
Data Engineering Weekly #152
The Weekly Data Engineering Newsletter


RudderStack, one of the leading alternatives to Segment, is the Warehouse Native CDP, built to help data teams deliver value across the entire data activation lifecycle, from collection to unification and activation. Visit rudderstack.com to learn more.
Capital One: Insights on building a data strategy to drive business value
One of the hotly debated and many companies struggling with is to build an agile data strategy to drive business value. There is no shortage of data, but data management is still hard, which requires skillful execution and alignment across the org. Capital One shares its view as part of a case study from Harvard Business Review.
https://www.capitalone.com/tech/cloud/data-transformation-emerging-technologies/
Thoughtworks: Anonymesh - Data sharing meets privacy and security
During my stay in India, I had multiple conversations with fintech data practitioners in India, and many pointed out the challenges with data sharing while preserving privacy & security. Although a range of privacy techniques exist, no ‘one size fits all’ solution exists. Thoughtworks discusses Anonymesh architecture with case studies on how it is implemented.

https://www.thoughtworks.com/insights/articles/anonymesh-data-sharing-meets-privacy-and-security
Evidently: ML system design - 300 case studies to learn from
An amazing compilation of ML system design articles from various companies. I can’t wait for someone to build a bot around it!!!
https://www.evidentlyai.com/ml-system-design
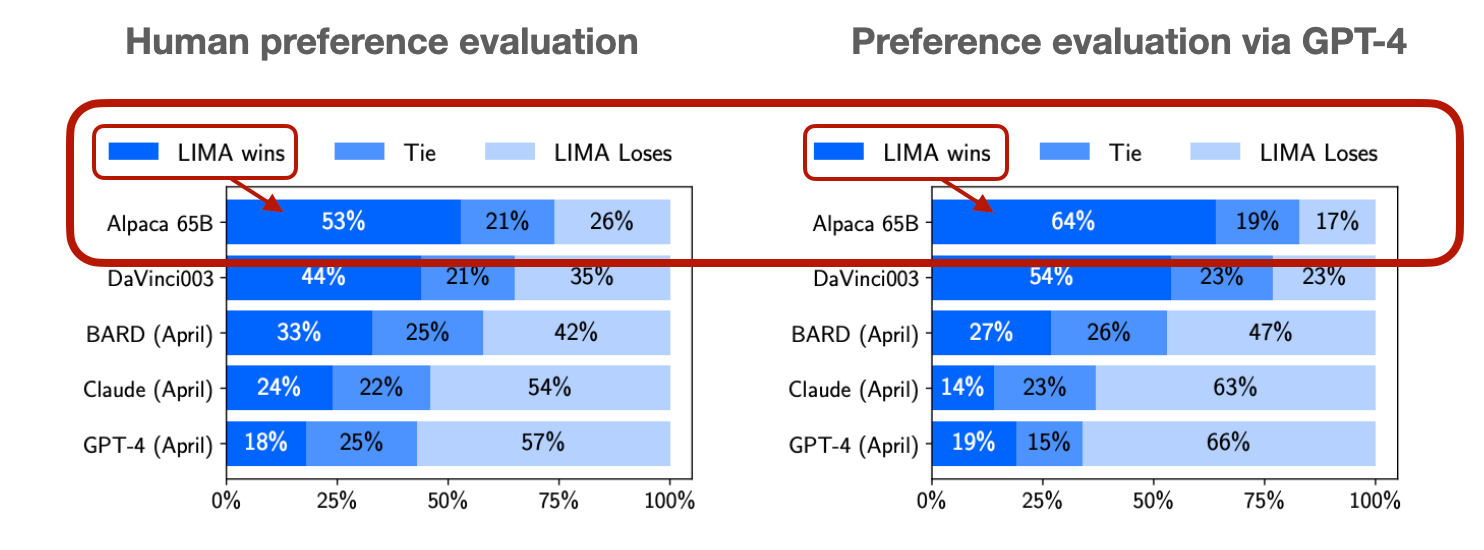
Research Paper: ChatGPT’s First Anniversary - Are Open-Source Large Language Models Catching Up?
The paper “ChatGPT’s First Anniversary: Are Open-Source Large Language Models Catching up?” provides an extensive overview of the advancements in open-source Large Language Models (LLMs) compared to ChatGPT. It discusses the rapid progress in open-source LLMs, noting that they are beginning to match or surpass ChatGPT in various domains. The study includes a comprehensive analysis of different LLMs across multiple benchmarks and tasks, highlighting areas where open-source models excel or lag. Additionally, it covers the development trends, best practices in training open-source LLMs, potential issues, and the implications for research and business sectors.
https://arxiv.org/pdf/2311.16989.pdf
Sponsored: Rudderstack - Your AI/ML success starts with data quality
When data science teams get bogged down with data quality issues, pressure to show some kind of value increases, so they begin to prioritize projects based on data availability instead of impact and business need.
Lackluster AI/ML results often stem from poor data quality. Here, the team at RudderStack unpacks the problem, shares best practices for solving it at the source, and details how superior data quality enables data science teams to do their best work.
https://www.rudderstack.com/blog/your-aiml-success-starts-with-data-quality/
GitHub: How we’re experimenting with LLMs to evolve GitHub Copilot
Developers are increasingly adopting AI to increase productivity, and GitHub Copilor plays a crucial role. GitHub writes about its experimentation strategy with LLM to evolve GitHub Copilot. The key principles are,
Predictable
Tolerable
Steerable
Verifiable
https://github.blog/2023-12-06-how-were-experimenting-with-llms-to-evolve-github-copilot/
Ray vs. Dask: Lessons learned serving 240k models per day in real-time
When I asked why Spark had no viable alternative, folks pointed me to Ray and Dask.

