
Data Engineering Weekly #158
The Weekly Data Engineering Newsletter


RudderStack is the Warehouse Native CDP, built to help data teams deliver value across the entire data activation lifecycle, from collection to unification and activation. Visit rudderstack.com to learn more.
Editors Note: A Survey on the current state of Data Products.
Data products represent a way of packaging and delivering data that provides specific, actionable value to users. The structured approach the data products bring to create, access, manage, and delete data assets is certainly appealing. What do you think of Data Products? How far is your organization adopting it? Please share your thoughts on the survey.
Tristan Handy: Is the "Modern Data Stack" Still a Useful Idea?
Is Modern Data Stack still a useful idea? I agree the cloud-native is no longer a differentiator as it becomes a default.
However, I disagree that MDS is no longer valid because of market shifts or AI investments.

With the modern data stack, we built hyper-specialized tools that resulted in high integration and cloud cost. It leads to hiring more developers and more lead time to produce value. The cloud-native data stack is still valid but with an integrated workflow to build and manage the data assets.
https://roundup.getdbt.com/p/is-the-modern-data-stack-still-a
Solmaz Shahalizadeh: What founders need to know to build a high-performing data team
“A number alone is never the answer for a great data team. It's what we’re going to do as a result of it,” says Solmaz Shahalizadeh, former vice president and head of data at Shopify.

Every data leader is going through this dilemma: how to influence action and better integrate the data team functions to multiply the organization's efficiency. The blog is an excellent guide on when and how to build a data team, the important qualities of a data team, and the organizational structure.
https://www.bvp.com/atlas/what-founders-need-to-know-to-build-a-high-performing-data-team
Dave Melillo: Building a Data Platform in 2024
The article is a good reminder to rethink what changed from pre and post-COVID in building data platforms. One common thing is that every company produces high-volume data, historically reserved only for big Internet companies. Apart from that, do you think anything significant changed? Let me know in the comments.

https://towardsdatascience.com/building-a-data-platform-in-2024-d63c736cccef
Alireza Sadeghi: Open Source Data Engineering Landscape 2024
Popular open-source tools like Airbyte and Snowplow have recently changed their licenses. Is there really a future for building open-source data tools anymore? However, a big kudos to Alireza for building the open-source data landscape.

https://alirezasadeghi1.medium.com/open-source-data-engineering-landscape-2024-8a56d23b7fdb
Sponsored: RudderStack Launches Data Quality Toolkit
Leading data teams leverage their customer data to deliver high-impact machine learning projects like churn prediction and personalized recommendation systems to create significant competitive advantages for their companies. If you have a data quality problem, success like this can seem out of reach.
Poor data quality leads to lackluster results and frustrated stakeholders, but fixing bad data can become an endless task that keeps you from key initiatives. To help you drive data quality at the source, RudderStack just launched a Data Quality Toolkit. It includes features for collaborative event definitions, violation management, real-time schema fixes, and monitoring and alerting. With the toolkit, you can spend less time wrangling and more time helping your business drive revenue.
Niels Cautaerts: A dataframe is a bad abstraction
What is an efficient abstraction for data programming? It is a long-debated topic, and SQL is one of the hard-criticized languages. [See: 10 Things I hate about SQL]. For a change, this time, it is the data frame. The author points out three key areas where the data frame is lacking.
Leaky Abstraction: Dataframes don't inherently express the structure, constraints, and business logic embedded in the data. This knowledge is implicit and known only to the developer or data expert.
Lack of Type Safety: Since dataframes are dynamically typed, most errors surface only at runtime. The lack of type safety contrasts with strongly typed languages, where you get more safeguards at compile time.
Difficulty in Software Maintenance: Each step in a data pipeline operates on a black box (the dataframe). Understanding modifications requires knowing the entire history of transformations and implicit assumptions.
https://medium.com/@cautaerts/a-dataframe-is-a-bad-abstraction-8b2d84fa373f
Timo Dechau: Eventify everything - Data modeling for event data
Should we promote events as a building block for data modeling? The author thinks so, claiming the traditional data models designed for order and marketing data don't easily scale to handle behavioral analysis needs. The layered approach from raw event collection, refined to qualifying events to make it accessible for insights, is an excellent read.

