


Data Engineering Weekly #155
The Weekly Data Engineering Newsletter


RudderStack is the Warehouse Native CDP, built to help data teams deliver value across the entire data activation lifecycle, from collection to unification and activation. Visit rudderstack.com to learn more.
Sebastian Raschka: Ten Noteworthy AI Research Papers of 2023
It is an eventful 2023 in machine learning and AI research. The author summarizes the top 10 AI-specific research papers in 2023.

https://magazine.sebastianraschka.com/p/10-ai-research-papers-2023
Dan Luu: How bad are search results? Let's compare Google, Bing, Marginalia, Kagi, Mwmbl, and ChatGPT.
Interesting article on the impact of search engine optimization (SEO) on the quality of search engine results. The article claims that modern search engines are significantly affected by SEO strategies, with search results being biased towards those who can profit the most from specific terms.

Ben Rogojan: Centralized vs. Decentralized vs. Federated Data Teams
Organizing the data team to maximize data-driven organization is an evergreen industry issue. TBH, centralized or decentralized depends on who has more influence in an organization. The author summarized the pros and cons of various data team structures in an organization.
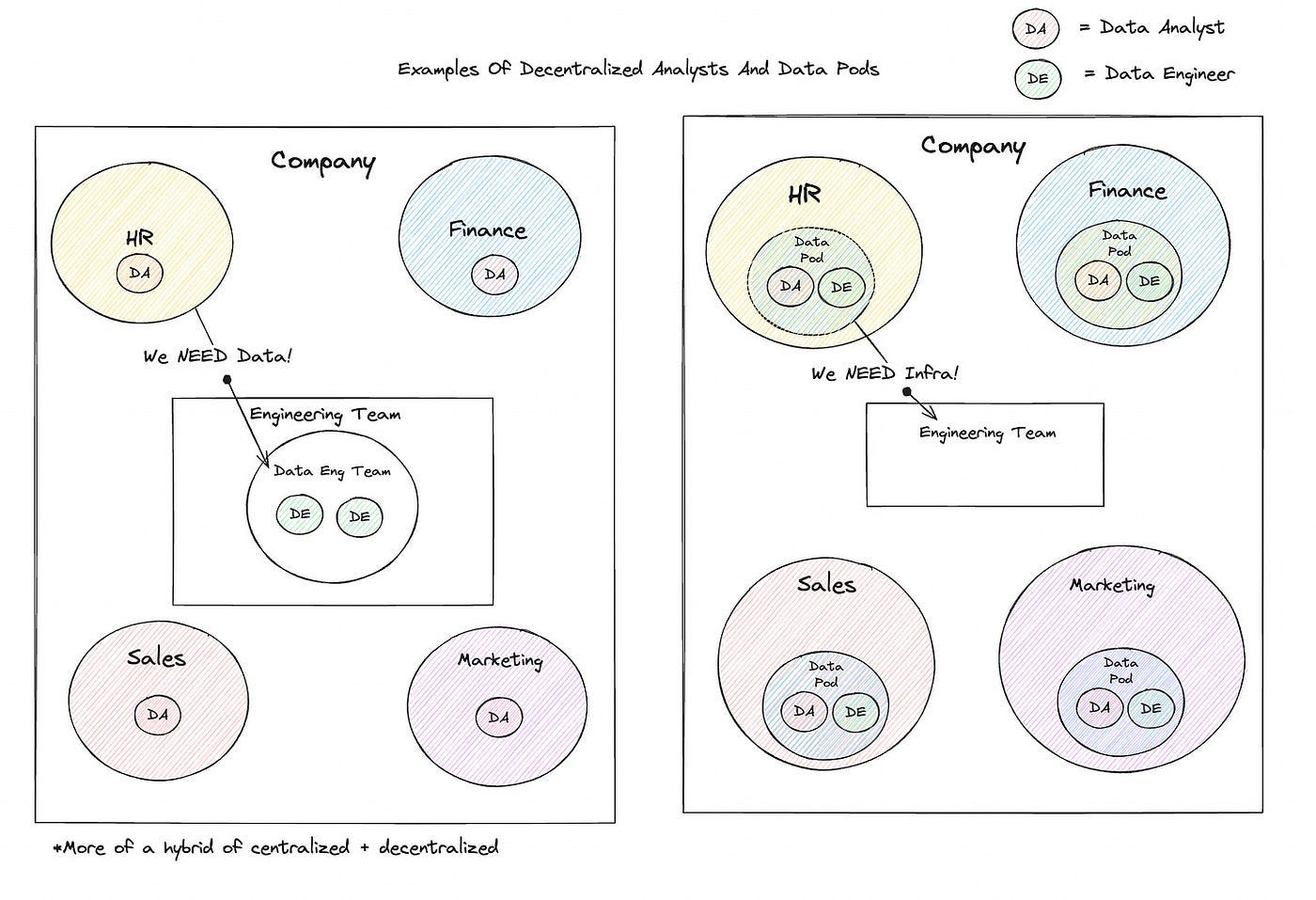
https://medium.com/coriers/centralized-vs-decentralized-vs-federated-data-teams-05dc14e8338d
DataDog: Scaling Self-Serve Analytics: The Tools Empowering 5,000 Employees
Datadog shared insights at the Crunch Conference on scaling self-serve analytics for Datadog's 5,000 employees. The approach revolves around empowering all team members to make data-informed decisions independently, leveraging a suite of tools built on open-source technologies. This strategy involves data intake, transformation, quality, discovery, and reporting, supporting various user needs and promoting a data-driven culture within the organization.

