
Data Engineering Weekly #160
The Weekly Data Engineering Newsletter


RudderStack is the Warehouse Native customer data platform, built to help data teams deliver value across the entire data activation lifecycle, from collection to unification and activation. Visit rudderstack.com to learn more.
Editor’s Note: DEWCon Europe Update & Data Hero’s Chennai Chapter Meetup
Last week, we asked our readers if we should bring DEWCon to Europe. I’m super grateful to see so many people participate in the poll. I’m super delighted to see the result.

88% of people voted, Yes for DEWCon!!! Regarding which city to host the DEWCon event, Berlin and Amsterdam got an almost equal vote!! Are you ready to take Europe's data engineering scene to the next level? DEWCon is coming, and we need YOUR help! Our India event was a huge success because we kept the focus on practitioners, not vendors. If you want to shape the future of data in Europe, join our core working group. Let's build this together! Fill out the form below.
https://forms.gle/f8sbAgzQe5AVT9bC9
Though the online events are amazing, nothing can match the in-person networking and learning from each other. Just after the DEWCon conference, we heard the data practitioners want similar events in their cities to increase knowledge sharing. We can’t run a full-fledged data conference in each city but can do so with informal, low-key events. Please reach out if you would like to start a Data Hero chapter in your city. I would love to help set it up. As a first step, we are bringing our first low-key Data Hero’s meetup in Chennai, India, on March 8th. If you’re around Chennai on March 8th, please register here.
https://nas.io/data-heroes/data-hereos-chennai-meetup
Berkeley Artificial Intelligence Research (BAIR): The Shift from Models to Compound AI Systems

The Berkeley AI Research (BAIR) blog discusses the evolution from focusing on single large language models (LLMs) to developing compound AI systems that integrate multiple components, including LLMs, for superior performance. This shift is driven by the need for more sophisticated approaches to tackle complex tasks, as compound systems can leverage the strengths of various components to achieve better results than any single model could on its own. The article emphasizes that this trend towards compound systems opens new avenues for optimizing AI application design, promising significant improvements in AI's effectiveness and efficiency.
https://bair.berkeley.edu/blog/2024/02/18/compound-ai-systems
Mozilla: LLM evaluation at scale with the NeurIPS Large Language Model Efficiency Challenge

The Mozilla AI blog post discusses the NeurIPS Large Language Model Efficiency Challenge, which evaluates the efficiency of fine-tuning large language models (LLMs) on specialized data within 24 hours using a single GPU. This challenge highlighted the complexities of LLM evaluation, emphasizing the importance of community consensus on evaluation metrics and sharing evaluation artifacts as open-source. The competition fostered practical insights into model and infrastructure optimization, underscoring the evolving landscape of LLM efficiency and evaluation practices.
Sponsored: GigaOm's In-Depth Analysis of Semantic Layers and Metric Stores in Latest Sonar Report
GigaOm delves into detailed evaluations of various semantic layers and metric stores in a comprehensive Sonar report.
Explore this report to grasp the concept of a semantic layer, comprehend its functionality and applications, and gain insightful comparisons among diverse vendors.
https://cube.dev/gigaom-rates-cube-as-a-leader-for-semantic-layers
Chris Riccomini: From Samza to Flink: A Decade of Stream Processing
This article offers a fascinating historical perspective on stream processing through the evolution of Apache Samza. The article explores various design choices and how they impacted the Apache Samza adoption in the industry.
My challenge with Samza during my time at Slack is the decision to co-locate Samza's state in Kafka. At that time, operating Kafka comes with its challenges. Samza’s stream-stream join relies on Kafka’s key partition to shift the streaming operation burden to Kafka. I saw a similar design echo in Kafka streams, and my reaction back then was this.

https://materializedview.io/p/from-samza-to-flink-a-decade-of-stream
Pinterest: Unlocking AI-Assisted Development Safely: From Idea to GA

