
Data Engineering Weekly #181
The Weekly Data Engineering Newsletter

Editor’s Note: A New Series on Data Engineering Tools Evaluation
There are plenty of data tools and vendors in the industry. But how can we choose a tool for the specific need? The traditional evaluation of running PoC on all the selected vendor tools is time-consuming and practically unviable for growth-driven companies.
Data Engineering Weekly is launching a new series on software evaluation focused on data engineering to better guide data engineering leaders in evaluating data tools. We are starting with Change Data Capture tools and expanding to other categories. Stay tuned!!!
Jessica Lachs: Starting an Analytics Org From Scratch — Lessons From a Decade at DoorDash
A strong foundational analytical function is vital to making informed decisions, operational efficiency, and competitive differentiation. The author highlights key lessons learning building an analytical org from scratch with key highlights,
1. Focus on Needs Over Nomenclature: Define the outcomes you want from your analytics team instead of getting caught up in the semantics of terms like analytics, data science, and business intelligence.
2. The Three C’s of Analytics: Emphasize data creation, curation, and consumption. Build reliable data, maintain usable data models, and ensure the data is interpreted correctly for decision-making.
3. Hiring the Right Team: Start with generalists who possess both technical and soft skills. As the organization grows, bring specialists to fill specific gaps and ensure a strong, adaptable team.
Gwen Shapira: Everything a developer needs to know about Generative AI for SaaS
Gen AI is a past moving that often overwhelms you if you start exploring it. What initially everyone thought of as simple prompts in English has more of an engineering effort than it appears to be. The blog is an excellent summary of what one needs to know about Gen-AI to start.

