
Data Engineering Weekly #149
The Weekly Data Engineering Newsletter


RudderStack is the Warehouse Native CDP, built to help data teams deliver value across the entire data activation lifecycle, from collection to unification and activation. Visit rudderstack.com to learn more.
LinkedIn: Revolutionizing Real-Time Streaming Processing: 4 Trillion Events Daily at LinkedIn
There was a recent discussion about why Apache Beam is not widely adopted or why there are few case studies around it. The promise of a unified programming model with a pluggable runtime engine (samza, Spark & Flink) is certainly appealing. LinkedIn shares its success story of using Apache Beam across business use cases.

Criteo: How we compute data lineage at Criteo

Data lineage is essential in operating a data pipeline, yet it is hard to build. The explosion of modern data stacks made it much harder to build. Criteo shares its experience building data lineage from data stewards manually mapping the relationship to automation with pattern recognition.
https://medium.com/criteo-engineering/how-we-compute-data-lineage-at-criteo-b3f09fc5c577
Gusto: Data Engineering on People Data

Gusto writes about the infrastructure components of building internal people analytics by combining SaaS products like Workday, GreenHouse, and other learning management systems. Though the blog describes a standard integration pattern, there are a couple of common patterns you can see across many SaaS integrations.
The multi-hop system integrations to handle access control of the sensitive data [WorkDay → Okta → Active Directory]
The complexity of handling standard objects vs custom objects.
https://engineering.gusto.com/data-engineering-on-people-data/
BlaBlaCar: 11 lessons learned managing a Data Platform team within a data mesh
It is exciting to see some real-world case studies about adopting the Data Mesh pattern. BlaBlaCar shares its experience bringing Data Mesh into its organization, the human factors around it, and the organizational structure for it. I would love to see how the technical architecture pattern differs from the standard data infrastructure and what additional components are required to build for data mesh soon.
Sponsored: You're invited to IMPACT - The Data Observability Summit | November 8, 2023
Interested in learning how some of the best teams achieve data & AI reliability at scale? Learn from today's top data leaders and architects at The Data Observability Summit on how to build more trustworthy and reliable data & AI products with the latest technologies, processes, and strategies shaping our industry (yes, LLMs will be on the table).
Google Research: Distilling step-by-step: Outperforming larger language models with less training data and smaller model sizes
LLMs are challenging to deploy for real-world applications due to their sheer size. For instance, serving a single 175 billion LLM requires at least 350GB of GPU memory using specialized infrastructure. Such computational requirements are inaccessible for many research teams, especially for applications that require low latency performance. Google Research introduce distilling step-by-step, a new simple mechanism that allows us to train smaller task-specific models with much less training data than required by standard fine-tuning or distillation approaches that outperform few-shot prompted LLMs’ performance.
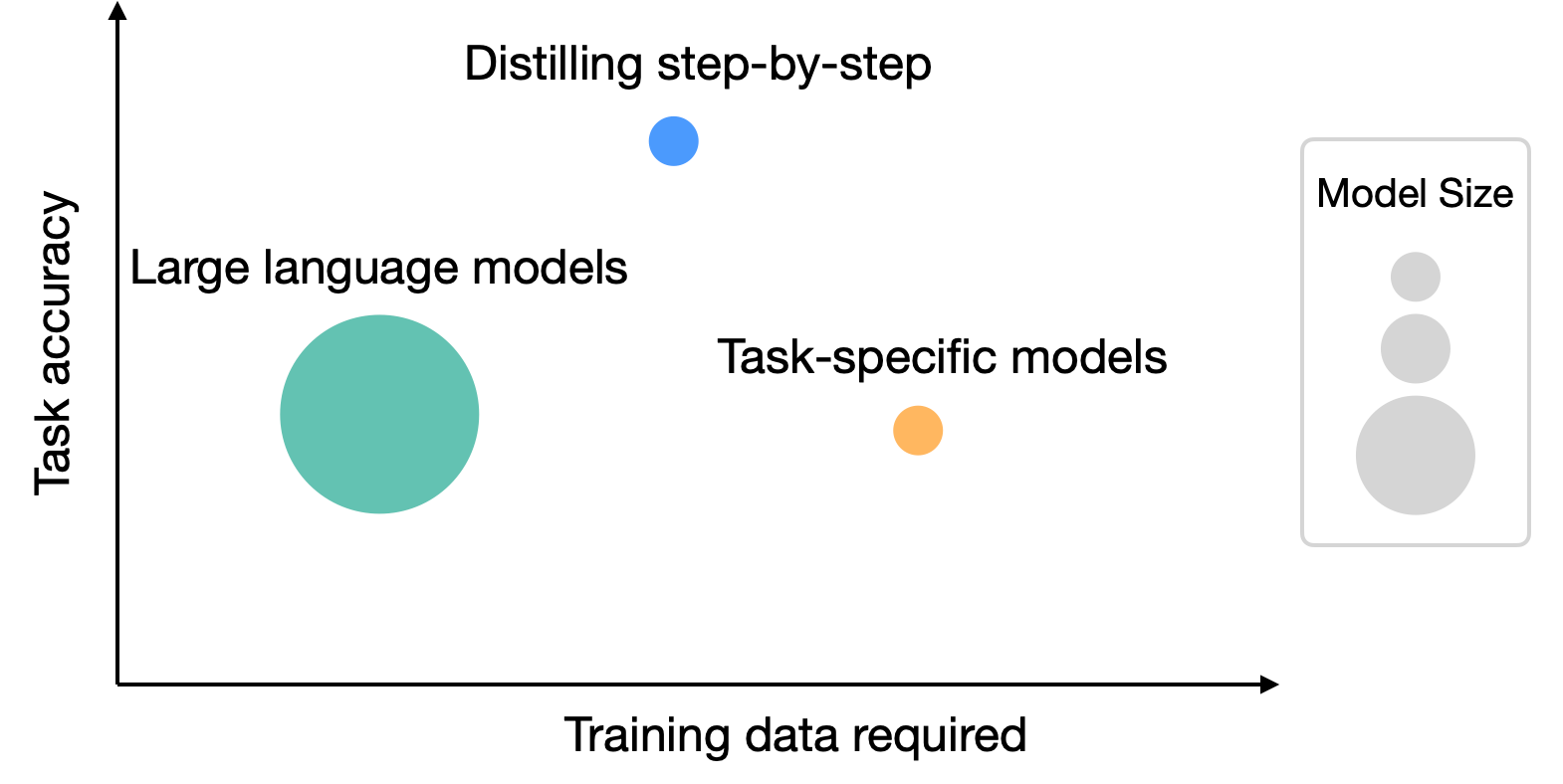
https://blog.research.google/2023/09/distilling-step-by-step-outperforming.html
Grab: LLM-powered data classification for data entities at scale
The impact of LLM in the data management space slowly unfolding. The sheer volume of data making it impossible to manage cataloging at scale. Grab shares its story of how it uses LLM-powered data classification for data entities at scale.