https://substack.timodechau.com/p/eventify-everything-data-modeling
Google: A decoder-only foundation model for time-series forecasting
It is one of my best reads this week, and I am super excited about the idea of a foundation model for time-series forecasting. Most Deep Learning architectures require long and involved training and validation cycles before a customer can test the model on a new time series. In contrast, a foundation model for time-series forecasting can provide decent out-of-the-box forecasts on unseen data without additional training, enabling users to focus on business use cases.
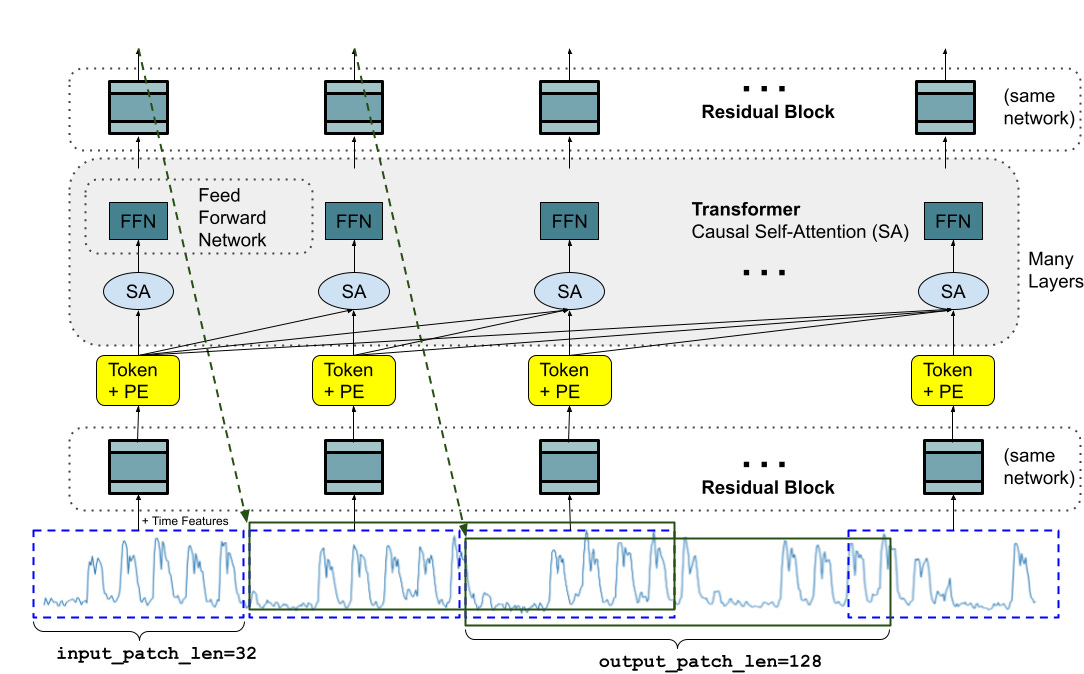
https://blog.research.google/2024/02/a-decoder-only-foundation-model-for.html
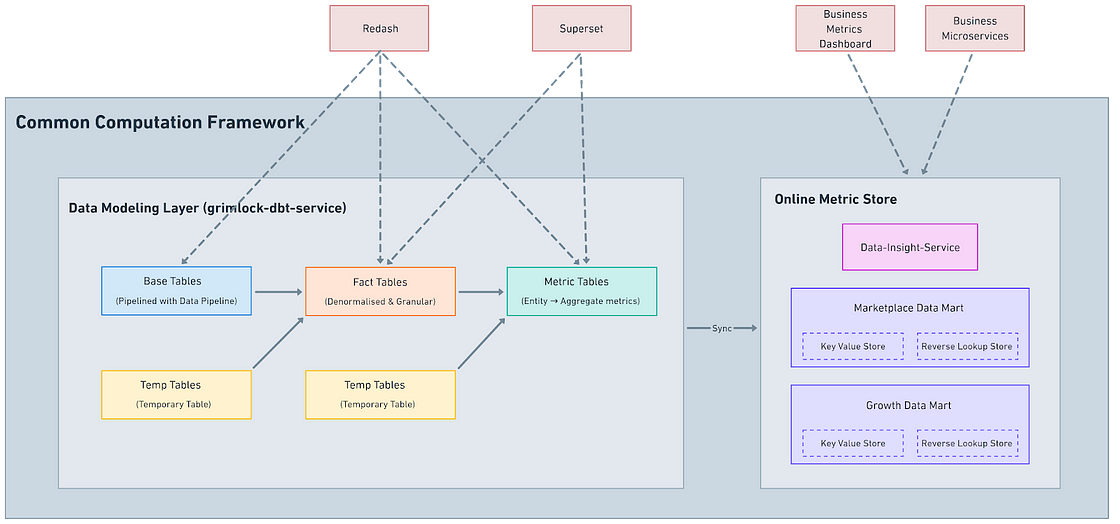
Urban Company: From Silos to Standardization: Leveraging DBT for a Democratized Data Framework
