
Data Engineering Weekly #168
The Weekly Data Engineering Newsletter

Meta: Introducing Meta Llama 3 - The most capable openly available LLM to date
Meta is taking an interesting approach in the growing LLM market with the open source approach and distribution across all the leading cloud providers and data platforms. It is exciting to see Llama 3 with 70B parameters on par with GPT-3.5, which I believe has 175B parameters.

https://ai.meta.com/blog/meta-llama-3/
HuggingFace: The Open Medical-LLM Leaderboard: Benchmarking Large Language Models in Healthcare
Can LLM make an impact in healthcare? Globally, the cost of healthcare is increasing significantly. I expect healthcare providers to experience soon what the taxi industry has gone through. The users might choose a good enough, low-cost option over the existing one. Medical tourism is one industry thriving on that front, and perhaps LLM is the answer. HuggingFace publishes the open Medical-LLM leaderboard.

https://huggingface.co/blog/leaderboard-medicalllm
Stripe: Shepherd - How Stripe adapted Chronon to scale ML feature development
Airbnb recently open-sourced Chronon, a declarative feature engineering framework. Stripe publishes details on how it adopted Chronon in partnership with Airbnb. The blog narrates how Chronon fits into Stripe’s online and offline requirements.

https://stripe.com/blog/shepherd-how-stripe-adapted-chronon-to-scale-ml-feature-development
Sponsored: Delivering on the promise of AI: Increasing Accuracy with a Semantic Layer
Organizations are exploring the potential of chatbots to answer questions presented in natural language. However, when these chatbots utilize generative AI, they risk producing incorrect replies.

A semantic layer can solve this problem by creating the knowledge needed for 100% accuracy.
Webinar Information:
🗓 Date: Wednesday, April 24th
🕒 Time: 9 am PST | 12 pm EST
Join us to discover:
-The consequences of not using a semantic layer with LLMs in chatbots
-How a semantic layer contributes to the effectiveness of an AI chatbot
-The noticeable distinction in a live demonstration of an AI chatbot versus one lacking a semantic layer."
https://cube.registration.goldcast.io/events/bd020457-cbec-4ebd-b6c0-7ea40430ec86
RevenueCat: How we solved RevenueCat’s biggest challenges on data ingestion into Snowflake
A common design feature of modern data lakes and warehouses is that Inserts and deletes are fast, but the cost of scattered updates grows linearly with the table size. RevenueCat writes about solving such challenges with the ingestion table & consolidation table pattern.

https://www.revenuecat.com/blog/engineering/data-ingestion-snowflake/
Canva: Scaling to Count Billions
If you know how to count, you’re an excellent data engineer. Counting is the hardest problem in data engineering. Canva writes about such challenges and narrates how it solves them.

https://www.canva.dev/blog/engineering/scaling-to-count-billions/
Grab: Enabling near real-time data analytics on the data lake
Apache Hudi’s Merge On Read (MoR) is a game changer in developing low-latency analytics on top of the data lake. Grab narrates how it integrated Debeizium, Kafka, and Apache Hudi to enable near real-time data analytics on the data lake.

