
Data Engineering Weekly #179
The Weekly Data Engineering Newsletter

Experience Enterprise-Grade Apache Airflow
Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more.
Notion: Building and scaling Notion’s data lake
Notion writes about scaling the data lake by bringing critical data ingestion operations in-house.

Notion migrated the insert heavy workload from Snowflake to Hudi. Hudi seems to be a de facto choice for CDC data lake features.
Notion migrated the change data capture pipeline from FiveTran to Debezium.
The architecture resulted in over a million dollars in cost savings!!!
https://www.notion.so/blog/building-and-scaling-notions-data-lake
DoorDash: Beyond the Click: Elevating DoorDash’s Personalized Notification Experience with GNN Recommendation
DoorDash writes about Graph Neural Network (GNN) models to create personalized restaurant recommendations. The blog highlights the advantages of GNN over traditional machine learning models, which struggle to discern relationships between various entities, such as users and restaurants, and edges, such as order.

https://doordash.engineering/2024/06/25/doordash-customize-notifications-how-gnn-work/
Jack Vanlightly: Understanding Apache Paimon's Consistency Model Part 1
Table formats are definitely a hot topic in the industry now. Apache Paimon is a relatively low-key format spun out of Flink’s table store. The author highlights Paimon’s consistency model by examining the metadata model. The dataset organization as a set of LSM trees seems an interesting approach, which sounds similar to Google’s Napa data warehouse system.
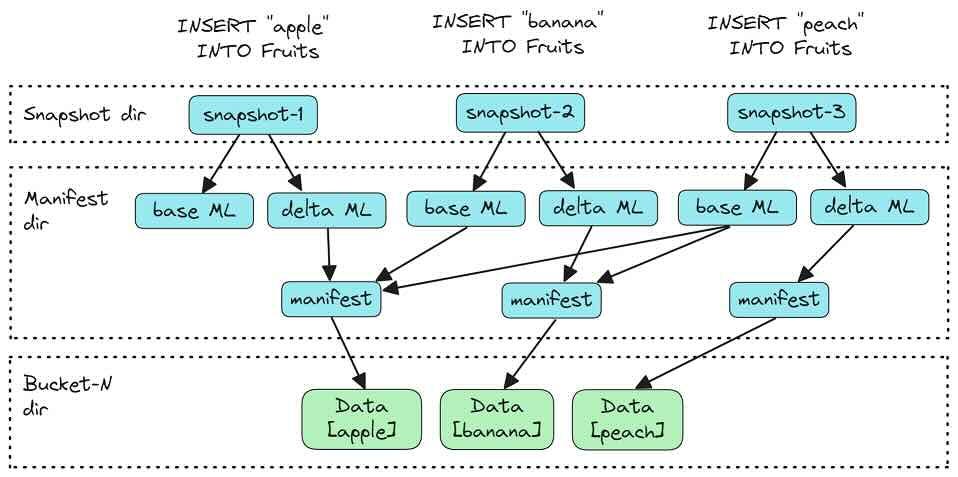
https://jack-vanlightly.com/analyses/2024/7/3/understanding-apache-paimon-consistency-model-part-1
Sponsored: Elevate Your Airflow DAG Debugging Skills With This Free Online Course

Are you spending too much time trying to debug your Airflow DAGs? In less than 30 minutes, this free comprehensive course from Astronomer Academy will guide you through a straightforward approach to recognizing and resolving the most common debugging issues.
Canva: How we build experiments in-house
Experimentation is a vital part of product design for any company of any scale. Canva writes about the evolution of experimentation system design and the current state of the function.
