
Data Engineering Weekly #173
The Weekly Data Engineering Newsletter

Luke Byrne: Questions About AI
Is AI all about hype? What do humans spend their time on in a post-AGI world? There are many burning questions from our readers, too, and the author did an amazing compilation of some of the widely discussed questions around AI development. What is your burning question about AI?
https://byrnemluke.com/ideas/questions-about-AI
Chris Riccomini: S3 Is Showing Its Age
Building a global scale distributed system with eleven 9s of durability and four 9s of availability is no easy feat. S3 is the state-of-the-art software system of our age. However, is that all enough? The author highlights some of the key missing features from S3.

https://materializedview.io/p/s3-is-showing-its-age
Meta: Composable data management at Meta

Meta writes about its transition to a composable data management system to improve interoperability, reusability, and engineering efficiency. By leveraging Velox, an open-source execution engine, Meta integrates common components across diverse data systems, reducing redundancy and enhancing innovation.
https://engineering.fb.com/2024/05/22/data-infrastructure/composable-data-management-at-meta/
Sponsored: From 90-sec queries to sub-second with DoubleCloud
Learn how LSports, a top provider of real-time sports data, improved its data analytics using DoubleCloud’s Managed ClickHouse.
Query times have been reduced from over 90 seconds to less than 0.5 seconds, enhancing real-time sports data analytics efficiency!

Read the full success story and see how DoubleCloud takes analytics to the next level!
https://double.cloud/resources/case-studies/lsports-fast-track-to-quick-queries-with-clickhouse/
Zillow: Building a strong foundation to accelerate StreetEasy’s data science efforts
There is a huge difference between data and easy-to-use data. The former can lead to bad decisions and sub-par experiences; the latter leads to a superb product and experience that enables the people who use our services to make quick, data-informed decisions.
True that. Zillow writes about its approach to building easy-to-use data that adopts certified datasets, aka data products.
Tweeq: Tweeq Data Platform: Journey and Lessons Learned: Clickhouse, dbt, Dagster, and Superset

Tweeq writes about its journey of building a data platform with cloud-agnostic open-source solutions and some integration challenges. It is refreshing to see an open stack after the Hadoop era.
Sponsored: 5/30 Google BigQuery Data Integration Tech Talk
Scale data pipelines to and from BigQuery for GenAI, Business Intelligence, and Operations. Feat. Jobin George (Data Analytics Solutions Architect at Google Cloud)
Get all your BigQuery questions answered, and learn about:
- Creating intelligent, reliable data flows to and from Google BigQuery in minutes
- Best practices for operational data integration pipelines handling trillions of records
- Optimizing ETL/ELT pipelines for enhanced business analytics and dashboards
- Transformations to vector embeddings for GenAI and rapid experimentation with various LLMs
- Real-world use cases for companies like DoorDash, Johnson & Johnson, and LinkedIn.
https://nexla.com/resource/how-to-scale-data-integration-google-bigquery/
Akshay Agrawal: Lessons learned reinventing the Python notebook
I wrote about the need for a Notebook-like orchestration system: A Notebook is all I want or Don't. The author explores a similar thought process on reimagining the notebook cells as connected DAG and prefers simplicity. I’m super excited to see the construction style of the Notebook and what comes next.

https://marimo.io/blog/lessons-learned
Ryan Eakman: SQLFrame - Turning PySpark into a Universal DataFrame API
SQL or DataFrames, two programming models often used interchangeability in engineering data. It is a long standing question on people wondering In what situations should you use SQL instead of Pandas as a data scientist? and why one prefer dataframe over sql. SQLFrame is an interesting approach where it convert PySpark style DataFrame into SQL. The idea will infact open flexibility in programming data over the SQL-based data warehouse systems.
https://towardsdev.com/sqlframe-turning-pyspark-into-a-universal-dataframe-api-e06a1c678f35
Grab: How we evaluated the business impact of marketing campaigns
Marketing is the key function to drive the business operation, and measuring the success of marketing campaign vital to strengthen the sales pipeline. Grab writes about its adoption of experimentation framework in measuring the marketing campaigns impact.

https://engineering.grab.com/evaluate-business-impact-of-marketing-campaigns
Adrian Bednarz: Is star-schema a thing in 2024? A closer look at the OBTs
Star Schema vs OBT (One Big Table) data modeling is another ongoing debate in data engineering practitioners. The author making a case where the growing need for the real-time data analytics, the adoption of OBT model will continue to grow.
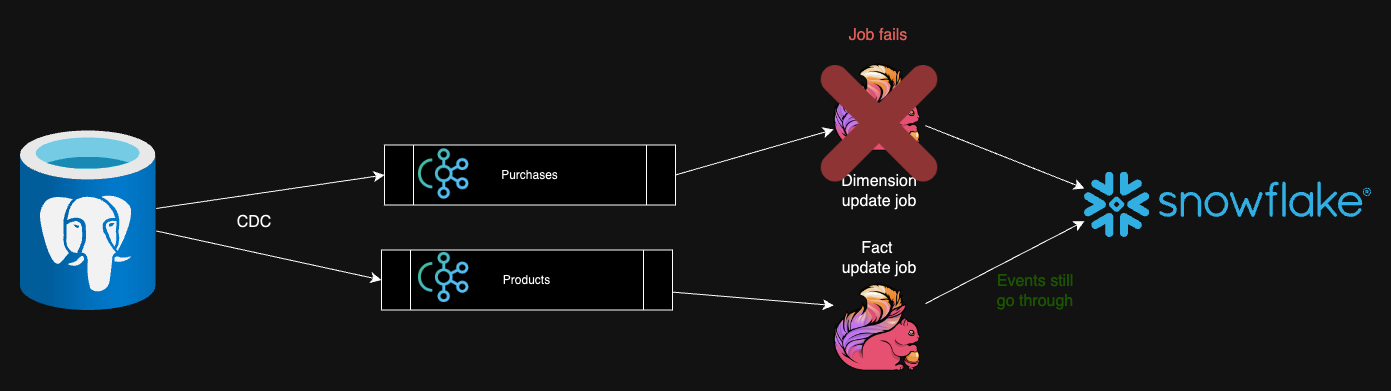
Jonathan Merlevede: Quack, Quack, Ka-Ching - Cut Costs by Querying Snowflake from DuckDB

Many data pipeline process incremental data, which is not a lot in many business cases. Is massive scale data warehouses like Snowflake or data processing engines like Spark require for incremental processing? I guess not; at the same time the underlying architecture should support incremental data processing. I assume there will be a growing adoption of simpler data processing systems like DuckDB for incremental data processing. However the success depends on its flexibility, and ease of integration. The limitations like below is definitely a cognitive block for adoption. I’m surprised that the DuckDB community has not addressed these interoperability concerns.
Unfortunately, this is not immediately helpful for querying from DuckDB. There is no Snowflake catalog SDK available for DuckDB. Luckily, we can use the file system directly to read our data.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.