https://www.thenile.dev/blog/all-about-ai
Lilian Weng: Extrinsic Hallucinations in LLMs
The article "Extrinsic Hallucinations in LLMs" explores the causes and solutions for hallucinations in large language models (LLMs). It addresses pre-training data issues and the challenges of fine-tuning with new knowledge, presenting methods for detecting hallucinations, such as retrieval-augmented evaluation and sampling-based detection. Additionally, the article discusses anti-hallucination techniques like RAG, fine-tuning for factuality, and retrieval-augmented generation.
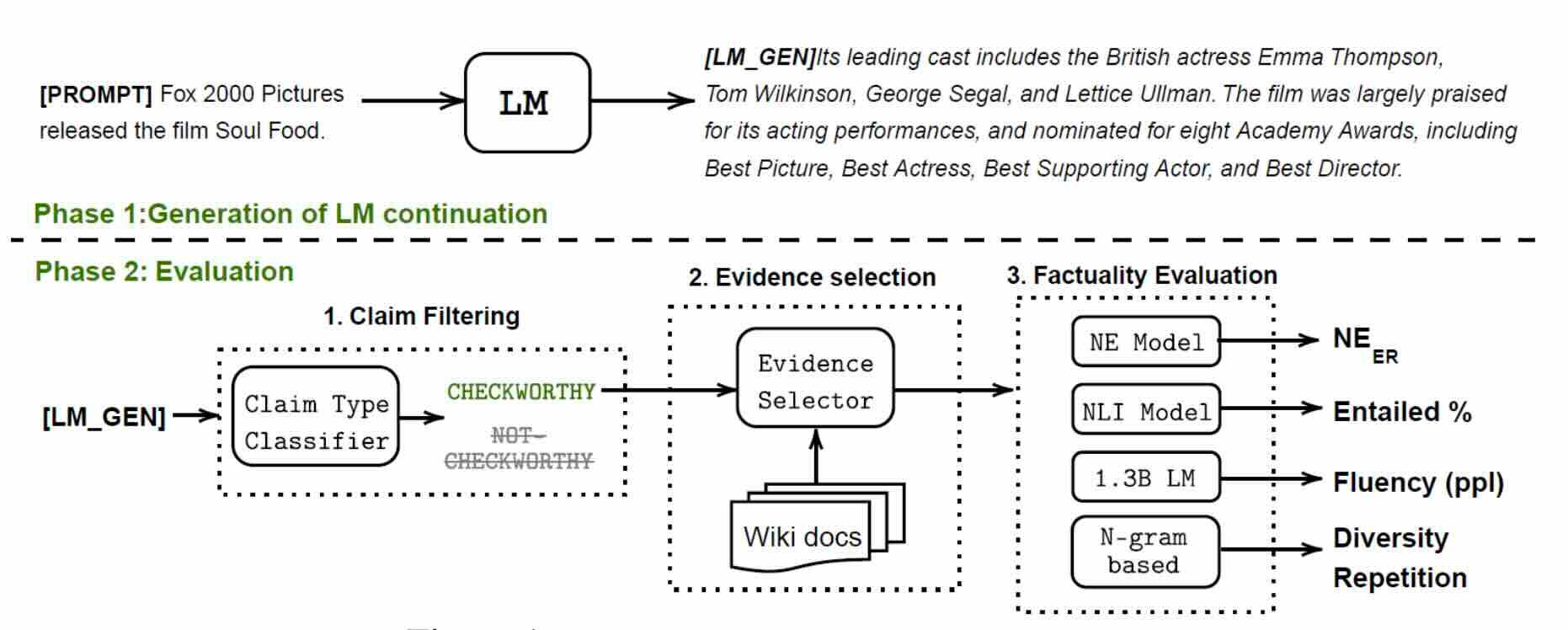
Key insights emphasize the importance of grounding model outputs in factual information and employing retrieval methods to enhance model accuracy and reduce hallucinations.
https://lilianweng.github.io/posts/2024-07-07-hallucination/
Manuel Faysse: ColPali - Efficient Document Retrieval with Vision Language Models 👀
80% of enterprise data exists in difficult-to-use formats like HTML, PDF, CSV, PNG, PPTX, and more. The current extraction models from unstructured data often rely on OCR and layout detection to process text and images separately, leading to potential indexing errors and inefficiencies.
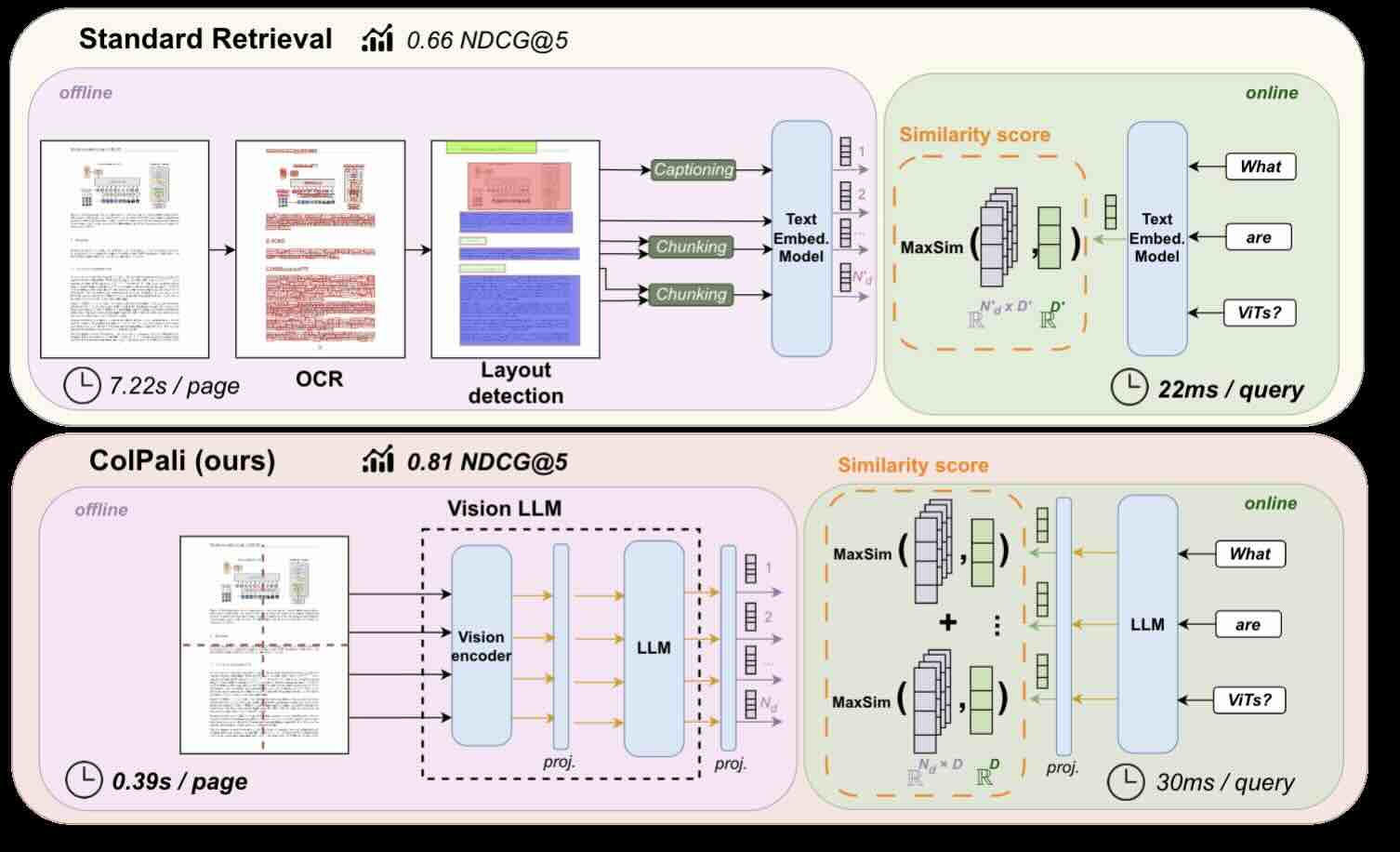
ColPali’s approach integrates visual and textual cues more effectively, reducing indexing complexity and enhancing retrieval performance. It's an interesting method to keep track of it.
https://huggingface.co/blog/manu/colpali
Vimeo: Unlocking knowledge sharing for videos with RAG
One of the most significant impacts of large language models (LLMs) is their ability to make information retrieval from multimedia content more accessible. Vimeo discusses its Retrieval-Augmented Generation (RAG) system design for building a knowledge management system. Their bottom-up approach to sentence chunking and entity detection in video conversations is particularly exciting and worth reading about.

