
Data Engineering Weekly #182
The Weekly Data Engineering Newsletter

Meta: Introducing Llama 3.1: Our most capable models to date
Probability one of the hottest announcements this week is Llama 3.1 release - the first-ever open-sourced frontier AI model competitive with leading foundation models across a range of tasks, including GPT-4, GPT-4o, and Claude 3.5 Sonnet.
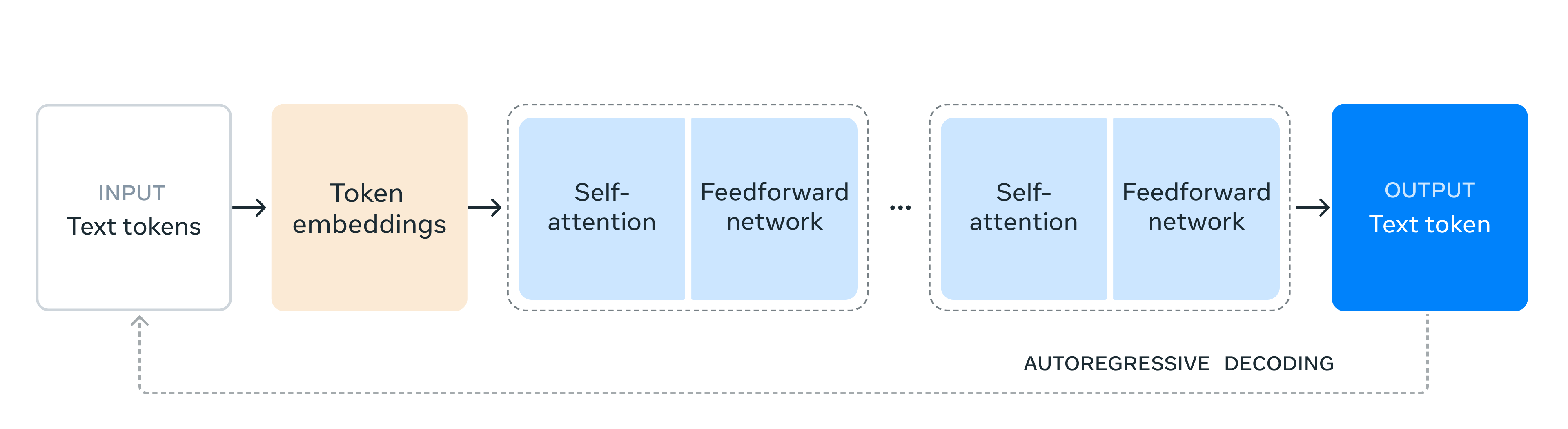
The Llama3 herd of models is an insightful paper that helps one deeply understand the foundational model.
https://ai.meta.com/blog/meta-llama-3-1/
Chip Huyan: Building A Generative AI Platform
We can’t deny that Gen-AI is becoming an integral part of product strategy, pushing the need for platform engineering. The blog is an excellent summarization of the common patterns emerging in GenAI platforms.