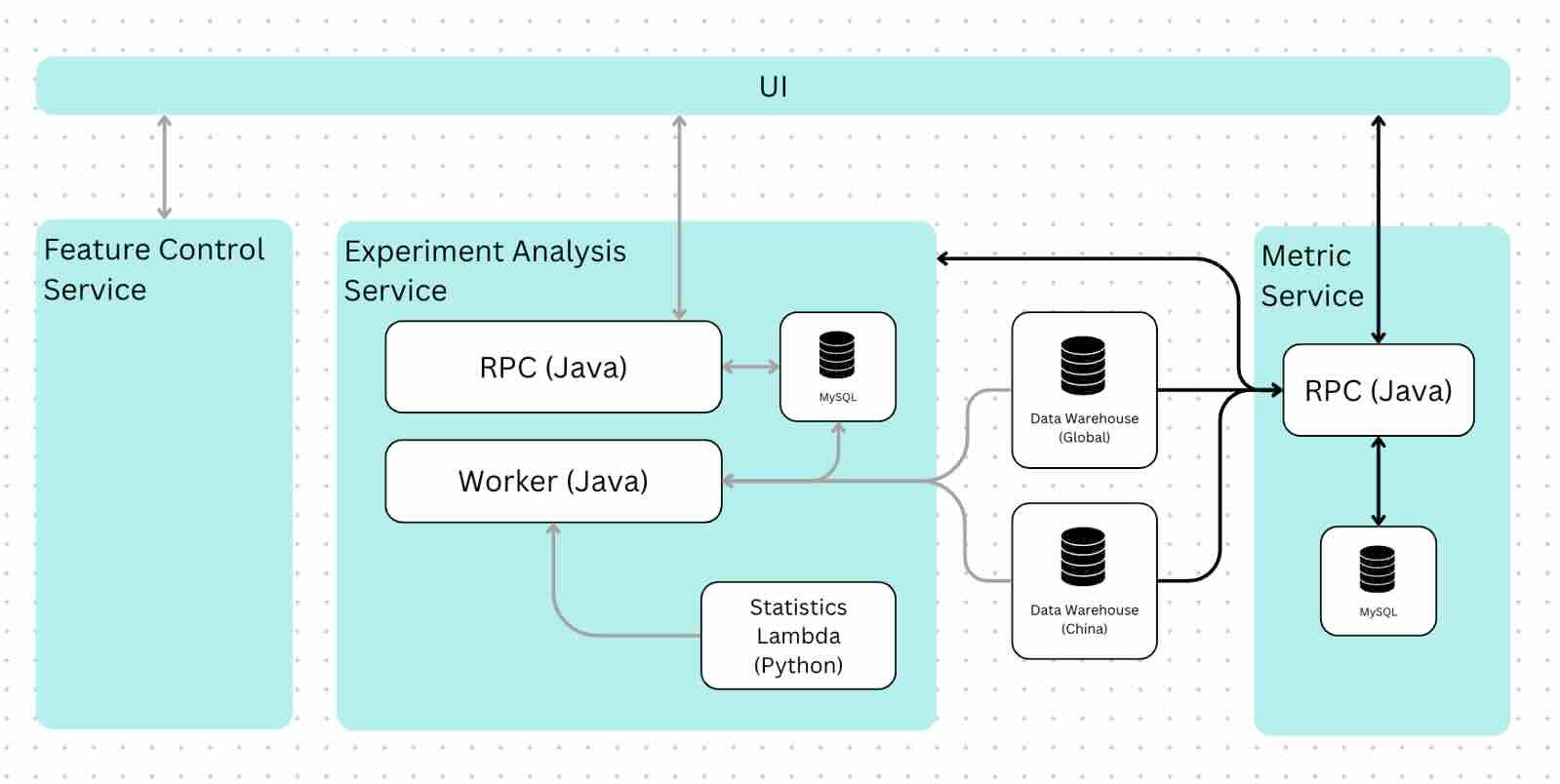
https://www.canva.dev/blog/engineering/how-we-build-experiments-in-house/
Slack: Unlocking Efficiency and Performance: Navigating the Spark 3 and EMR 6 Upgrade Journey at Slack
Migration of a large-scale data infrastructure brings its challenges. Slack writes about migrating its data infrastructure to EMR 6 and Spark 3. The blog highlights the pre-migration and post-migration steps, highlighting the importance of structured execution on such large-scale migration projects.