Sync Computing: Top 9 Lessons Learned about Databricks Jobs Serverless
Is serverless computing optimal for all workloads? What is the cost-fit function with serverless vs managed infrastructure?

The Sync computing experiments concluded that serverless computing on Databricks is not always cost-effective. It is ideal for short/ad-hoc jobs due to no spin-up time, but it offers limited control and poses migration challenges.
Personally, I like the flexibility of not worrying about upgrades and infrastructure. What is your experience with Databricks serverless compute? Please comment.
Klaviyo: Continuous Integration with dbt
Adopting the devops principle in the analytical pipeline is every data team's quest. The Klaviyo team writes about its continuous integration with dbt using Dbt cloud’s Slim CI.
Part 1: https://klaviyo.tech/continuous-integration-with-dbt-c0746d62271c
Part 2: https://klaviyo.tech/continuous-integration-with-dbt-part-2-47c093a0548e
The article How to Create CI/CD Pipelines for dbt Core explains in-depth how the Slim CI works.
Adevinta: Artemis - Fostering Autonomy in Monitoring Data Quality
Artemis is Adevinta's innovative system that enhances data quality monitoring by granting teams greater autonomy. Artemis promotes proactive data issue management by allowing teams to define their own data quality checks and set up alerts. It is exciting to see more focused frameworks for data quality, but the success lies in how well these systems integrate with the workflow orchestration engines.

Oracle: A Quick Introduction to JavaScript Stored Programs in MySQL
I found this very interesting: a javascript engine on top of a database!! The blog compares the advantages of Javascript-stored programs vs. SQL-stored programs.

In the data warehouse, the programming abstraction standard is around SQL and dataframes. The last attempt with something different is Apache Pig, which quickly fades out of popularity. The closest I can think of similar to PL/SQL is dbt, a Python wrapper on top of SQL. We have seen a lot of standardization on table formats; will we see standardization for dbt-like systems?
https://blogs.oracle.com/mysql/post/a-quick-introduction-to-javascript-stored-programs-in-mysql
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.