
Data Engineering Weekly #172
The Weekly Data Engineering Newsletter

Editor’s Note: DEWCon Call for Speakers Open - September 13th, Bengaluru - India
DEWCon is back this year on a grand scale on September 13th, 2024, in Bengaluru, India. We added some additional features to bring the data community together this year.
Book a 1:1 session with experts on career, tech stack, team management, and more!!
"Ideas Jam Session,” where you can talk about your idea/ prototypes in a 10-minute slot
More details on DEWCon will be in the coming weeks, and we will open the registration shortly.
If you want to speak at the conference, propose the talk here: https://forms.gle/21piE4B4e9VuShQ97.
If you want to sponsor DEWCon, express interest here: https://forms.gle/NSWPL6mjJEdR5ERd9.
Vicki Boykis: We've been put in the vibe space
Many companies struggle to integrate LLM into their business applications. The author highlights the importance of minimizing surprises and providing a uniform user experience across business categories by referring to Jakob’s law of UX.

https://vickiboykis.com/2024/05/06/weve-been-put-in-the-vibe-space/
Abraham Thomas: How To Price A Data Asset
How do we provide the value of data and subsequent infrastructure around it? This is a long-standing question for both internal data teams and vendors. It is challenging enough for a research topic. The article about data asset pricing is one of the comprehensive thoughts I came across about pricing models, establishing two basic factors.
Data value depends on the users and the use cases
Data quality is multi-dimensional, and high-quality data costs more.
https://pivotal.substack.com/p/how-to-price-a-data-asset
Chris Riccomini: Nimble and Lance - The Parquet Killers

One of my burning questions is that there is not much going on in the columnar formats. An Empirical Evaluation of Columnar Storage Formats paper compares ORC and Parquet formats regarding efficiency, design choices, and what is lacking in that system. The blog compares the two modern-day alternatives for Parquet, Nimble & Lance.
https://materializedview.io/p/nimble-and-lance-parquet-killers
Sponsored: Build next-generation data experiences faster with Cube Cloud
Join us for a live webinar on May 22nd at 9 am PT | 12 pm ET, where we'll showcase how to accelerate the development of AI and embedded analytics solutions using Cube Cloud. Here's what you can expect to learn:

- Simplify LLM Integration: Discover how Cube's native AI API streamlines the development of chatbots, copilots, and Slack apps with text-to-semantic layer queries, making it easier to integrate OpenAI and build intuitive natural language capabilities.
- Rapidly Prototype Embedded Analytics: Learn about our new Chart Prototyping feature in Cube Cloud's Playground 2.0, which allows you to create, test, and deliver chart insights effectively. Generate TypeScript code, preview diverse chart types, and integrate using REST or GraphQL APIs.
Attend to see product demos and learn how to build secure, accurate, and cost-effective AI and embedded analytics solutions.
Register now and join us on May 22nd!
https://cube.registration.goldcast.io/events/29bbd223-e862-44ff-821d-f3420033060c
Mikkel Dengsøe: Data about data from 1,000 conversations with data teams
The blog highlights some of the pressing issues in the industry.

Data Warehouses are increasingly building business-critical applications that lead to the rapid adoption of best practices from software engineering. We have already seen talks about data contracts, data products, etc.
Data teams and their stack are getting larger. The complexity of engineering data exponentially increases as the data size grows.
As testing becomes the core of reliable data system building, data professionals increasingly become domain experts.
https://medium.com/@mikldd/data-about-data-from-1-000-conversations-with-data-teams-bf21496dd7ea
LinkedIn: Building a Large-Scale Recommendation System: People You May Know
LinkedIn's "People You May Know" feature is designed to help users expand their professional networks by suggesting new connections based on shared contacts, interests, and professional backgrounds. Recent updates have focused on improving recommendation quality and reducing bias, ensuring frequent and infrequent users benefit from relevant suggestions.