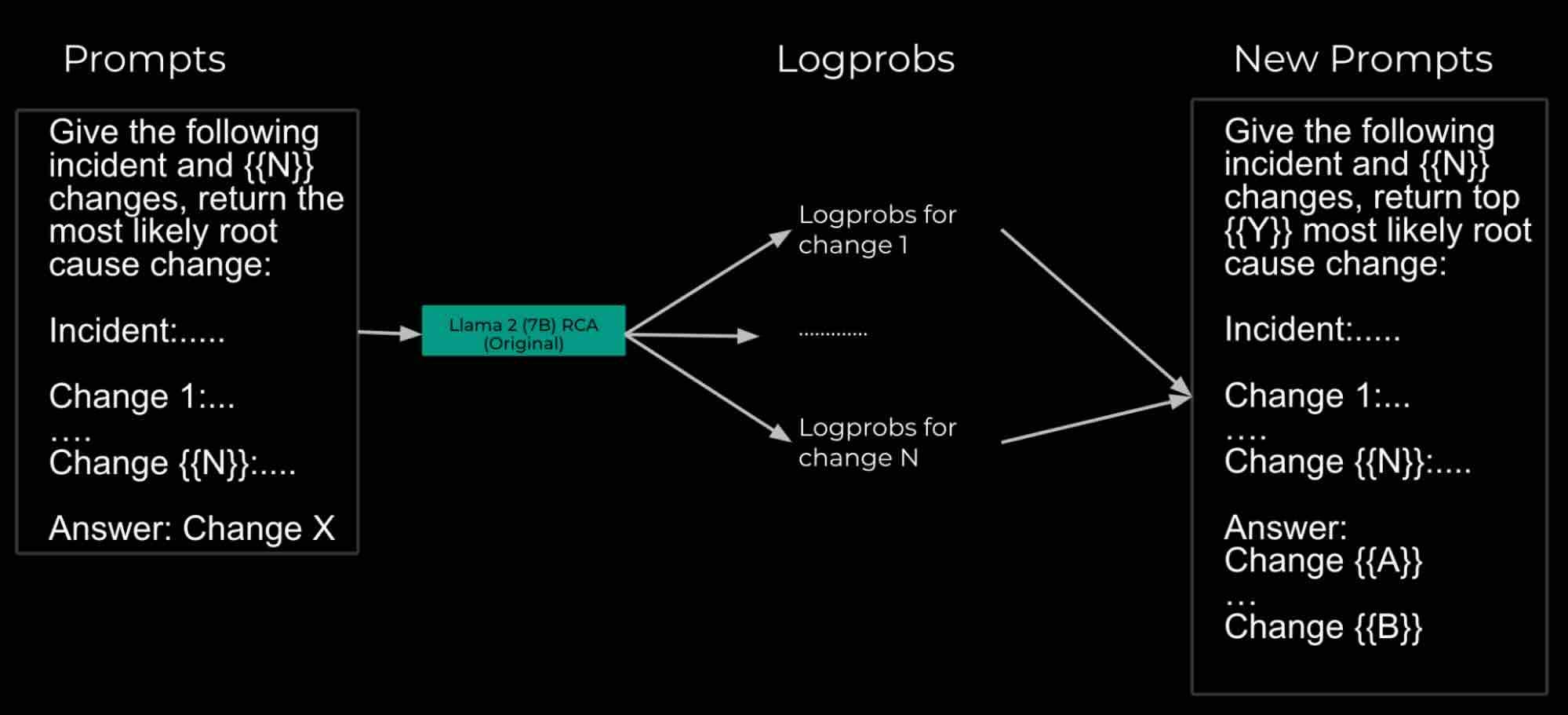
Meta: Leveraging AI for efficient incident response
The incident analysis is a vital part of the incident management lifecycle process to find the hidden flaws of the system design and prevent future issues. Meta writes about its usage of AI to understand the effectiveness of the incident response and root cause analytics.
Ling Huang: MLOps — Data Drift Monitoring Architecture
Drift detection is a popular feature supported by data observability tools. The essence of drift monitoring is running statistical tests on time windows of data. The blog gives an overview of statistical techniques used in drift detection.
