
Data Engineering Weekly #150
The Weekly Data Engineering Newsletter


RudderStack is the Warehouse Native CDP, built to help data teams deliver value across the entire data activation lifecycle, from collection to unification and activation. Visit rudderstack.com to learn more.
Netflix: Streaming SQL in Data Mesh
Learnings from our journey
In hindsight, we wish we had invested in enabling Flink SQL on the DataMesh platform much earlier. If we had the Data Mesh SQL Processor earlier, we would’ve been able to avoid spending engineering resources to build smaller building blocks such as the Union Processor, Column Rename Processor, Projection, and Filtering Processor.
That is a very wise quote from the Netflix engineering team. In the past, I tried to caution people trying to build another SQL-like abstraction but can’t help but burn the finger before realizing how hard it is to implement simpler abstractions like SQL. The blog is a classic case study for data engineers who like to build SQL-like abstractions.

https://netflixtechblog.com/streaming-sql-in-data-mesh-0d83f5a00d08
Dropbox: Putting everything in its right place with ML-powered file organization
The impact of machine learning on productivity and communication platforms like Dropbox is undeniable. Dropbox writes one such case study about implementing an ML-powered file organization named “Smart Move.”

https://engineering.hometogo.com/a-b-testing-at-hometogo-when-and-why-we-do-it-52ef063eae08
Meta: Automating data removal
Deleting is the hardest part of data management, and Meta writes about its internal system design to automate the data removal process. The step involves continuous monitoring, flagging & alerting, and auto-deletion.