https://engineering.grab.com/llm-powered-data-classification
Microsoft: How Large Language Models work - From zero to ChatGPT
We started to see LLM-powered application started to make impact, and slowly entering into the production-scale applications. But how does the Large Language Model works? The author explains the basics of LLM.

https://medium.com/data-science-at-microsoft/how-large-language-models-work-91c362f5b78f
Sponsored: Announcing the compliance toolkit: painless customer data compliance in one platform
"This reality puts data teams in the middle of two conflicting pressures. On one end, the mandate to be compliant is clear and direct. On the other end, the demand for velocity and business growth is loud and clear."
RudderStack just introduced a set of features that simplify compliance across the entire data lifecycle. The compliance toolkits enable you to manage consent, collection, storage, and deletion all from one central platform. Read the announcement for a detailed breakdown of the toolkit components.
Spotify: Introducing Voyager: Spotify’s New Nearest-Neighbor Search Library
The nearest-neighbor algorithm, is a fundamental method in machine learning and pattern recognition. nearest neighbor algorithm comes handy in classification & regression tasks, recommender system, and anomaly detection. Spotify writes about its new battle tested nearest-neighbor search library Voyager, and guess what its open-source.
Picnic: The Art of Master Data Management at Picnic
Master Data Management, to my surprise rarely discussed in the modern data stack era, where customer data platform takes the center stage. Picnic writes about its MDM journey by adopting Salesforce cloud data platform.
https://blog.picnic.nl/the-art-of-master-data-management-at-picnic-48b5cf978221
Philippe Dagher: Ray vs Spark — The Future of Distributed Computing
Indeed, there is no real big competition for Apache Spark for a long time. The recent Ponder acquisition by Snowflake triggers interesting conversation around the alternate computing platform for Apache Spark. The author compares Ray vs Spark as the future of distributed computing.
https://medium.com/@nasdag/ray-vs-spark-the-future-of-distributed-computing-b10b9caa5b82
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.