
Data Engineering Weekly #148
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. See how it works today.
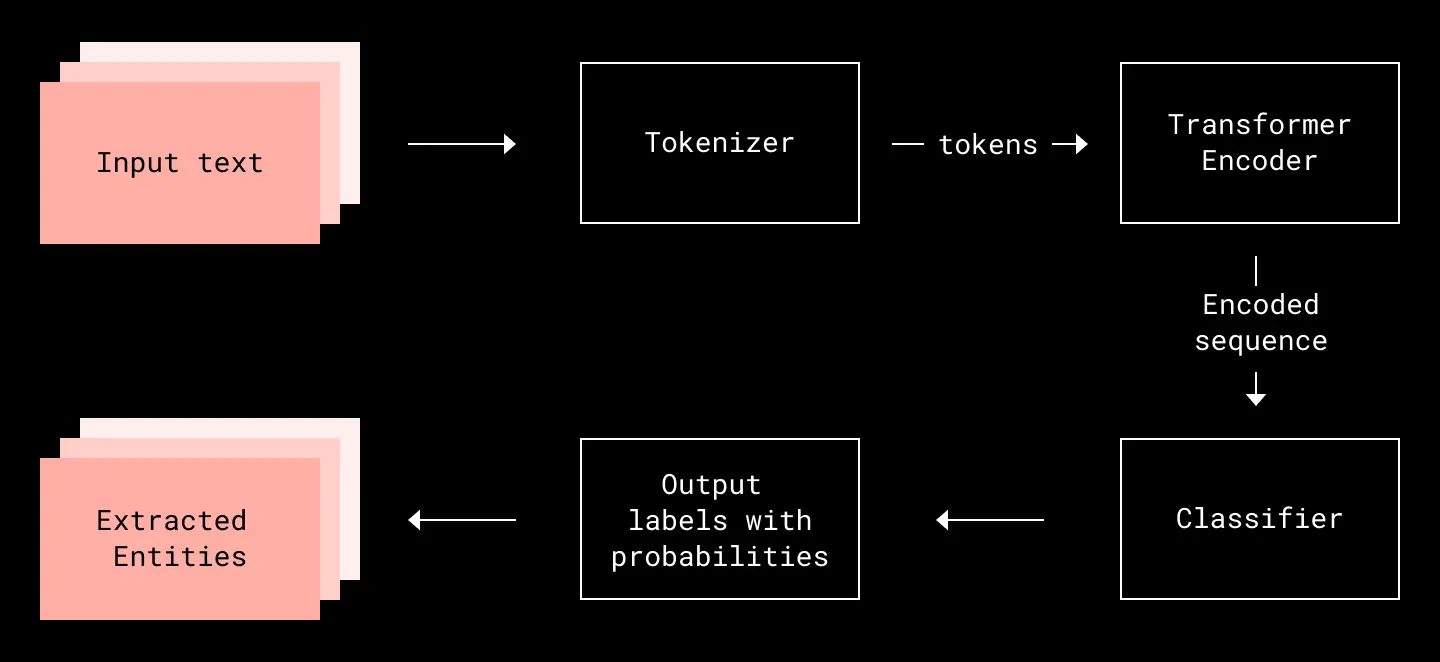
Dropbox: Is this a date? Using ML to identify date formats in file names
Naming things is always one of the hardest problems in computer science. We all know how messy the confluence page or Google Doc directory can be, where it is hard to search and find a piece of information. Dropbox writes an exciting approach to applying machine learning to identify the date formats in file names to standardize naming conventions.
https://dropbox.tech/machine-learning/using-ml-to-identify-date-formats-in-file-names
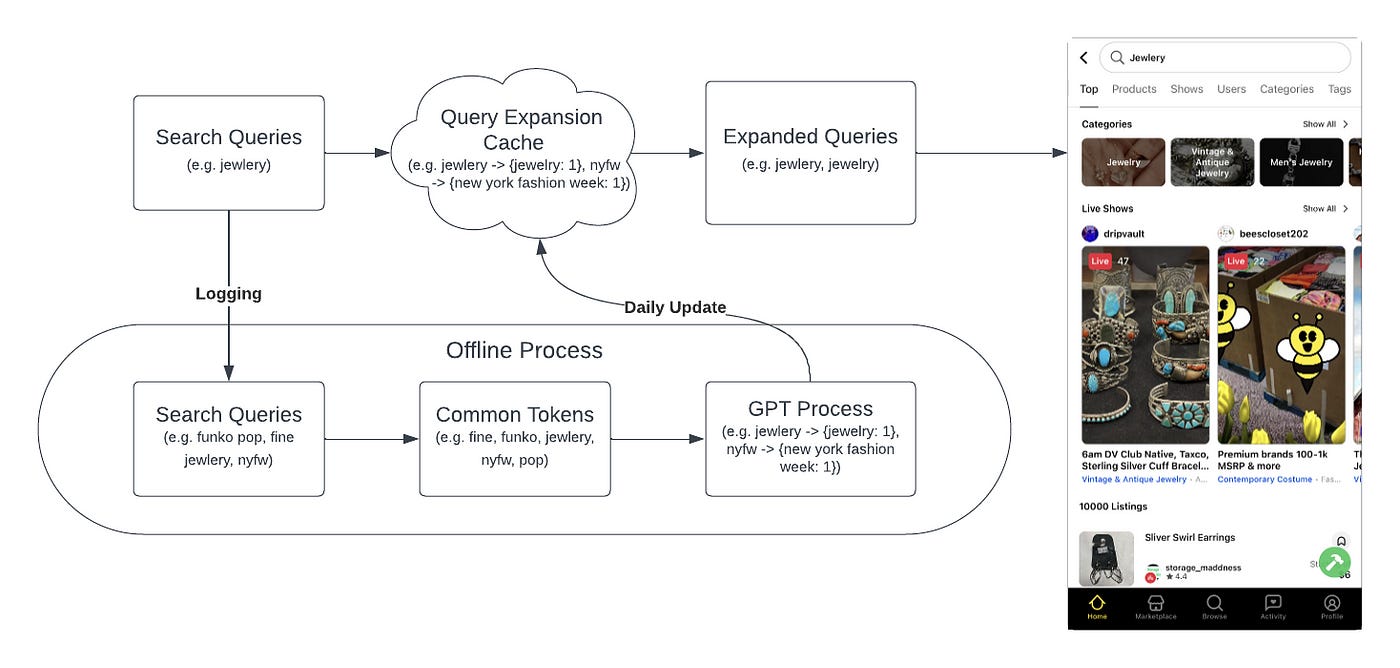
Whatnot: Enhancing Search Using Large Language Models
Search functionality undeniably plays a pivotal role in the user experience of e-commerce apps. Whatnot writes about using LLM for query expansion, auto-correct spellings, and the possibility of expanding to a semantic query expansion.
https://medium.com/whatnot-engineering/enhancing-search-using-large-language-models-f9dcb988bdb9
Agoda: How to Design and Maintain a High-Performing Data Pipeline
I liked this article because it covers the basic 101 of data pipelines on maintaining a healthy infrastructure. The author talks about the founding layer to focus on healthy pipelines such as,
Data: where is the data stored? What is the data behavior?
Resource Used: how many resources should be allocated for our data pipeline?
Partitioning: how should we partition our table (in Hadoop)?
Job Scheduling: how frequently should our data pipeline run?
Data Dependency: does the pipeline depend on the data of other tables?

