
Data Engineering Weekly #156
The Weekly Data Engineering Newsletter


RudderStack is the Warehouse Native CDP, built to help data teams deliver value across the entire data activation lifecycle, from collection to unification and activation. Visit rudderstack.com to learn more.
Editors Note: DEWCon Drops Mic- Talks Live Now on YouTube!
Running the DEWCon conference with Aswin last October in Bengaluru, India, was a thrilling experience. I had a chance to meet some of the amazing humans of data engineering. I did very little to run the conference; all our volunteers and the participants made the event a huge success. Thanks to all our sponsors, OneHouse, Informatica, E6Data, and Skyflow.

The unanimous question we got at the evening party is: when are you going to do next year!!! The year is already here, so stay tuned for the announcements.
https://www.youtube.com/playlist?list=PLPR7LiWyYxc-hZHk-KA0VNejJ_3JbrOTA
Leboncoin Tech: From a hack to a data mesh approach: The 18-year evolution of data engineering at Leboncoin

Leboncoin discusses the evolution in data engineering, from a simple shell script to adopting data mesh principles, due to the company's significant growth. The article narrates various stages, including business intelligence, data platform, event-bus backbone, and machine learning, leading to decentralizing data engineering expertise and code. The company's journey reflects the evolving data engineering practices to meet business growth instead of a top-down approach.
Snap: Airflow Evolution at Snap
Snap writes about its Airflow infrastructure evolution by combining multiple isolated instances into a multi-tenant system with RBAC enablement. AIP-46 significantly improved runtime isolation for the task and DAG parsing, which is a key factor in enabling consolidation.

https://medium.com/apache-airflow/airflow-evolution-at-snap-c988cdd95abd
Macquarie: Real-time data processing using Change Data Capture and event-driven architecture
The change data capture (CDC) is an integral pattern of event-driven architecture that brings its own set of challenges to implementation. The Macquarie team writes about implementing CDC by comparing Solace vs. Kafka as a possible connector along with Debezium. TIL about Solace and its support for hierarchical queue support!!!

Daniel Kleinstein: Slashing Data Transfer Costs in AWS by 99%
S3 has another important characteristic. For the standard storage class, downloading data from S3 is free - it only incurs standard data transfer charges if you’re downloading it between regions or the public Internet. Moreover, uploading to S3 - in any storage class - is also free!
The author narrates how one can think of using this property to slash data transfer costs in AWS. While this won't work for latency-sensitive cases, it's a great option for cost-conscious data transfers.
https://www.bitsand.cloud/posts/slashing-data-transfer-costs/
Sponsored: RudderStack Launches Data Quality Toolkit
Leading data teams leverage their customer data to deliver high-impact machine learning projects like churn prediction and personalized recommendation systems to create significant competitive advantages for their companies. If you have a data quality problem, success like this can seem out of reach.
Poor data quality leads to lackluster results and frustrated stakeholders, but fixing bad data can become an endless task that keeps you from key initiatives. To help you drive data quality at the source, RudderStack just launched a Data Quality Toolkit. It includes features for collaborative event definitions, violation management, real-time schema fixes, and monitoring and alerting. With the toolkit, you can spend less time wrangling and more time helping your business drive revenue.
Microsoft: Responsible AI in action
Responsible AI is of utmost importance as it requires the consideration of societal values, moral and ethical aspects, fairness, privacy, transparency, and accountability in the development and use of AI systems. Microsoft writes about RAI (Responsible AI) tools in both open source and as part of the Azure platform.
LinkedIn: Improving Recruiting Efficiency with a Hybrid Bulk Data Processing Framework
Reading about how data processing is mapped with the business use cases is always delightful. The combination of near real-time and bulk data processing is common in many business process requirements. I hope we will see more frameworks combine these two patterns, aka the expansion of workflow manager for both real-time and batch jobs.

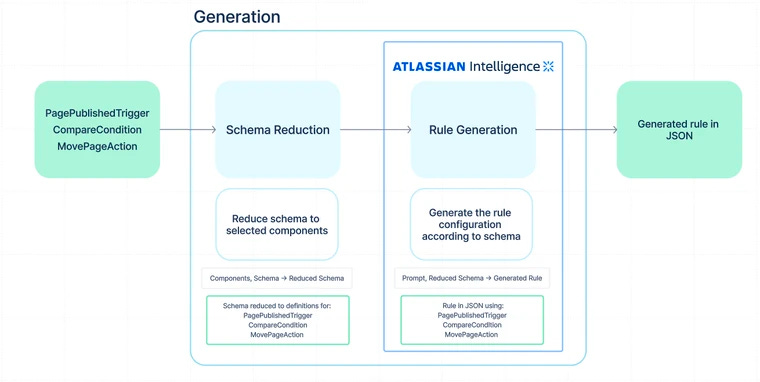
Atlassian: The future of automation at Atlassian: Generating Confluence automation rules with large language models
It is strictly not product marketing for Atlassian features :-) LLM greatly impacts how we build and use the software. However, incorporating LLM into an existing user experience and the product features is a bigger challenge for many organizations. It is exciting to see Atlassian sharing such product features utilizing LLM.
Modern Data Network: How much data professionals make in France: the MDN Annual Benchmark
The salary benchmarks always bring interesting insights, and the benchmark in France for the data engineering salary is particularly interesting as prime Large Language Models have emerged in France recently. Let me know in the comments what you think of this benchmark.

Meni Shmueli: Fixing small files performance issues in Apache Spark using DataFlint
I recently stumbled upon the DataFlint tool and found it very exciting. One of my constant complaints about Apache Spark is needing someone to examine the Spark history server to fine-tune the performance. It is exciting to see open-source APM tools like DataFlint.

All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.