https://www.datadoghq.com/blog/engineering/crunchconf-talk-self-serve-analytics/
Sponsored: Announcing RudderStack Predictions: Automate churn and conversion scores in your warehouse
Our warehouse-native approach ensures Predictions are fully auditable, so you can thoroughly audit models and fit metrics, runs, and outputs.
RudderStack just announced a new ML product called Predictions that can use any data in your warehouse to automatically produce churn and conversion scores without MLOps. It’s built for data practitioners, so models are transparent, and it gives you control to tweak and tune. For advanced use cases, you can even migrate to a version-controlled, code-based workflow to create custom predictive features. A thorough quickstart guide, created in partnership with Snowflake, is available, complete with a sample dataset so you can test-drive the tool.
Grab: Kafka on Kubernetes: Reloaded for fault tolerance.
Grab Engineering writes about enhancing its Kafka on the Kubernetes platform for improved fault tolerance. The team redesign addresses worker node terminations without manual intervention, ensuring seamless data streaming. The solution employs AWS services and dynamic configurations to maintain uninterrupted operations, resulting in robust and efficient data handling technologies.
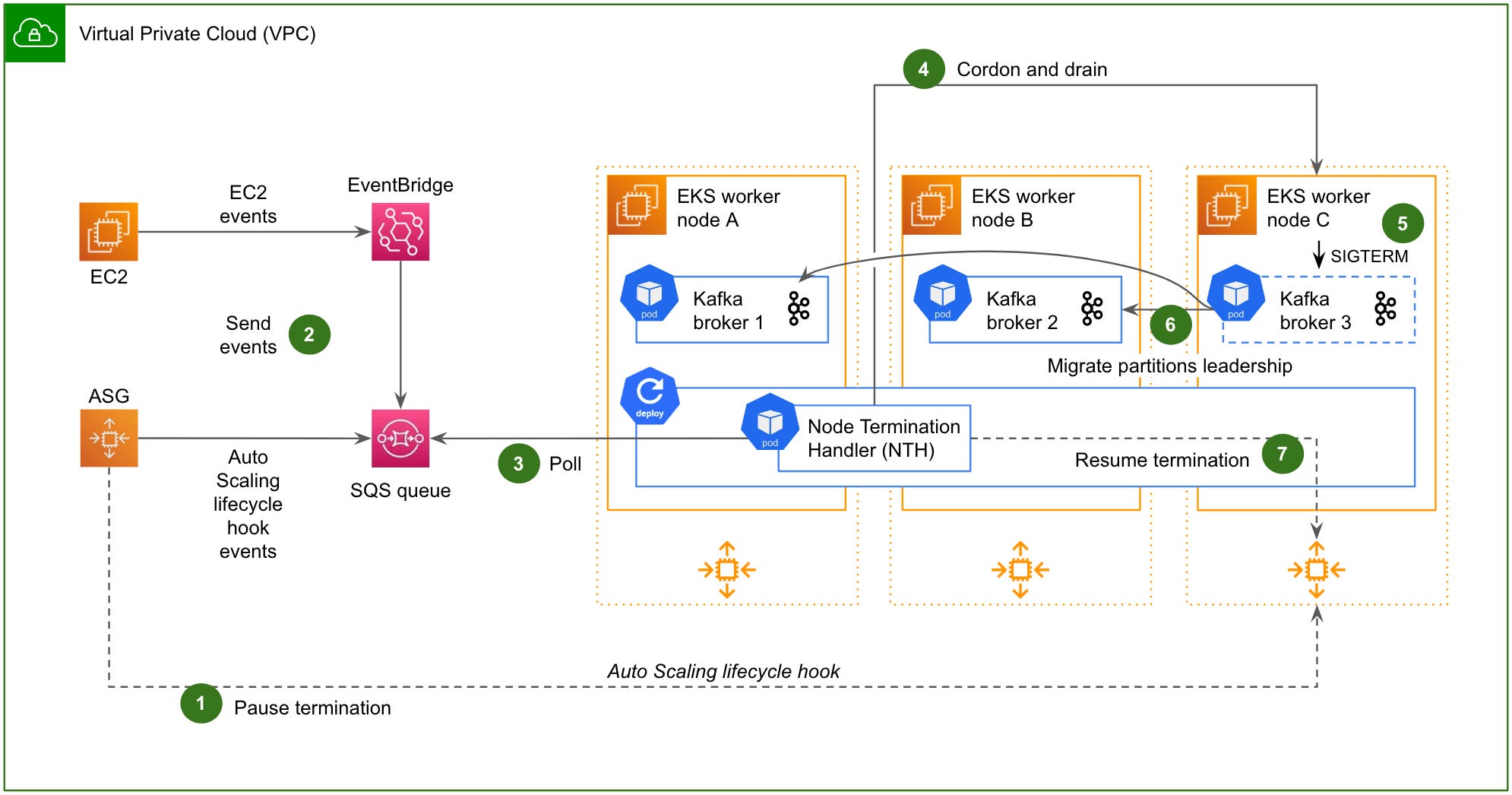
https://engineering.grab.com/kafka-on-kubernetes
Myntra: Bifrost - Data Serving Layer at Myntra
Myntra, the Indian fashion e-commerce giant, writes about its data-serving layer, Bifrost. The data serving layer focuses on deep personalization through a rich data platform. Bifrost empowers Myntra to integrate, manage, and utilize data, enhancing the customer experience through targeted personalization and streamlined analytics processes.

