
Data Engineering Weekly #176
The Weekly Data Engineering Newsletter

Experience Enterprise-Grade Apache Airflow
Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more.
Databricks: Open Sourcing Unity Catalog
This week brought many exciting developments, with Snowflake and Databricks announcing open-source catalogs. Unity Catalog's source code is available on GitHub, and people have already conducted exciting experiments with it. [Unity Catalog OSS with Hudi, Delta, Iceberg, and EMR + DuckDB].
One of the big benefits of having a Hive Meastore catalog is that it enables many query engines to build executing engines on top of it, which creates a strong ecosystem. I’m excited to see what Unity Catalog and Polaris Catalog bring.
https://www.databricks.com/blog/open-sourcing-unity-catalog
NVIDIA: NVIDIA Releases Open Synthetic Data Generation Pipeline for Training Large Language Models

High-quality training data plays a critical role in the performance, accuracy, and quality of responses from a custom LLM. Regulative requirements and privacy concerns are often a big hurdle to training context-rich data. The paper Generative AI for Synthetic Data Generation: Methods, Challenges, and the Future highlights the current challenges and opportunities with synthetic data generation to train LLMs. Along the same line, NVIDIA open sources nmotran4 give developers a free, scalable way to generate synthetic data that can help build powerful LLMs.
https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-llm-training/
Jack Vanlightly: A Cost Analysis Of Replication Vs. S3 Express One Zone In Transactional Data Systems

S3 Express One Zone, with low latency and write ops certainty, is promising. The author demonstrates a few emerging architecture patterns around the S3 Express One Zone and points out that it can offer low-latency writes suitable for high-throughput workloads; it becomes cost-effective mainly for high-throughput scenarios. Replication-based systems remain more economical at low to medium throughputs, especially with significant cross-AZ data transfer discounts.
Sponsored: GenAI Cookbook - Discover Essential Airflow Recipes to Kickstart Your Generative AI Projects

With recent leaps in Generative AI, more and more teams are being asked to implement these use cases. This GenAI Cookbook is a starting place that will guide you through the technical and architectural requirements for building enterprise applications powered with AI and Airflow, including step-by-step instructions and real-world use cases.
Walmart: Reliably Processing Trillions of Kafka Messages Per Day
Consumer rebalancing and Head-of-line (HOL) blocking are some of the most common challenges while operating Kafka at scale. The recent KIP-932 proposal suggests a message proxy service (MPS) for Kafka to decouple the Kafka message_reader thread (i.e., a group of 1 thread) and message_processing_writer threads. The blog explains KIP-932 and its potential benefits. I’ve not read through the KIP-932 proposal, but I remember Uber doing a similar design in the past with Enabling Seamless Kafka Async Queuing with Consumer Proxy.
Yousry Mohamed: Delta Lake Liquid Clustering — A visual explanation

Liquid clustering liberates the hive-style static partitioning and organizes the data layout from the accessing pattern. The author explains the available pattern and provides an in-detail view of the Hilbert Curve Assignment. The official design document for liquid clustering is here.
https://levelup.gitconnected.com/delta-lake-liquid-clustering-a-visual-explanation-b9d8782a9f33
Sponsored: Enhance your data orchestration with DoubleCloud's Managed Airflow.
DoubleCloud has taken the robust capabilities of Apache Airflow and enhanced them with a fully managed service, providing you with a comprehensive toolkit for creating, scheduling, and monitoring workflows with unparalleled ease! With DoubleCloud's Managed Airflow, you get: -Hassle-free infrastructure management -Auto-scaling for effortless performance -Quick start with pre-packaged libraries.