The blog is an excellent comparison study of Ray vs. Dask’s performance. Note that the comparison study is on a specific set of features.
Sebastian Raschka: Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation)
The author discusses Low-rank adaptation (LoRA), an efficient method for finetuning large language models (LLMs) with limited computing. Experiments on a 7B parameter LLM showed LoRA enables fast finetuning on 1 GPU with surprising consistency. Tuning hyperparameters like rank and dataset diversity is key. Quantized LoRA trades some performance for 33% memory savings.
https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms
Dipankar Mazumdar: OneTable- Interoperability for Apache Hudi, Iceberg & Delta Lake
One of the 2024 predictions is that “The Great Battle of LakeHouses” will amplify greatly in 2024. As a data practitioner, I feel OneTable is one of the critical projects in the LakeHouse era. The OneTable, as promised in this article, enables seamless interoperability among Hudi, Iceberg, and Delta Lake. From a data architecture point of view, this enables a lot of flexibility in integrating multiple systems. The author discusses the OneTable sync mechanism among all three major LakeHouse formats in this blog.

Netflix: Diving Deeper into Psyberg: Stateless vs Stateful Data Processing
Netflix wrote a deep-dive article about Psyberg’s incremental data processing pipeline framework. The blog discusses Psyberg’s two operational models, stateless & stateful data processing.
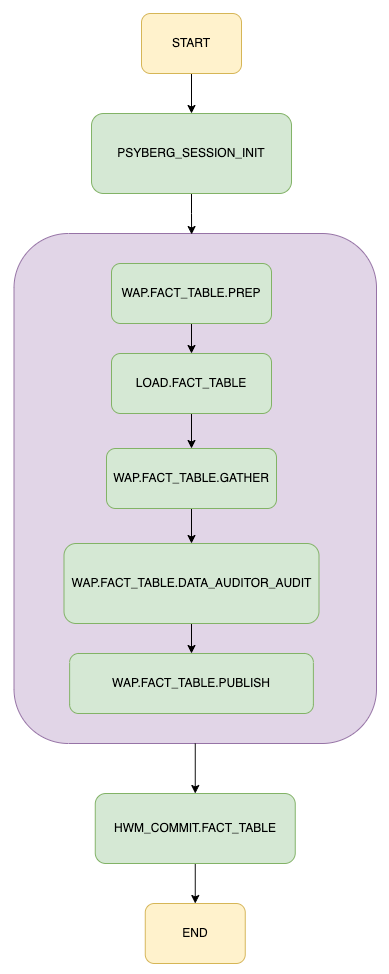
Key aspects of Psyberg:
The initialization phase computes a range of data that needs reprocessing for a pipeline based on parameters. Stores metadata to utilize later.
Write Audit Publish (WAP) process validates writes before publishing. Handles appending or overwriting with late data automatically based on stateless or stateful mode.
Audits using Psyberg metadata ensure data integrity and completeness.
A high watermark update marks the latest data timestamp, so the next run processes only new changes.
Agoda: Featureflow- Democratizing ML for Agoda
Agility and Experimentation are the key design principles while designing ML infrastructure. Agoda shares the same value and discusses how it builds Featureflow, a robust machine-learning pipeline designed to achieve the new S-curve of experimentation velocity

https://medium.com/agoda-engineering/featureflow-democratizing-ml-for-agoda-aec7a6c45b30
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.