
Data Engineering Weekly #171
The Weekly Data Engineering Newsletter

Editor’s Note: DEWCon Call for Speakers Open - September 13th, Bengaluru - India
DEWCon is back this year on a grand scale on September 13th, 2024, in Bengaluru, India. This year, we added some additional features to bring the data community together.
Book a 1:1 session with experts on career, tech stack, team management, and more!!
"Ideas Jam Session,” where you can talk about your idea/ prototypes in a 10-minute slot
More details on DEWCon will be in the coming weeks, and we will open the registration shortly.
If you want to speak at the conference, propose the talk here: https://forms.gle/21piE4B4e9VuShQ97.
If you want to sponsor DEWCon, express interest here: https://forms.gle/NSWPL6mjJEdR5ERd9.
Gloss Genius: How We Migrated From dbt Cloud and Scaled Our Data Development
Gloss Genius describes its migration journey from dbt cloud to Airflow + custom Github actions. The post highlights how Gloss Genuis established feature parity with SlimCI and enhanced post-migration with open-source tooling.

https://glossgenius.com/blog/how-we-migrated-from-dbt-cloud-and-scaled-our-data-development
Gradient Flow: Learning from the Past - Comparing the Hype Cycles of Big Data and GenAI
The blogs compare the hype cycle of Big Data with Gen AI. The blog narrates the initial hype of Big Data, followed by talent shortages and lead time to build production applications. Since then, abstractions like Hive SQL have significantly simplified the barrier to entry, which has led to the commoditization of big data. The author predicts such abstraction and commoditization requirements for Gen AI.
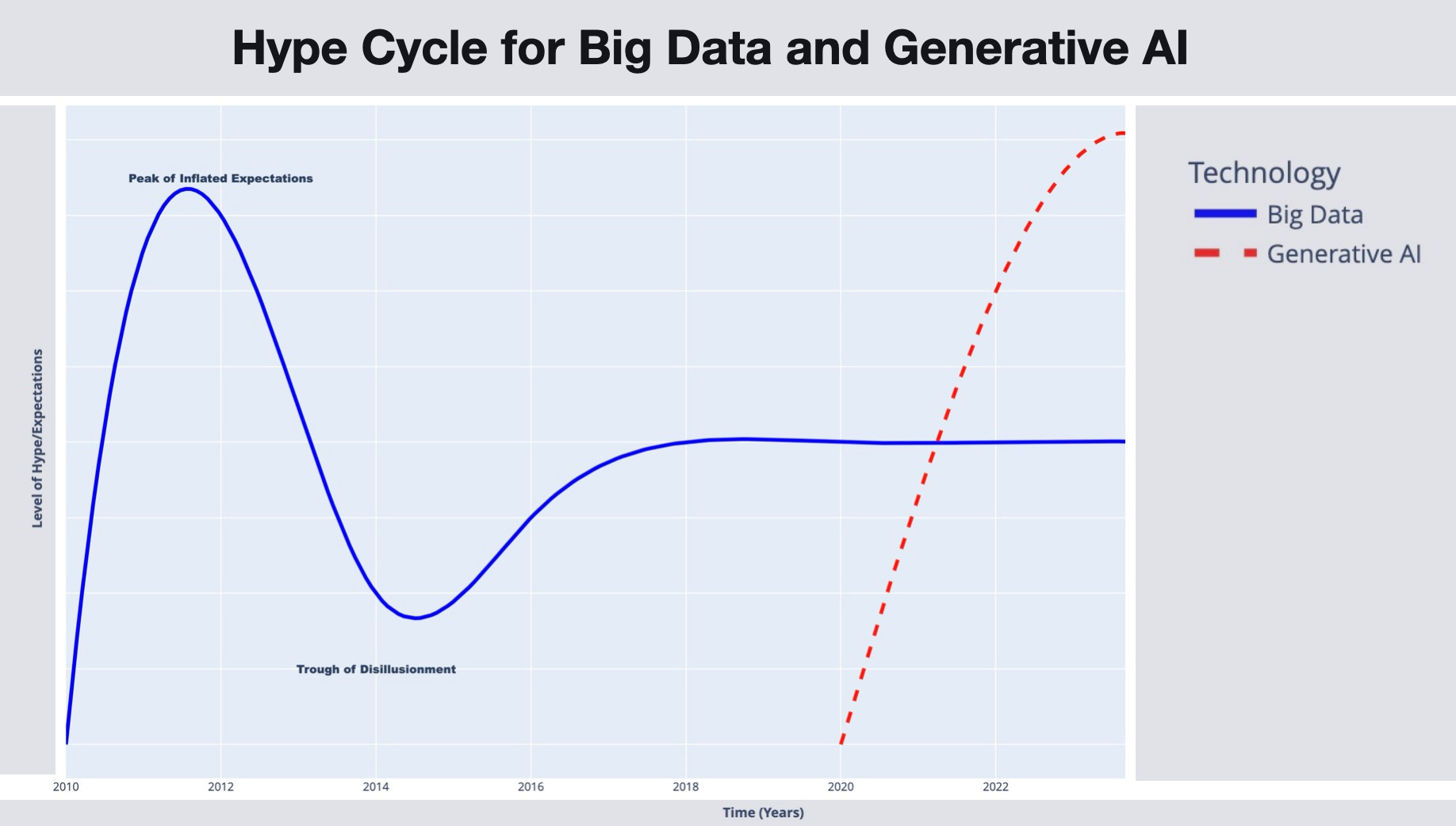
https://gradientflow.substack.com/p/learning-from-the-past-comparing
Slack: How We Built Slack AI To Be Secure and Private
One of the biggest challenges in adopting Gen AI in enterprises is maintaining the client data as secure and private. Slack describes the challenges in maintaining AI secure & private that leads to the choice of RAG approaches with large contextual window LLM.

