


Data Engineering Weekly #167
The Weekly Data Engineering Newsletter

Meta: OpenEQA - From word models to world models

Will AI agents soon become a common fixture in our homes and an integral part of our daily lives? Meta introduces the Open-Vocabulary Embodied Question Answering (OpenEQA) framework—a new benchmark to measure an AI agent’s understanding of its environment by probing it with open-vocabulary questions. Meta claims that by enhancing LLMs with the ability to “see” the world and situating them in a user’s smart glasses or on a home robot, we can open up new applications and add value to people’s lives.
https://ai.meta.com/blog/openeqa-embodied-question-answering-robotics-ar-glasses/
Aishwarya Srinivasan: How Microsoft's 1-bit LLM is going to change the LLM landscape?
With the 1-bit LLM model, the researchers are suggesting instead of FP16 (Full Precision floating-point number with 5-bits) or FP32 (Full Precision floating-point number with 6-bits), you can build an equally efficient model using ternary digit set ∈ {-1, 0, 1}. It can drastically reduce the computational cost and energy requirement for training LLM, and it is an interesting development to watch.

https://aishwaryasrinivasan.substack.com/p/microsofts-1-bit-llm
Github: 4 ways GitHub engineers use GitHub Copilot
The impact of LLM on software development is undeniable. Every survey demonstrates an increase in productivity in software development with copilot-type tools. Github shares some insights on how Github engineers use Github Copilot.
https://github.blog/2024-04-09-4-ways-github-engineers-use-github-copilot/
Sponsored: Rethinking Modern Business Intelligence with a Universal Semantic Layer
From cloud data warehouses and cloud-native enterprise applications to acquiring the right data and the joins, relationships, and calculations to correctly define a data model, there’s still too much guesswork for data analysts and business users who are seeking insights.

Discover how a universal semantic layer is transforming modern business intelligence, making data more accessible and reliable for organizations striving for informed business decisions.
https://cube.dev/blog/business-intelligence-with-universal-semantic-layer
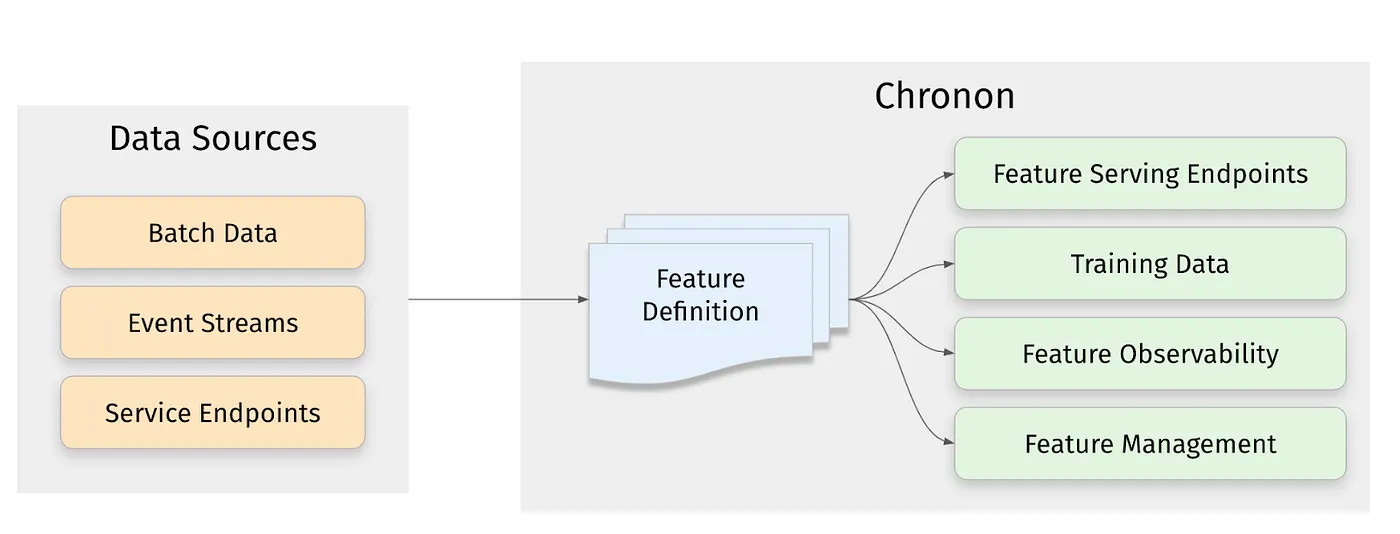
Airbnb: Chronon, Airbnb’s ML Feature Platform, Is Now Open Source
Airbnb open-sources Chronon, its ML Feature platform. The highlight of the design is the unique blending of batch and real-time events with the common feature definition. The other key feature I like is the out-of-the-box support for backfilling with point-in-time accuracy, skew handling & computational efficiency.
Arpit Choudhury: Growth needs to speak the language of Engineering and Data
Software engineers and data engineers don’t speak the same language
It reminds me of this famous quote

