
Data Engineering Weekly #161
The Weekly Data Engineering Newsletter


RudderStack is the Warehouse Native CDP, built to help data teams deliver value across the entire data activation lifecycle, from collection to unification and activation. Visit rudderstack.com to learn more.
Editor’s Note: Chennai, India Meetup - March-08 Update
We are thankful to Ideas2IT to host our first Data Hero’s meetup. There will be food, networking, and real-world talks around data engineering. Here is the agenda,
1) Data Application Lifecycle Management - Harish Kumar( Paypal)
Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems.
2) Why High-Quality Data Products Beats Complexity in Building LLM Apps - Ananth Packildurai
I will walk through the evolution of model-centric to data-centric AI and how data products and DPLM (Data Product Lifecycle Management) systems are vital for an organization's system.
3) DataOPS at AstraZeneca
The AstraZeneca team talks about data ops best practices internally established and what worked and what didn’t work!!!
4) Building Data Products and why should you? by Aswin James Christy( Qlik/Talend)
Aswin establishes a case for why you should start thinking about building data products.
SignUp Link: https://nas.io/data-heroes/data-hereos-chennai-meetup
Pinterest: Unlocking AI-Assisted Development Safely: From Idea to GA
Pinterest detailed its journey of implementing AI-assisted development, highlighting its initial caution due to legal and security concerns and its eventual decision to adopt GitHub Copilot for its seamless IDE integration and compatibility with its tooling ecosystem. Through an extensive trial involving 200 developers, with an established feedback loop, ensuring Copilot's effectiveness and security. This approach led to a successful expansion of Copilot access across the engineering team, resulting in a significant increase in productivity and adoption, demonstrating a commitment to enhancing developer experience while maintaining safety and security standards.
Microsoft: GraphRAG - Unlocking LLM discovery on narrative private data
The article introduces GraphRAG, a Microsoft Research innovation enhancing Large Language Models' (LLMs) capabilities in analyzing narrative private data through knowledge graphs. GraphRAG significantly improves question-and-answer performance over traditional vector similarity techniques using LLM-generated knowledge graphs for document analysis. This approach enables deeper insights into complex datasets that LLMs have not been trained on, demonstrating substantial improvements in data understanding and thematic discovery.
Nvidia: What Is Sovereign AI?
To open or not to open the OpenAI is a hotly debated topic in the industry—the era where people started considering AI development a national asset. The NVIDIA blog on Sovereign AI emphasizes the importance of countries developing artificial intelligence capabilities using local infrastructure, data, and workforce. The article discusses the role of "AI factories" and national efforts worldwide to advance sovereign AI through partnerships, investments, and infrastructure development.
https://blogs.nvidia.com/blog/what-is-sovereign-ai/
Sponsored: Data quality best practices - Bridging the dev data divide
"Just like the data team, development teams are under pressure to work quickly and efficiently to accomplish their goals. It’s not like development teams purposely make life difficult for their data team counterparts. They’re just doing their jobs, and their incentives are, by nature, different from yours."
Here, the team at RudderStack looks at the divide between data producers and consumers. They give a clear explanation for why it exists, and they detail four principles you can follow to bridge the gap. The article concludes with a look at data contracts as a concrete example of these principles in practice.
https://www.rudderstack.com/blog/data-quality-best-practices-bridging-the-dev-data-divide/
Databricks: A Deep Dive into the Latest Performance Improvements of Stateful Pipelines in Apache Spark Structured Streaming

