heard a lot of buzz around the elementary package for dbt, though I’ve not tried it myself yet. The author lists some of the features of the elementary package, and the top 3 are,

Several different anomaly tests
Advanced schema tests
End-to-end pipeline view (Airflow, GitHub Actions, Looker, and Tableau)
https://leo-godin.medium.com/are-you-using-elementary-for-dbt-f9a56ecbef42
Sponsored: Announcing the RudderStack Kafka Source Integration
"The new integration makes it easy for data teams to get the most value out of their Kafka implementation by automatically forwarding streams to key business tools and standardizing schemas for data that is used in identity resolution and customer 360 projects."
Many teams struggle to effectively use their customer data from Kafka to drive value downstream because of the custom integration and pipeline work required. Those challenges are a thing of the past with RudderStack’s Kafka source integration.
https://www.rudderstack.com/blog/announcing-the-rudderstack-kafka-source-integration/
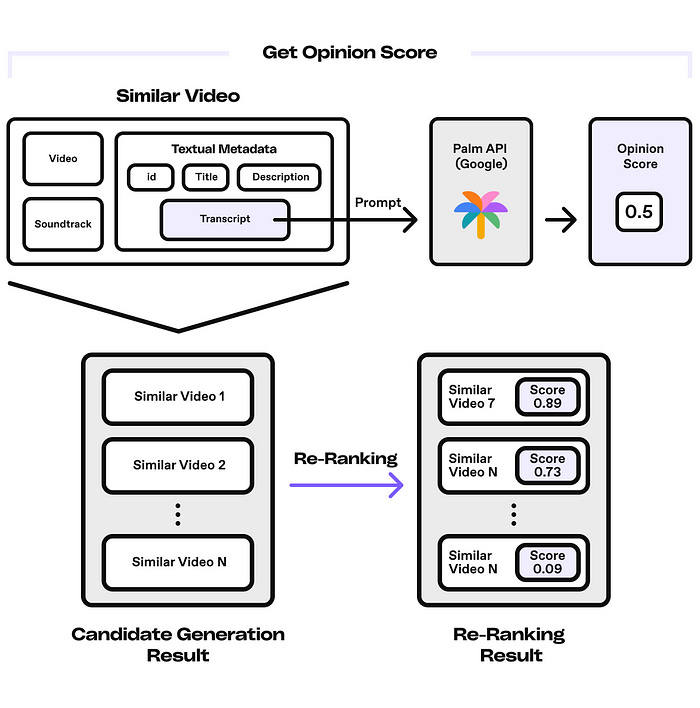
Dailymotion: Reinvent your recommender system using Vector Database and Opinion Mining
Dailymotion writes an exciting article about reinventing the recommender engine with vector databases. The blog narrates how it uses Open AI for candidate generation and Re-Ranking to build the opinion-based recommender system.
Jupyter Labs: Bringing Modern JavaScript to the Jupyter Notebook
The DataFrames are not only for Python!!! The Polars DataFrame support for JavaScript is a game changer. Jupyter Labs writes about the support for Deno Kernel, the first javascript language runtime with a built-in Jupyter kernel.
https://blog.jupyter.org/bringing-modern-javascript-to-the-jupyter-notebook-fc998095081e
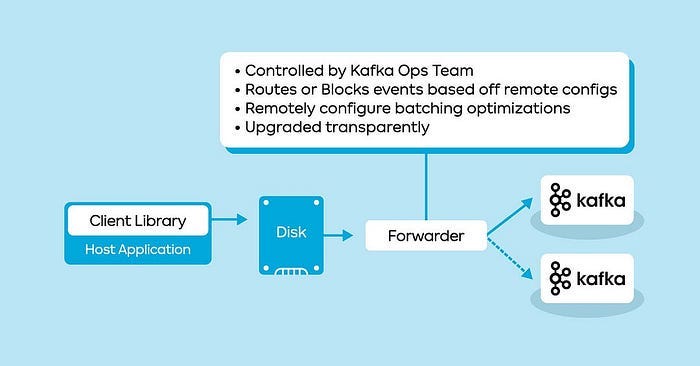
Agoda: How Agoda manages 1.8 trillion Events per day on Kafka
Agoda writes about its Kafka infrastructure by adopting a control plane-style architecture model. The message forwarder style architecture becomes increasingly common as tightly coupling the Kafka topic with the producer increases the operational burden.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.