The Author highlights that the growth team should be aware of the skill differences. Understanding the difference between their interpretations of common terminology is a big step toward having better conversations with both teams.
https://newsletters.databeats.community/p/collaborating-with-data-and-engineering-teams
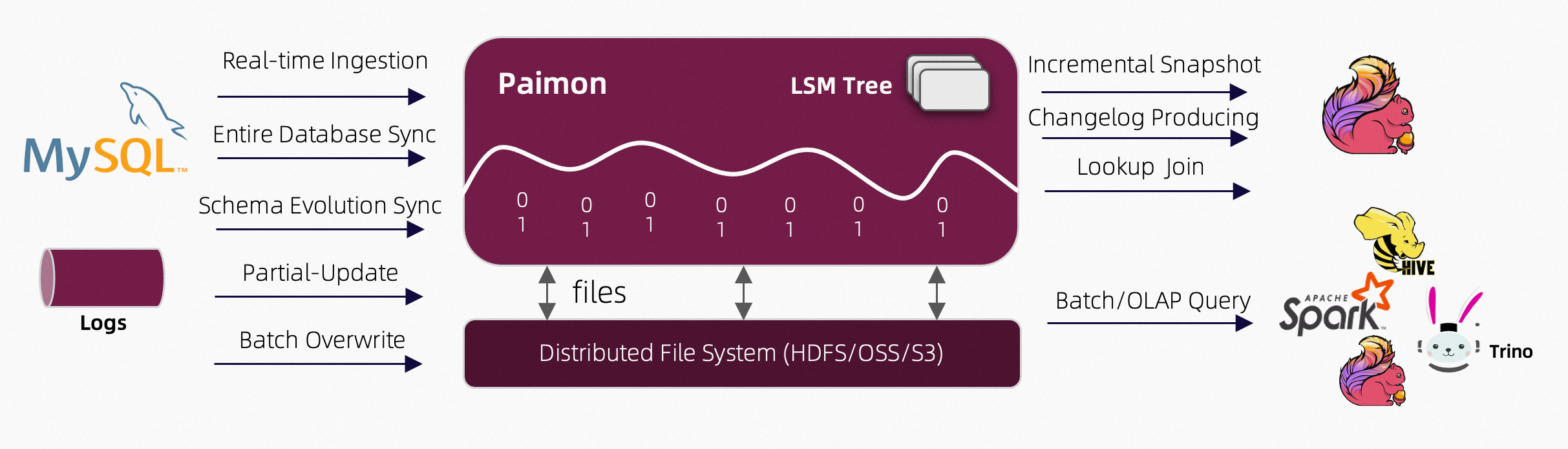
Alibaba: Building a Streaming Lakehouse: Performance Comparison Between Paimon and Hudi
I’m not a big fan of these comparison studies since it all depends on the nature of the data and the business use cases. However, TIL about Apache Paimon, a lake format that enables building a real-time lakehouse architecture with Flink and Spark for both streaming and batch operations.
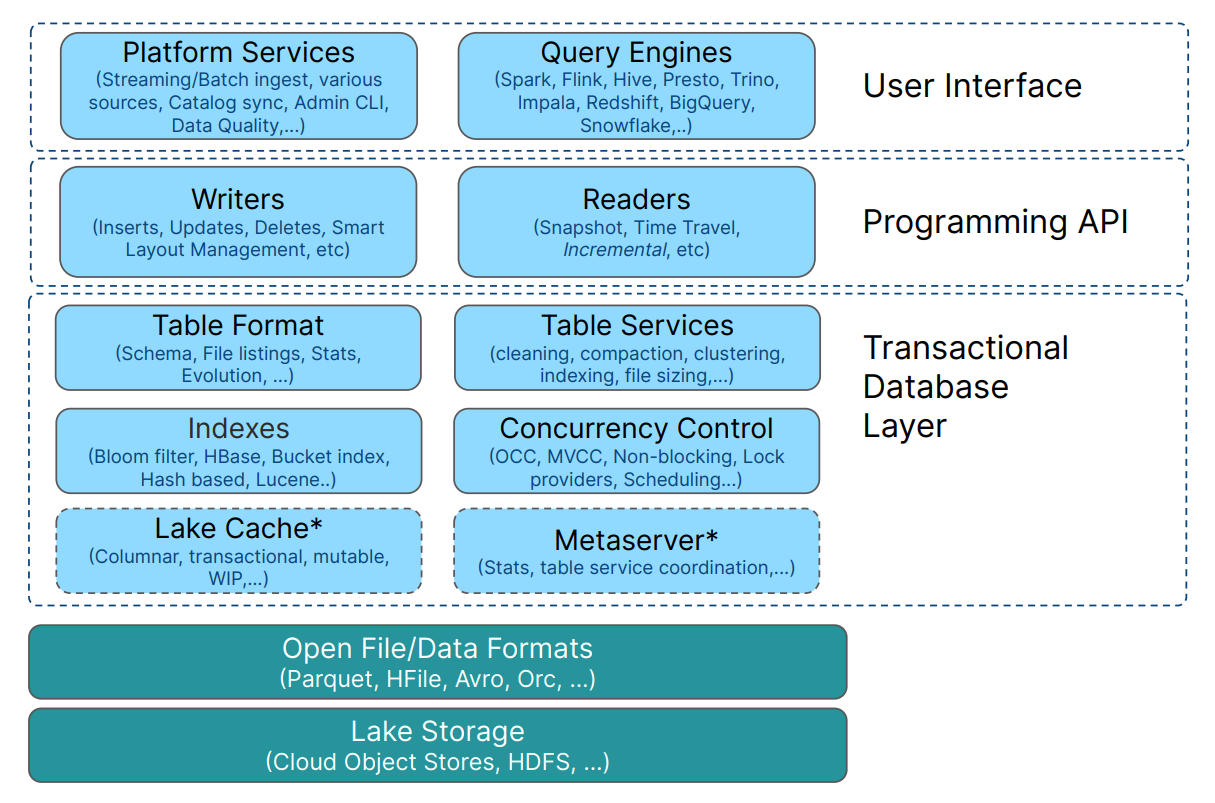
Shiyan Xu: Apache Hudi - From Zero To One - 10-part series