https://engineering.fb.com/2023/10/31/data-infrastructure/automating-data-removal/
HomeToGo: A/B testing at HomeToGo - When and why we do it
Experimentation is a cultural thing of an organization. Either you believe in experimentation, or you don’t believe in it. HomeToGo writes about the classification of user-related A/B testing and when it makes sense to test.
https://engineering.hometogo.com/a-b-testing-at-hometogo-when-and-why-we-do-it-52ef063eae08
Sponsored: You're invited to IMPACT - The Data Observability Summit | November 8, 2023
Interested in learning how some of the best teams achieve data & AI reliability at scale? Learn from today's top data leaders and architects at The Data Observability Summit on how to build more trustworthy and reliable data & AI products with the latest technologies, processes, and strategies shaping our industry (yes, LLMs will be on the table).
Davis Treybig: S3 as the universal infrastructure backend
S3 has become the backbone of internet storage, offering durability, availability, and scalability that few can match. Increasingly, S3 is used as the core persistence layer for infrastructure services. The author explores S3 as a persistent layer architecture, its challenges, and infrastructure startup opportunities built on top of S3.
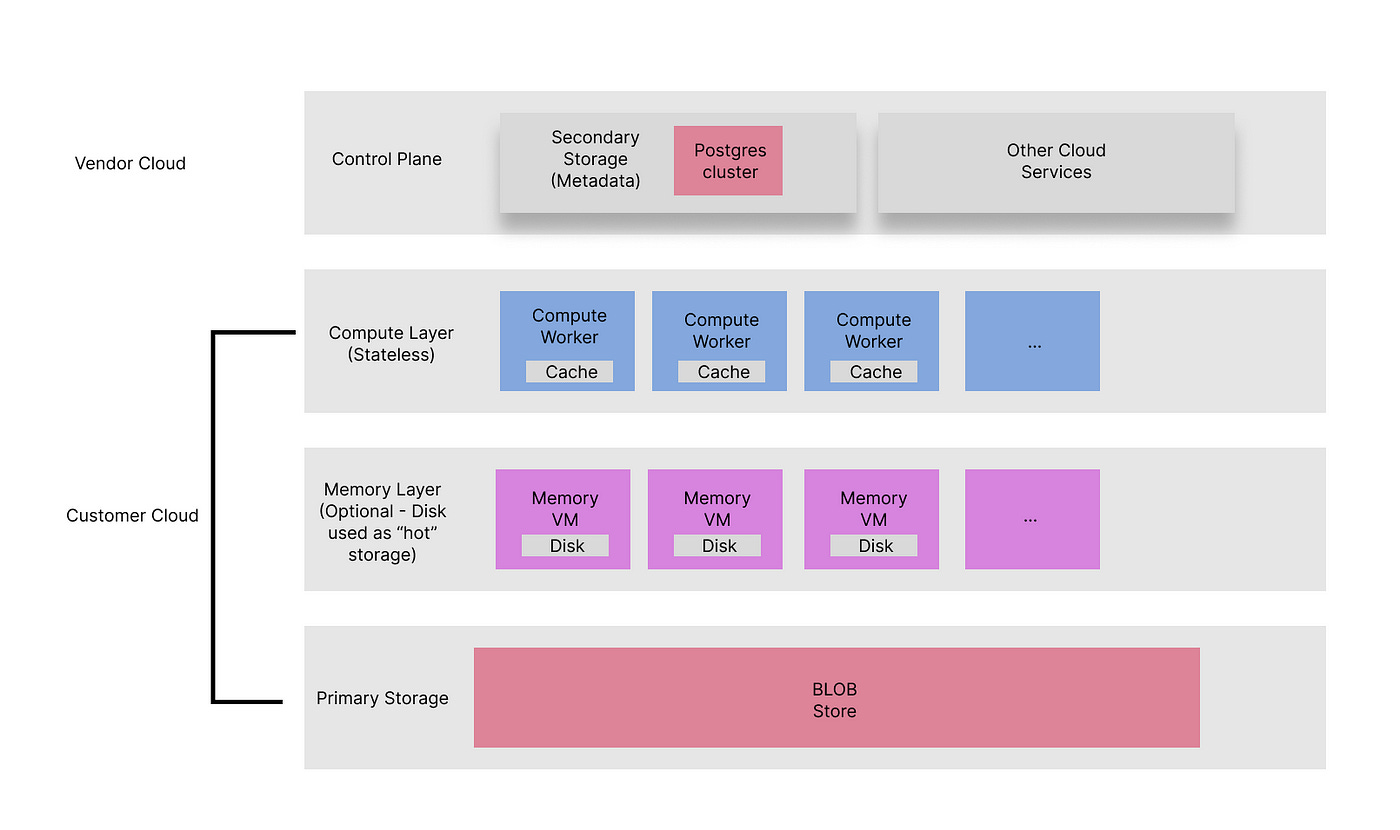
https://medium.com/innovationendeavors/s3-as-the-universal-infrastructure-backend-a104a8cc6991
BlaBlaCar: Controlling our Data Platform Costs at BlaBlaCar
Cloud data warehouses bring flexibility and user-friendliness with additional infrastructure costs. The lack of visibility is often the frequent culprit in all surprise cloud costs. BlaBlaCar writes about system design and patterns for controlling the data platform cost on top of BigQuery.
https://medium.com/blablacar/controlling-our-data-platform-costs-at-blablacar-b05a47926414
Sponsored: Announcing the compliance toolkit: painless customer data compliance in one platform
"This reality puts data teams in the middle of two conflicting pressures. On one end, the mandate to be compliant is clear and direct. On the other end, the demand for velocity and business growth is loud and clear."
RudderStack just introduced a set of features that simplify compliance across the entire data lifecycle. The compliance toolkits enable you to manage consent, collection, storage, and deletion all from one central platform. Read the announcement for a detailed breakdown of the toolkit components.
Google AI: Grammar checking at Google Search scale
Grammar checking is essential for writing, and I use it extensively. Google writes an excellent blog on an efficient grammar correction model based on the state-of-the-art EdiT5 model architecture. The blog is an excellent source for designing large-scale systems.

https://blog.research.google/2023/10/grammar-checking-at-google-search-scale.html
Github: The architecture of today’s LLM applications
LLM is certainly becoming an integral part of the modern application architecture. Github writes about the modern architectural pattern for LLM applications and the five steps to building an LLM application.

Microsoft: Challenges of building LLM apps, Building Copilots
Though LLM is becoming part of the architecture, the challenges in building LLM apps remain the same. In this two-part series, Microsft explores the challenges of building LLM apps.
Microsoft: Generative AI for Beginners
I came across this Github and found it an excellent resource if you are a beginner in the Gen-AI space. The Github repo contains 12 lessons, each covering a key aspect of Generative AI principles and application development.

https://github.com/microsoft/generative-ai-for-beginners
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.