The Databricks blog article delves into the latest enhancements for stateful pipelines in Apache Spark Structured Streaming, focusing on improving performance through optimized memory management, database write/flush performance, and changelog checkpointing. These improvements, part of Project Lightspeed, aim to reduce latency and increase throughput for stateful streaming queries, making them more efficient and cost-effective. The article also highlights sink-specific improvements and operator-specific enhancements that contribute to the overall performance boost.
Zendesk: dbt at Zendesk
The Zendesk team shares their journey of migrating legacy data pipelines to dbt, focusing on making them more reliable, efficient, and scalable. They tackled the challenge by starting with pipelines requiring frequent updates, implementing initial lift and shift to dbt with minimal changes, and then proceeding with basic and advanced refactoring for optimization. The migration enhanced data quality, lineage visibility, performance improvements, cost reductions, and better reliability and scalability, setting a robust foundation for future expansions and onboarding.
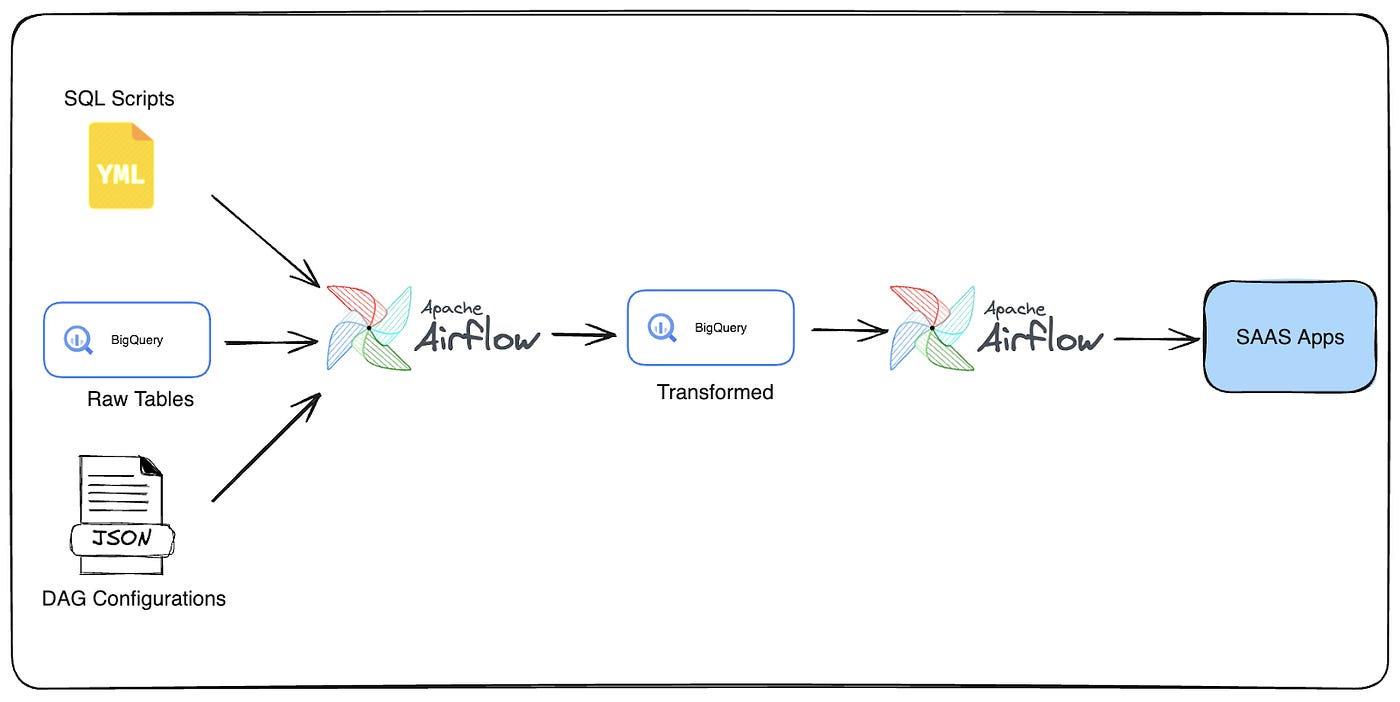
dbt at Zendesk — Part I: Setting Foundations for Scalability
dbt at Zendesk — Part 2: supercharging dbt with Dynamic Stage
dbt at Zendesk — Part III: lift-and-shift playbook
Grab: Enabling near real-time data analytics on the data lake
Grab discusses its near real-time data analytics implementation in their data lake, highlighting the transition from traditional data storage to the Hudi format for efficient processing. The article explains the challenges with frequent updates in the vanilla data lake setup and how Hudi allows for faster writes and guarantees atomicity, consistency, isolation, and durability (ACID).

https://engineering.grab.com/enabling-near-realtime-data-analytics
Rippling: Engineering a SIEM: Rippling's security data lakehouse and modular design
The two-part series from Rippling details their journey of building a custom Security Information and Event Management (SIEM) system, emphasizing an engineering-first approach for enhanced security and operational efficiency. Part 1 covers the need for a bespoke SIEM, focusing on scalability, efficient log management, and seamless AWS integration, among other requirements.

Part 2 focuses on its security data lakehouse and its modular design and highlights the implementation of a security data lakehouse using Snowflake, emphasizing efficient log ingestion, modularization with Terraform, and custom log pullers.
Part 1: Why did we need to build our own SIEM?
Part 2: Rippling's security data lakehouse and modular design
DoorDash: Introducing DoorDash’s In-House Search Engine
DoorDash writes about its in-house search engine to address scalability and efficiency issues identified with Elasticsearch's previous search architecture. The new system, built on Apache Lucene, features a segment-replication model, separates indexing from searching traffic, and significantly reduces latency and hardware costs. The system design focuses on a horizontally scalable, general-purpose engine with enhanced query understanding and planning, aiming to support DoorDash's rapid growth and complex document relationships more effectively.

https://doordash.engineering/2024/02/27/introducing-doordashs-in-house-search-engine/
AWS: Data governance in the age of generative AI
The AWS Big Data Blog discusses the importance of data governance in the age of generative AI, emphasizing the need for robust data management strategies to ensure data quality, privacy, and security across structured and unstructured data sources. The article highlights how enterprises can leverage AWS services to manage data governance effectively, ensuring responsible AI use by incorporating comprehensive data governance steps in data pipelines and user interaction workflows. This approach helps maintain accuracy, relevance, and compliance in generative AI applications.

https://aws.amazon.com/blogs/big-data/data-governance-in-the-age-of-generative-ai/
Martin Chesbrough: How to Build a Modern Data Team? Seven tips for success
The article outlines seven tips for building a modern data team: emphasizing the importance of the team's composition and adaptability, advocating for a blend of centralized and decentralized approaches, promoting a full-stack data team concept rather than seeking full-stack engineers, valuing mindset and principles over mere certifications, ensuring the team enjoys their work, and aligning data architecture with organizational structure as per Conway's Law. It stresses the need to understand the technological and human aspects of data team dynamics, including fostering skill liquidity and focusing on first principles for problem-solving over tool-specific knowledge.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.