Pinterest Engineering shared its journey towards implementing AI-assisted development, focusing on balancing innovation, safety, security, and cost. They opted for GitHub Copilot, emphasizing a thorough evaluation process, cross-functional collaboration, and extensive trials to address potential risks and gather feedback. The positive outcome led to a significant increase in developer productivity and Copilot adoption, paving the way for further improvements and safe, efficient AI integration in their development processes.
Github: How AI code generation works
The GitHub Blog explains how AI code generation, like GitHub Copilot, transforms software development by automating code creation and assisting developers across various programming languages. It outlines the process from simple autocompletion to complex code suggestions based on natural language comments and direct interaction with AI, enhancing productivity, reducing mental load, and minimizing context switching. The post emphasizes the importance of human oversight in ensuring code quality and alignment with project goals.
https://github.blog/2024-02-22-how-ai-code-generation-works/
Sponsored: Data quality best practices - Bridging the dev data divide
"Just like the data team, development teams are under pressure to work quickly and efficiently to accomplish their goals. It’s not like development teams purposely make life difficult for their data team counterparts. They’re just doing their jobs, and their incentives are, by nature, different from yours."
Here, the team at RudderStack looks at the divide between data producers and consumers. They give a clear explanation for why it exists, and they detail four principles you can follow to bridge the gap. The article concludes with a look at data contracts as a concrete example of these principles in practice.
https://www.rudderstack.com/blog/data-quality-best-practices-bridging-the-dev-data-divide/
Swiggy: Reflecting on a year of generative AI at Swiggy: A brief review of achievements, learnings, and insights
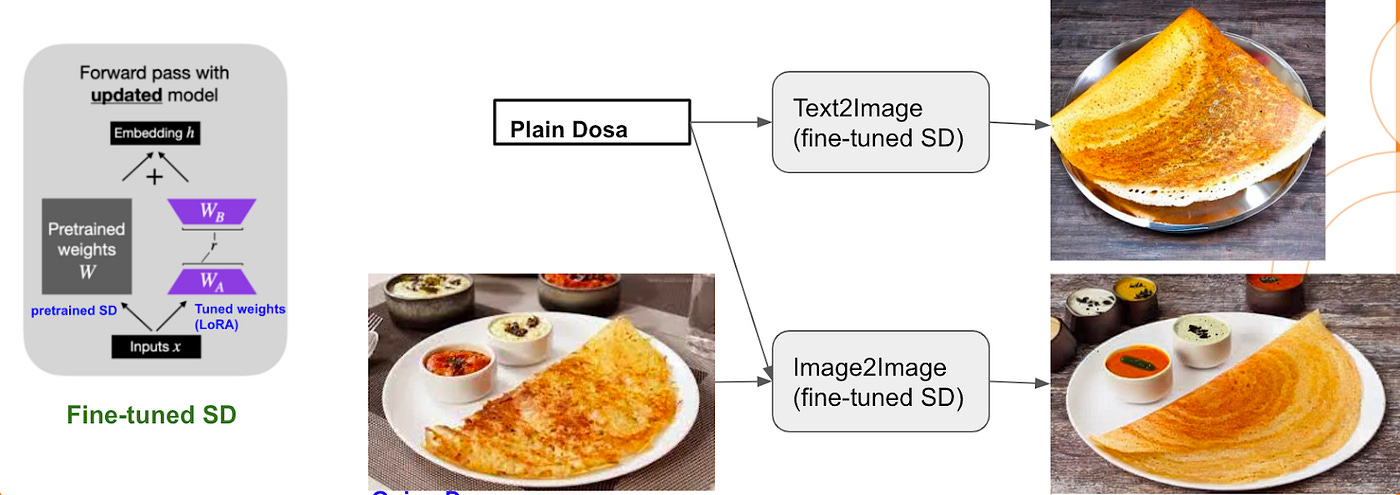
Swiggy's blog post reflects on a year of implementing generative AI, highlighting their journey from exploration to institutionalization. They focused on enhancing customer experiences and operational efficiency through customized AI models, addressing latency and data integrity challenges. Key application areas included catalog enrichment, review summarization, and neural search, with a strategic approach to managing risks and responsibly leveraging AI's potential.
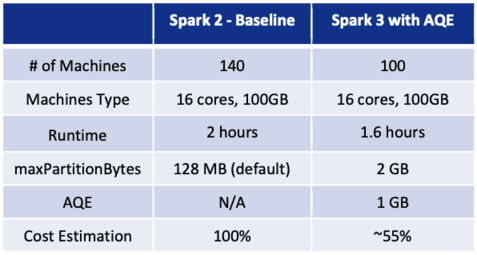
PayPal: Leveraging Spark 3 and NVIDIA’s GPUs to Reduce Cloud Cost by up to 70% for Big Data Pipelines
PayPal's integration of Apache Spark 3 and NVIDIA GPUs has led to up to 70% cost savings in cloud expenses for big data and AI applications, processing petabytes of data across hundreds of thousands of jobs. By leveraging Spark RAPIDS, PayPal optimized data processing using GPU acceleration, overcoming latency optimization and data hallucination challenges. This initiative reduced costs and enhanced computational efficiency, demonstrating the significant benefits of GPUs in big data environments.
New York Times: How the New York Times Games Data Team Revamped Its Reporting
The New York Times Games Data Team revamped its data architecture to enhance analytics and reporting capabilities following the acquisition of Wordle and a surge in user activity. They developed a new data structure with explicit aggregation layers, leading to a threefold increase in dashboard usage and more efficient data analysis processes. This overhaul improved the team's ability to generate insights, democratize data, and support the launch of new games, demonstrating the value of thoughtful data management in product development.
https://open.nytimes.com/how-the-new-york-times-games-data-team-revamped-its-reporting-8af7e7c7bc97
Willem Koenders: Intelligent Data Governance by Design — A Practical Example
The author outlines a shift towards intelligent data governance by design, contrasting with traditional post-implementation governance efforts. It presents a practical example of embedding data quality, integrity, and security controls into the data processes from the beginning, emphasizing this approach's efficiency and future-proofing benefits. Organizations can achieve scalable and cost-effective data governance by focusing on preventive measures at data capture, maintaining data quality at the source, ensuring protected data access, and making data flows discoverable by design.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.