https://medium.com/myntra-engineering/bifrost-data-serving-layer-at-myntra-b75e35e1ff7c
Teads: Unit testing with dbt
Teads' blog post discusses unit testing with dbt, highlighting its advantages and limitations, especially regarding macros. The author engages in an interesting discussion on these shortfalls and acknowledges recent developments within the dbt community. This perspective offers valuable insights into the evolving landscape of dbt tests.
https://medium.com/teads-engineering/unit-testing-with-dbt-fb84f2ef7dd6
Pinterest: Handling Online-Offline Discrepancy in Pinterest Ads Ranking System
Pinterest addresses the challenge of discrepancies between online and offline metrics in its ads ranking system. The article explores scenarios where offline model improvements don't always align with online performance gains. The blog discusses hypotheses for this mismatch, including misalignment between offline evaluation metrics and online business metrics and complexities in their large-scale machine learning systems. The approach involves rigorous analysis and hypothesis testing to understand and mitigate these discrepancies, providing valuable insights into the intricate workings of Pinterest's ad ranking algorithms.

Walmart: Empowering Deeper A/B Test Insights at Walmart through Self-Serve Custom Metrics for Experimentation
Walmart writes about enhancing its Experimentation Platform, Expo, by introducing self-serve custom metrics (UCM) to analyze the impact of site changes, like its Homepage redesign. This new feature in Expo allows users to create and link custom metrics to experiments, providing deeper insights into customer interactions and the effectiveness of changes.

LanceDB: LanceDB + Polars
LanceDB writes about its integration with Polars, a high-performance DataFrame library. This collaboration enhances data analysis and manipulation capabilities, leveraging Polars' efficiency and speed within the LanceDB environment.

https://blog.lancedb.com/lancedb-polars-2d5eb32a8aa3
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
Interesting compilation, thanks.