https://engineering.grab.com/enabling-near-realtime-data-analytics
GoodData: Building a Modern Data Service Layer with Apache Arrow
GoodData writes about using Apache Arrow to build an efficient service layer. The blog narrates using Apache Arrow Flight RPC to build data querying, post-processing, and caching layers.
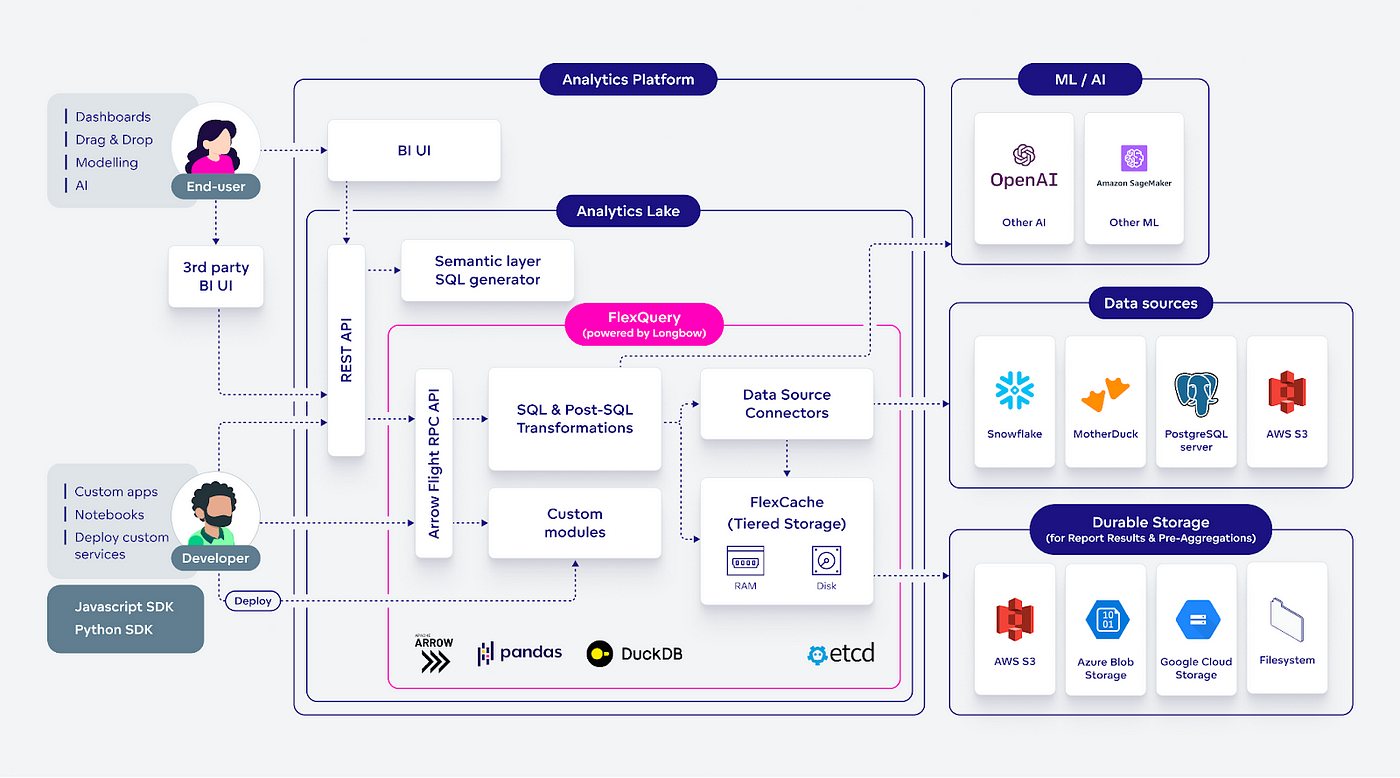
Mixpanel: Under the Hood of Mixpanel’s Infrastructure
It is always exciting to read the internals of an analytical platform, and Mixpanel published one such article. The blog narrates the common challenges with enterprise analytical platforms such as event-centric, schema on-read, and nested json structures.

https://engineering.mixpanel.com/under-the-hood-of-mixpanels-infrastructure-0c7682125e9b
Autodesk: Improving confidence in our tracking with auto-generated Snowplow types
Autodesk writes a classic data ingestion problem: What can go wrong with event collection? The blog highlights the lack of control in schema, schema drifting, and scalability as the key challenges. The result is to adopt data contract solutions with type standardization and auto-generate schemas.

https://engineering.autotrader.co.uk/2024/04/05/auto-generating-snowplow-types.html
Swiggy: Automating Mobile Event Verification
Swiggy writes another classic data contract solution that automates mobile event verification. Event testing is one of the biggest challenges that increases complexity for mobile applications since the release cycle is not frequent. The blog narrates an automated contract validation workflow in Android applications.
https://bytes.swiggy.com/automating-mobile-event-verification-1d840f39d300
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.