
Data Engineering Weekly #170
The Weekly Data Engineering Newsletter

Ken Liu: Machine Unlearning in 2024
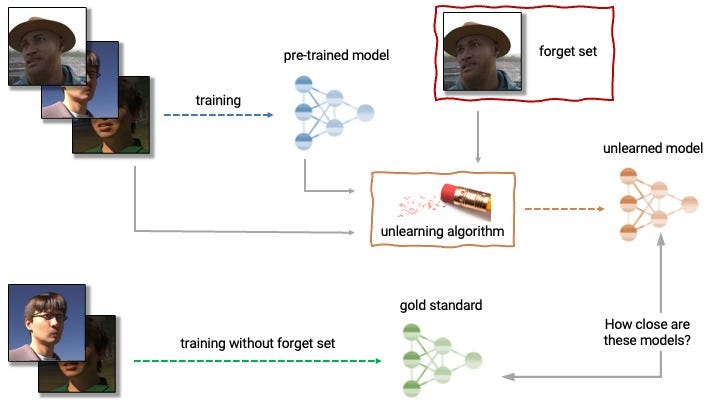
One of the insightful articles is about the growing adoption of one large language model and the challenge it brings to machine unlearning. The motivation for Machine Unlearning is critical from the privacy perspective and for model correction, fixing outdated knowledge, and access revocation of the training dataset.
A key thought-provoking moment for me while reading the article is this quote.
In an ideal world, data should be thought of as “borrowed” (possibly unpermitted) and thus can be “returned,” and unlearning should enable such revocation.
https://ai.stanford.edu/~kzliu/blog/unlearning
Uber: From Predictive to Generative – How Michelangelo Accelerates Uber’s AI Journey
Constantly adopting and implementing tech advancement with an existing system indicates efficient engineering. Uber wrote an in-depth article about the evolution of its centralized ML platform, Michelangelo.

https://www.uber.com/blog/from-predictive-to-generative-ai/
LinkedIn: LakeChime - A Data Trigger Service for Modern Data Lakes
LinkedIn points out two critical flaws in a partitioned approach to data management.
The granularity of partition creation constrained data consumption. For instance, if partitions were created daily, consumers could only schedule daily jobs to consume new partitions.
Partitions are created once, but their data can continually be updated.
LinkedIn writes about LakeChime, a data trigger service that acts as a signal processor for downstream jobs to handle partition and snapshot table layouts.

Sponsored: Navigating Aquaculture with Embedded Analytics
How Scoot Science Charted Its Journey with a Universal Semantic Layer

Learn how Scoot Science optimized their embedded aquaculture analytics platform through a universal semantic layer in our upcoming webinar on May 15th at 9 AM PT / 12 PM ET.
This session will provide insights into:
- Scoot Science's SeaState platform and its data challenges
- Overcoming data complexities with a semantic layer
- Impact of a standardized data model on data processing and user experience
- Streamlining data infrastructure for efficiency and innovation
https://cube.registration.goldcast.io/events/11ebc02a-8e78-40fe-837e-2ab90fdc05d5
Booking.com: Lessons in adopting Airflow on Google Cloud
Booking.com writes about the lessons learned from adopting Airflow on Google Cloud. The learning focuses on
Setting up the local development environment
Performance tuning with Celery workers
embedded documentation in Airflow DAG
https://medium.com/booking-com-development/lessons-in-adopting-airflow-51821709cba4
PayPal: Scaling PayPal’s AI Capabilities with PayPal Cosmos.AI Platform
PayPal writes about its internal AI platform cosmos.ai, which provides MLOps capabilities that streamline processes like model training, deployment, and monitoring, significantly reducing complexity and costs. The platform also emphasizes extensibility and future-proofing against rapid technology changes, focusing on responsible AI usage, multi-tenancy, self-service capabilities, and seamless integration with existing systems.