The author discusses building a data framework called the Common Computation Framework (CCF). The blog narrates the challenges of managing data in silos and the need for a centralized solution. The CCF uses DBT, a data modeling tool, to create standardized metrics. The standardization allows for better data discoverability, ownership, and quality.
Back Market: Back Market’s journey towards data self-service
An excellent read from the Back Market data team about various approaches to accelerating data access's democratization. The blog narrates the traditional approach from SQL Training to Data Catalog to simplify the tooling with low code data visualization tooling & data champions program.
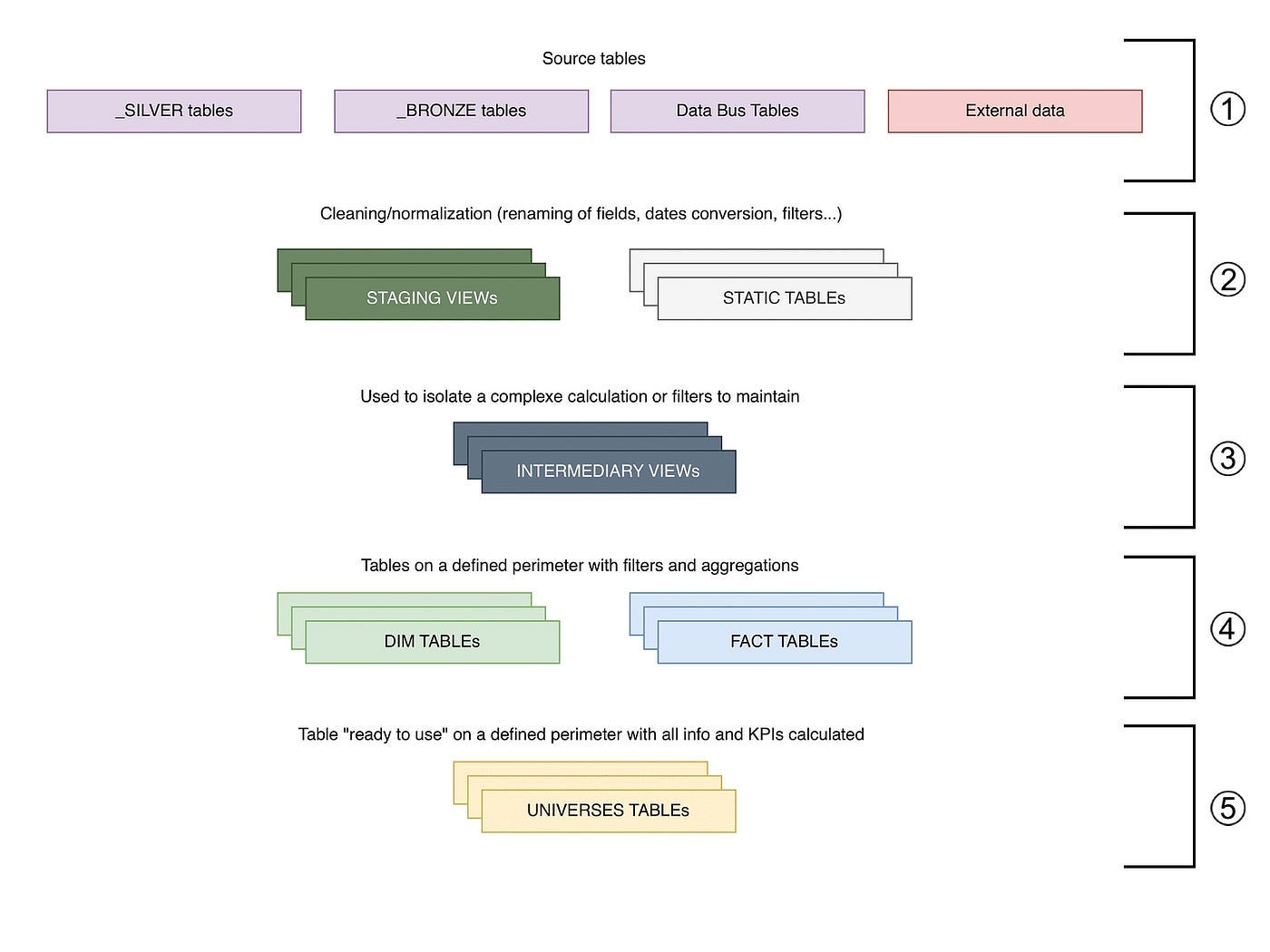
https://engineering.backmarket.com/back-markets-journey-towards-data-self-service-89b278d6617a
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.
Heads up the dbt article link is broken. I think it’s pointing to URL starting w/ hhtps