Criteo: Recommender systems need a user model
Criteo makes a strong case for recommender system problems as user preference rather than pattern recognition. The blog talks about the current state of the recsys, ongoing work, and the basic user model recommendation.
Instead of approaching the Recommender System problem as a pattern recognition task, we should view it as figuring out the user’s preferences and then giving them the best browsing experience.

https://medium.com/criteo-engineering/recommender-systems-need-a-user-model-c3b3790311bf
Sponsored: You're Invited! Register for IMPACT: The Data Observability Summit | November 8, 2023
Announcing keynotes from three data & AI pioneers, Moneyball expert Billy Beane, poker legend Annie Duke, and SVP of Product Management at Salesforce AI, Nga Phan! Register to learn how to build more trustworthy and reliable data & AI products with the latest technologies, processes, and strategies shaping our industry (yes, LLMs will be on the table).
Line: Fixing issues we've faced while migrating from HiveQL to Spark SQL
Love it or Hate it, Hive is one of the formidable SQL query engines that changed the big data landscape. In theory, migrating from HiveQL to Spark SQL is just switching the execution engine, yet it is not that simple. Line shared an excellent case study of complications around moving HiveQL and Spark SQL and how the team addresses each issue systematically.
https://engineering.linecorp.com/en/blog/from-hiveql-to-sparksql-troubleshooting
Pinterest: Lessons from debugging a tricky direct memory leak
The blog is a classic example of debugging non-deterministic application errors in production. The blog narrates the approach, first focusing on bandaging the problem to buy more time and then simulating the problem by each layer to narrow down the issue. The systematic debugging approach explained in the blog can be applied to any engineering part, so I highly recommend reading this blog.

Vinted: Vinted Search Scaling Chapter 7: Rebuilding search indexing pipeline
The search index pipeline is my favorite kind of data pipeline problem to solve. The Vinted Engineering blog talks about the current state of the search index pipeline with a 7-minute wait time for live indexing and the weeks of waiting time for backfilling and how the CDC with Flink pipeline reduces the indexing time and improves the efficiency of the search pipeline.

https://vinted.engineering/2023/09/25/search-indexing-pipeline/
Sponsored: Announcing RudderStack's Real-time Activation API
"After your Profiles projects complete running, your customer 360 data is automatically synced to a Redis instance through a RudderStack reverse ETL job. The Activation API sits on top of that Redis instance."
RudderStack just released its Activation API. The API gives you access to the Customer 360 data from your RudderStack Profiles projects, so you can bring real-time personalization into any user experience. Learn more and reach out for early access on the blog.
https://www.rudderstack.com/blog/announcing-rudderstacks-activation-api/
Tomonori Masui: Entity Resolution - Identifying Real-World Entities in Noisy Data
Entity resolution is an integral part of a data pipeline every data engineer encounters daily. Joining the sales data from Salesforce, marketing data from Marketo, and the product data from Clickstream is a good enough case where entity resolution will play a critical role. The blog is another “Go Back to Basics” for me, which sketches all the available techniques for entity resolution.

Amit Singh Rathore: Data Engineering — On Call
On Call reveals the true nature of the system's stability, and data engineering is no different from any other software infrastructure. What I liked about the articles, the author was true to himself and shared the lessons learned and the thought process to fix the oncall issues in this six-part blog series. I wish more data engineers would start sharing their on-call experience soon.
Ha Anh Vu: Making design decisions for ClickHouse as a core storage backend in Jaeger
There are a lot of similarities between observability and data engineering if you watch closely. Think of tracing as a special case of an event, with a strongly typed & fixed schema span, then the world of data engineering practices fully applicable to observability engineering. Jaeger shares such a case with the choice of ClickHouse, a columnar storage engine for a data warehouse as a backend for storing tracing.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.