Notably, empirical research has shown that connections with acquaintances, rather than close friends, are more effective in helping users find new job opportunities, validating the "strength of weak ties" theory.
DoubleCloud: Spectrio Boosts Analytics Speed and Cuts Costs with Managed ClickHouse
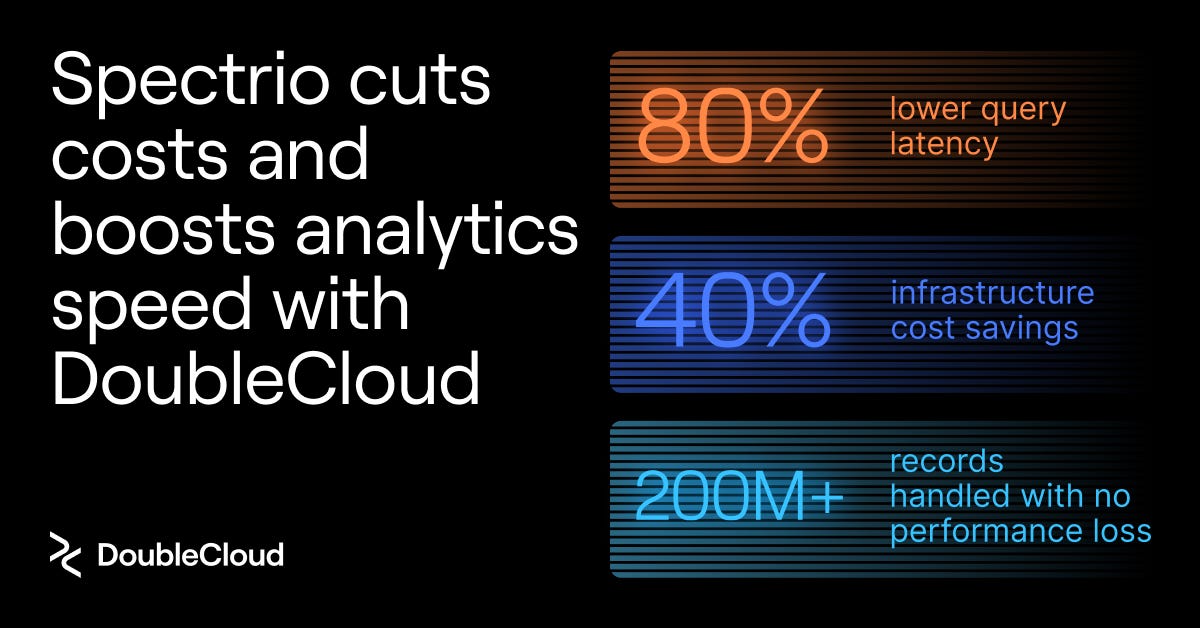
Whether you are struggling with query speed, infrastructure costs, or vendor-lock, DoubleCloud is here to help you out with the best-in class managed open-source tech! Read on to discover how Spectrio managed to reduce their query latency and infra costs while handling more than 200M+ rows by switching from Snowflake.
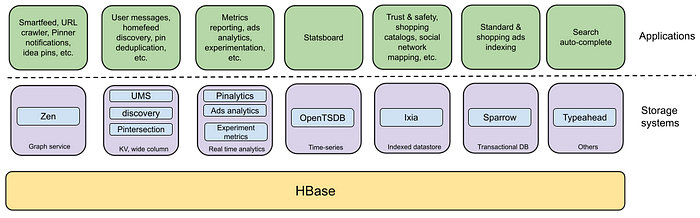
Pinterest: HBase Deprecation at Pinterest
Pinterest writes about its multi-year journey of deprecating HBase with specialized databases such as Druid, Goku (an in-house time-series db), and TiDB. The blog highlights the key factors that lead to HBase deprecation.
Complexity and Maintenance Overhead
Scalability and Performance Issues
Lack of Essential Features
https://medium.com/pinterest-engineering/hbase-deprecation-at-pinterest-8a99e6c8e6b7
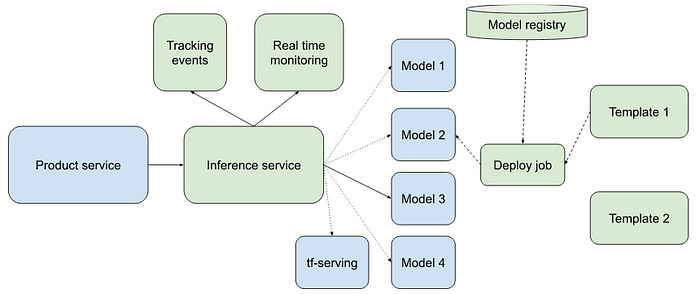
Thumbtack: Unifying Machine Learning Model Inference at Thumbtack
Thumbtack writes about unifying its machine learning model inference process to streamline deployment and improve efficiency. By consolidating various models into a single inference platform, Thumbtack better manages model versions, reduces latency, and scales its infrastructure seamlessly. This approach not only enhances performance but also simplifies the maintenance and deployment pipeline for their machine learning operations.
BuzzFeed: Crafting Analytical Summaries with Chat GPT
The explainability of an analysis is one aspect I think LLM can help data practitioners. BuzzFeed writes about the same using ChatGPT to automate the creation of analytical summaries, blending data from various sources like SQL databases and Google Sheets. This approach improves efficiency by generating concise and accurate summaries, helping the team gain insights and make data-driven decisions.
https://tech.buzzfeed.com/crafting-analytical-summaries-with-chat-gpt-1316ba5fbe7c
Picnic: Enhancing Search Retrieval with Large Language Models (LLMs)
Picnic uses large language models (LLMs) to enhance its search retrieval system, enabling more accurate and contextually relevant search results. By leveraging LLMs, Picnic improves the understanding of user queries and the matching of these queries to relevant products. I’m doing some prototypes in blending keyword search and semantic search, and this is an existing domain to keep track of.
https://blog.picnic.nl/enhancing-search-retrieval-with-large-language-models-llms-7c3748b26d72
Agoda: How We Solve Load Balancing Challenges in Apache Kafka
Agoda writes about how it solved the load-balancing challenges with Apache Kafka. The model essentially falls into two categories.
Lag-aware producers (if there is only a finite and known set of producers in the system)
Lag-aware consumers (if there is no finite set of producers in the system)
The blog discusses various algorithmic approaches one can take for both the approaches and their trade-offs.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.
http://hhttps//pivotal.substack.com/p/how-to-price-a-data-asset this link wasn’t opening for me, I noticed the extra h in https