Sponsored: Learn how to modernize your data integration capabilities across analytics, operations, and AI use cases - one-day virtual summit (free)
Join this one-day virtual summit for strategies and best practices to elevate your data integration and drive innovation, with sessions from data leaders at T. Rowe Price, JPMorgan, T-Mobile, LiveRamp, and more:
- Enhancing operational efficiency and app functionality with unified data
- Feeding data into vector databases to deploy generative AI initiatives
- Facilitating the preparation and management of data from multiple sources
- Leveraging data integration for BI & Analytics, data science, and data exchange use cases
https://www.dataintegrationsummit.com/
Iswarya Murali: Trustworthiness of Generative AI: Reducing hallucinations and increasing transparency
As much as Gen AI's potential is promising, mistrust and skepticism could encumber AI adoption. Hallucinations and the system's lack of explainability are the primary reasons for mistrust in Gen AI. The author highlights some key strategies to reduce the hallucinations and increase transparency.
Sanjeev Mohan: Untangling the Streaming Landscape: The Rise of Unified Real-time Platforms
Stream processing comes in different forms, with event stream processing, streaming databases, and stream-enabled analytical databases. The larger question is, should one consider a unified real-time platform? The author expands on the possibility of unified data platforms.

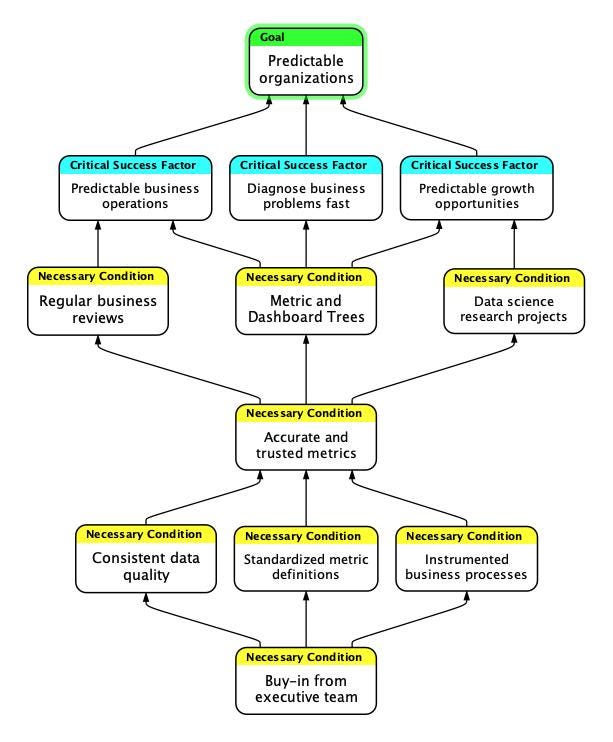
Ergest Xheblati: Transforming a Data Culture
Every data team has this burning question: How do we pivot away from answering questions and building dashboards and toward being a strategic partner who has a real impact on the business? The author narrates a path toward achieving a predictable organizational outcome.
It’s no surprise that everything starts with getting buy-in from the executive team. There are essentially two types of companies: those that believe in data and those that don’t. It’s an uphill battle for the data team if you end up in an organization where the executives don’t believe in data for the decision-making process.
https://sqlpatterns.com/p/transforming-a-data-culture
Miles McBain: Patterns and anti-patterns of data analysis reuse
We practiced and discussed reusability in software engineering, but I never thought deeply about data analytics reuse. For me, It is always adding additional dimensions in a dashboard to bring reusability, but that won’t be the case in ad-hoc analytics. The author discusses the common patterns of data analytics reuse, anti-patterns on each usage and best practices to mitigate technical debts.
https://www.milesmcbain.com/posts/data-analysis-reuse/
Daniel Beach: Delta Lake - Map and Array data types
Having a well-structured data model is always great, but we often handle semi-structured data. The fact that the nature of the event sourcing mostly deals with JSON structure adds more complexity. The LakeHouse format’s in-build support for Map and Array gives the flexibility to handle semi-structured data.
However, the Map and Array comes with its cost. There is no proper indexing support for these complex data types, causing query complications and unhappy customers. The LakeHouse formats should move beyond primitive types and inherent indexing support for complex data types for faster query performance.
https://dataengineeringcentral.substack.com/p/delta-lake-map-and-array-data-types
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.