https://slack.engineering/how-we-built-slack-ai-to-be-secure-and-private/
Sponsored: DoubleCloud - Build your data analytics infrastructure in one day
DoubleCloud is here to provide you with best-in-class open-source solutions for building a data analytics infrastructure. From ingestion to visualization: all integrated, fully managed, and highly reliable, so you can save time and costs with zero-maintenance open-source tech.

Ready to give DoubleCloud a try? We have a special offer for Data Engineering Weekly readers: start a free trial and get $500 credits for free, so you can see just how easy it is to spin up your own analytics with us!
Uber: DataK9 - Auto-categorizing an exabyte of data at field level through AI/ML
Rich contextual information is vital to bringing intelligence out of the data. Often, data categorization and contextualization are an afterthought in the data ecosystem. At scale, it becomes impossible to enrich the data assets manually. Uber writes about DataK9, an AI/ ML model that autocategorizes the data assets without manual labeling. It is one of the tools I wish Uber could open source.

https://www.uber.com/blog/auto-categorizing-data-through-ai-ml/
Google Security: Accelerating incident response using generative AI
Google's latest blog post discusses using generative AI to enhance incident response processes. Google Security leveraged Large Language Models (LLMs) to significantly speed up the creation of security and privacy incident summaries, reducing the time needed by 51% and improving the quality of these communications. AI streamlines internal communications and ensures that incident responses are timely and effective, helping to maintain rigorous security standards.

https://security.googleblog.com/2024/04/accelerating-incident-response-using.html
Ismahfaris Ismail: Productionising LLMs and ML Models with Analytics.gov - MOM’s Journey into AI Solution Deployment
The Ministry of Manpower (MOM) in Singapore writes about the usage of LLM & ML models to develop and deploy two AI products: the SSOC Autocoder, which efficiently categorizes job postings into relevant classifications, and Sensemaker, which extracts insights from large document volumes using AI. These tools have streamlined development processes, improved operational efficiency, and enabled data-driven decision-making across government agencies.

LinkedIn: Responsible AI update - Testing how we measure bias in the U.S.
LinkedIn's blog post discusses their approach to ensuring fair and responsible AI usage, emphasizing the importance of not amplifying biases within their AI systems. LinkedIn employs a privacy-preserving probabilistic race/ethnicity estimation system to measure and ensure 'Equal Treatment' across demographic groups without compromising member privacy. The system avoids individual race/ethnicity assignments and ensures data security & member control align with their Responsible AI Principles to provide equitable AI-driven experiences.
Stanford HAI: The Disinformation Machine - How Susceptible Are We to AI Propaganda?
The earlier article on Slack & LinkedIn discussed the importance of protecting AI applications' privacy and security. However, not everyone operates responsibly to handle the power of AI. The blog points out that Gen AI is more capable than humans of creating disinformation, especially deep fake technologies. In a well-connected world with social media, the danger of Gen AI and disinformation is undeniable.
https://hai.stanford.edu/news/disinformation-machine-how-susceptible-are-we-ai-propaganda
Alibaba: Analysis and Application of New Features of Flink ML
The Alibaba Cloud blog analyzes new features in Flink ML, focusing on online learning and inference capabilities and improved feature engineering algorithms. The blog discusses Flink ML's evolution into a real-time machine learning platform with enhanced infrastructure to support dynamic online learning processes, enabling continuous model updates and applications in various real-time scenarios. Flink ML’s evolution aims to streamline operational workflows and enhance performance for diverse business applications.

https://www.alibabacloud.com/blog/analysis-and-application-of-new-features-of-flink-ml_601119
Atlassian: Evolve your data platform with a Deployment Capability
The article from Atlassian discusses the importance of enhancing data platforms with robust deployment capabilities, focusing on the company's own experience with its internal data lake. Atlassian emphasizes how crucial it is for its data lake, utilized by over half of its employees, to support continuous growth and adaptability. The key takeaway is that integrating deployment capabilities can significantly improve the management and scalability of data platforms, ensuring they remain efficient and reliable as they evolve.

https://www.atlassian.com/engineering/evolve-your-data-platform-with-a-deployment-capability
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.