Apply for early access and achieve effective data orchestration in under 10 minutes!
https://double.cloud/services/managed-airflow/
Meta: Maintaining large-scale AI capacity at Meta
Meta uses bespoke training hardware with the newest chips possible and high-performance backend networks that are highly speed-optimized. It discusses the maintenance issues that Meta discusses in the OpsPlanner orchestrator for managing the GPU overlapping workloads.
Sören Brunk: Using DuckDB for Embeddings and Vector Search
The simplicity of DuckDB is an exciting part, and that combines with its advanced capabilities. The author highlights the power and flexibility of DuckDB for handling embeddings and performing vector searches.
https://blog.brunk.io/posts/similarity-search-with-duckdb
Picnic: Open-sourcing dbt-score: lint model metadata with ease!
The more metadata there is, the more readability of the model. It is often challenging as developers are not incentivized to produce quality metadata. Picnic writes about dbt-score, a non-opinionated, configurable linting tool to measure the completeness of dbt model metadata.
https://blog.picnic.nl/picnic-open-sources-dbt-score-linting-model-metadata-with-ease-428278f9f05b
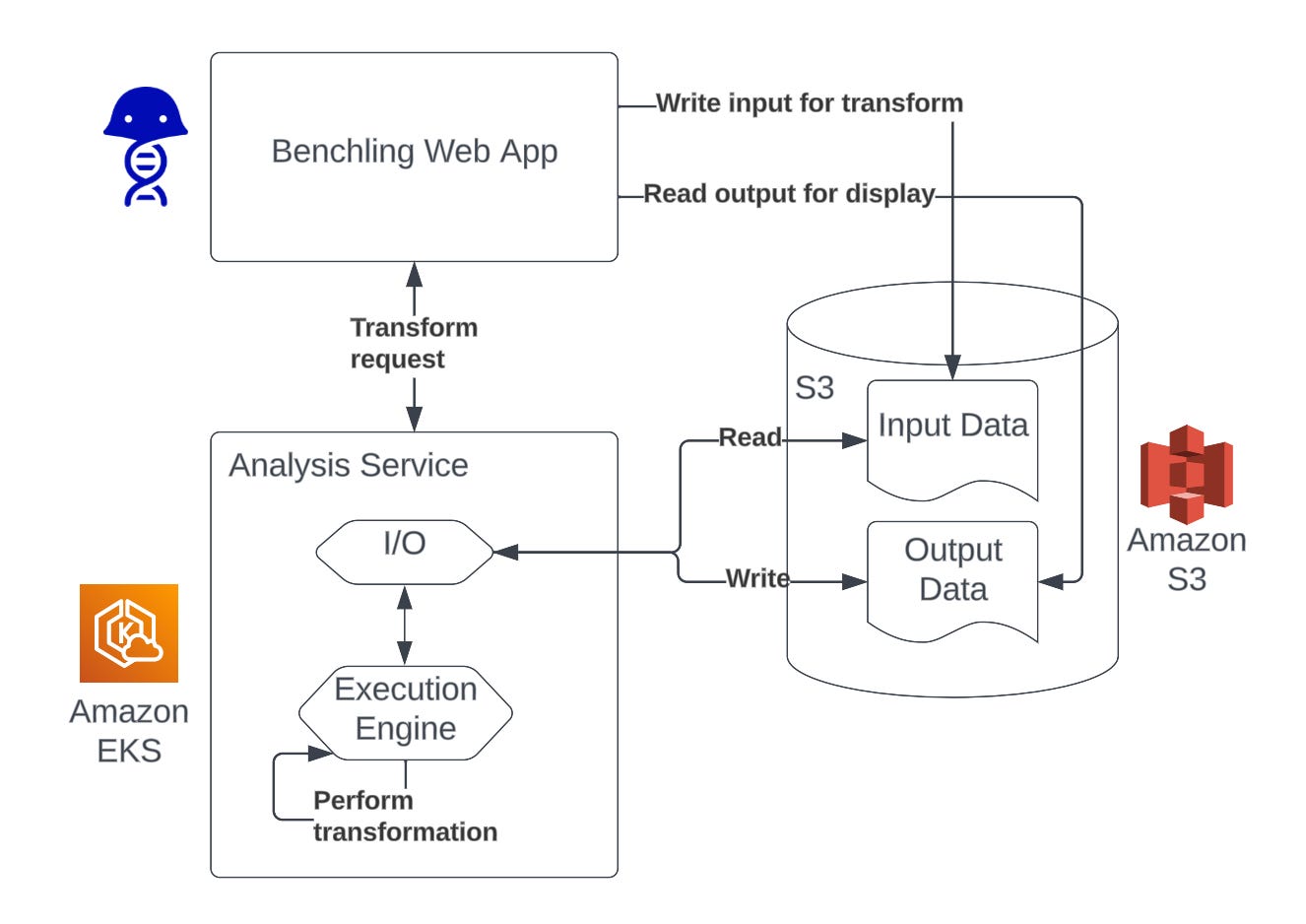
Benchling: A behind-the-scenes look at building interactive analysis capabilities in Benchling
Interactive Analysis in Benchling allows scientists to perform real-time data transformation, visualization, and analysis without transferring it into other systems. The article highlights the architectural pattern and how it handles scalability and data sharing among apps.
Alibaba: In-depth Application of Flink in Ant Group Real-time Feature Store
Alibaba talks about Ant Group’s real-time feature store, SkyLine. Skyline involves three key stages: computing inference, normalization, and deployment. The article goes in-depth on each layer and the optimization of SkyLine to build efficient feature serving.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.