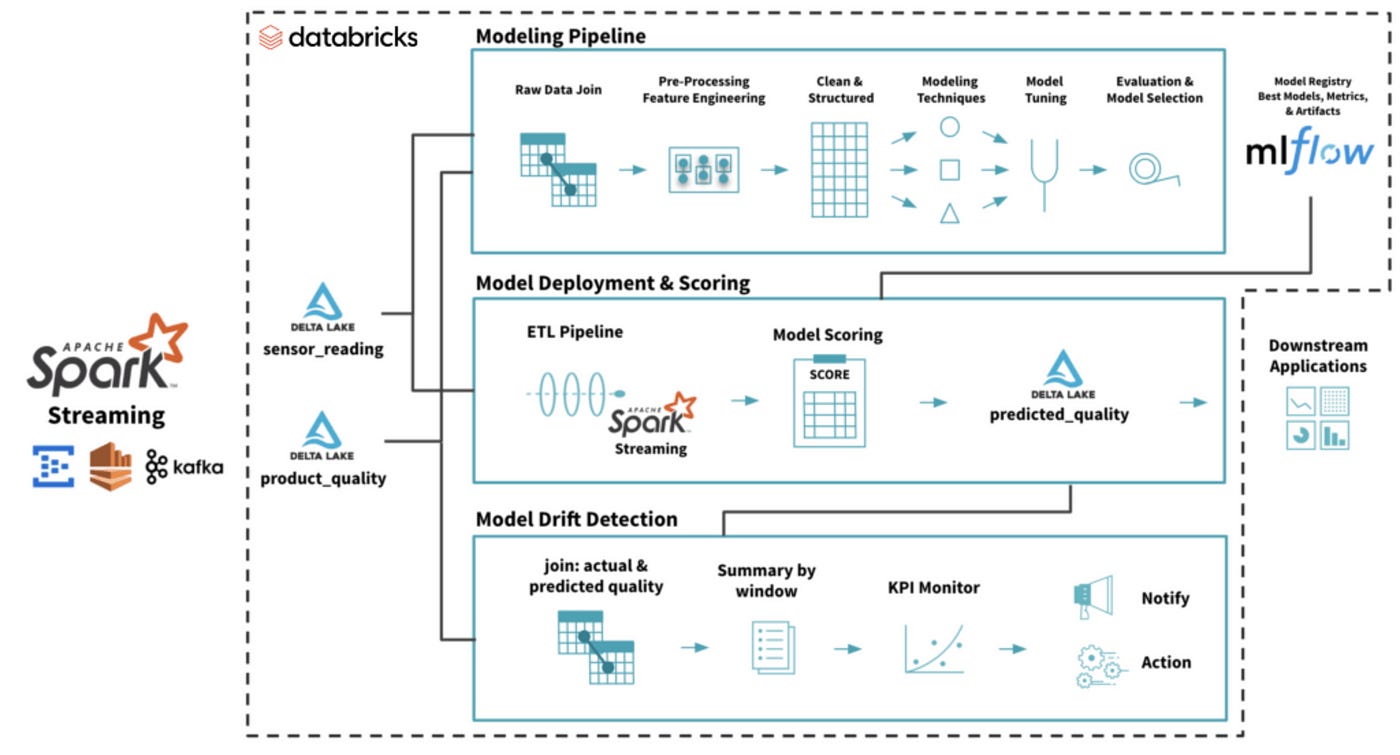
https://medium.com/@linghuang_76674/drift-monitoring-architecture-aa57fc26a19c
Lam Hoang: How Chunk Sizes Affect Semantic Retrieval Results
Chunking is a crucial technique that involves breaking down large pieces of text into smaller, more manageable segments. This process is particularly important when working with large language models (LLMs) and semantic retrieval systems. The X thread is a good reference for measuring the relevancy of a vector search.

The blog highlights how the chunk size impacts the vector search and choosing the optimal size.
https://ai.plainenglish.io/investigating-chunk-size-on-semantic-results-b465867d8ca1
Diederik Jan Lemkes: How to choose between dbt clone and defer. And how we clone for all contributors
The article discusses strategies for using production data in dbt development environments without high costs or permissions. It compares two dbt features - defer and clone - for referencing production tables, ultimately favoring a nightly cloning approach for specific models. The authors implement this using Airflow's dynamic task mapping to automatically clone tagged models to each contributor's development dataset, allowing seamless dbt builds with production-like data.
Guillermo Musumeci: How To Calculate the Real Cost of Azure Databricks SQL Warehouse Instances
The databricks billing on Azure is a bit confusing. Most of the billing goes via the Azure system, where the deduction happens via negotiated billing with Daabricks. Software manufacturing and distribution are indeed different art. The blog explains how we can programmatically measure the real cost of Azure databricks SQL warehouse instances.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.