Staying with the LakeHouse format, The 10-part series about Apache Hudi is an exciting read for me over the weekend. The blog post brings in-depth insights into how Apache Hudi works on the right side, read side & underlying storage formats. It's a good read that familiarizes you with the LakeHouse formats.
https://blog.datumagic.com/p/apache-hudi-from-zero-to-one-1010
NYT: Milestones on Our Journey to Standardize Experimentation at The New York Times
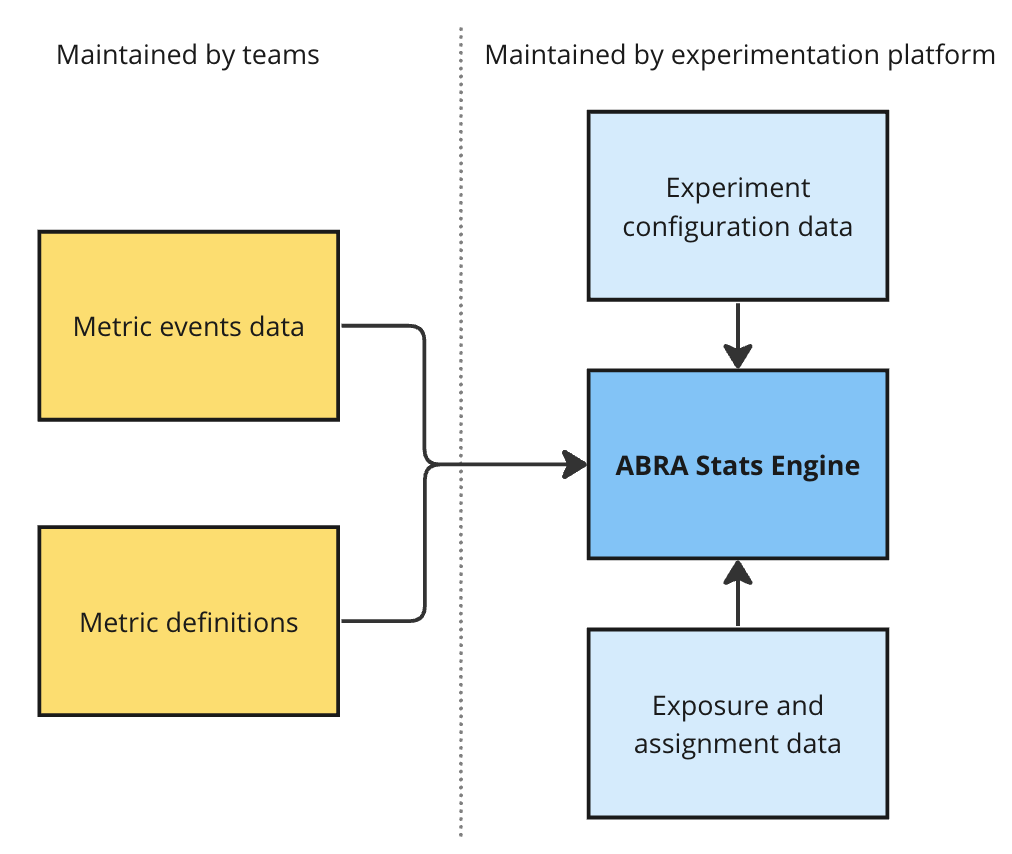
The New York Times details its advancements in standardizing experimentation across its teams to refine the testing process and implement innovations efficiently. By centralizing its experimentation platform, the Times has streamlined test efficiency, accelerated decision-making, and strengthened data analysis capabilities. This systematic approach aids in aligning various team efforts and enhances overall product development.
Grab: Grab Experiment Decision Engine - a Unified Toolkit for Experimentation
Continuing the stories of standardizing experimentation, Grab writes about the GrabX Decision Engine. GrabX encompasses a pre-experiment advisor, a post-experiment analysis toolbox, and other advanced tools. It utilizes rule-based logic and machine learning models to evaluate millions of possibilities, ensuring the most efficient decisions are made instantaneously.

https://engineering.grab.com/grabx-decision-engine
Intel: Four Data Cleaning Techniques to Improve Large Language Model (LLM) Performance
If someone asks me to define LLM, this is my one-line definition.
Large Language Models: Turning messy data into surprisingly coherent nonsense since 2023.
High-quality data is the cornerstone of LLM. In this blog, Intel shares four data-cleaning techniques to improve LLM performance, with code examples and a step-by-step process.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.