https://huyenchip.com/2024/07/25/genai-platform.html
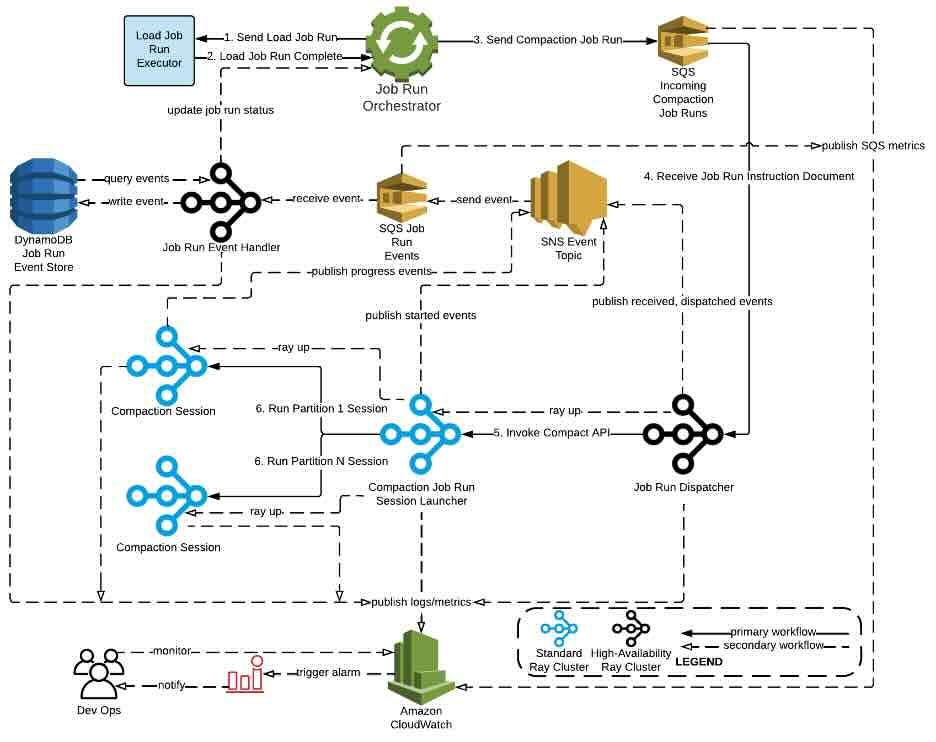
AWS: Amazon’s Exabyte-Scale Migration from Apache Spark to Ray on Amazon EC2
Amazon’s migration from Apache Spark to Ray is possibly the most fascinating read of recent times. Amazon discusses their CDC use cases and the challenges with Apache Spark in running copy-on-write at scale. Switching from Apache Spark to Ray improves compact 12X larger datasets than Apache Spark, improves cost efficiency by 91%, and processes 13X more data per hour.
Instacart: Data Science Spotlight - Cracking the SQL Interview at Instacart (LLM Edition)
Instacart writes about integrating LLM in their interview process and how it helps them identify the right candidates. I like testing people on their practical knowledge rather than artificial coding challenges.
Adopting LLM in SQL-centric workflow is particularly interesting since companies increasingly try text-2-SQL to boost data usage. Swiggy recently wrote about its internal platform, Hermes, a text-to-SQL solution. The blog Prompt Engineering for a Better SQL Code Generation With LLMs is a pretty good guide on applying prompt engineering to improve productivity.
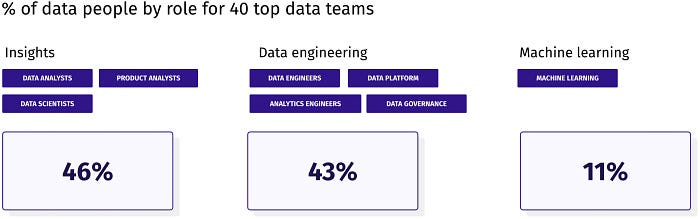
Mikkel Dengsøe: How top data teams are structured
What would the correct ratio of the number of data engineers corresponding to the overall people count in an organization? What are the different roles inside the data engineering functions, and what should their ratio be? The author provides insights into how the companies are structured and how the data engineering population compares to the overall employee population in an organization.
https://medium.com/@mikldd/how-top-data-teams-are-structured-48d46a64b990
Netflix: Maestro - Data/ML Workflow Orchestrator at Netflix
Netflix open-sources its workflow orchestration engine, Maestro, which is already close to 2000+ likes on Github. JSON workflow definition gives flexibility to build DSL on higher-level languages like Python & Java. Though I understand the motivation behind a custom SEL (Safe Expression Language), it might increase the learning curve.

A key highlight for me is the following features from Maestro.
Rollup support and the fact they wrote about it.
Pipeline breakpoint feature.
https://netflixtechblog.com/maestro-netflixs-workflow-orchestrator-ee13a06f9c78
Uber: Introduction to Kafka Tiered Storage at Uber
The effectiveness of Kafka Tiered-Storage is a widely discussed topic. It can always lead to unexpected side effects, as noted in the recent Honeycomb blog Investigating Mysterious Kafka Broker I/O When Using Confluent Tiered Storage.

Uber writes a comprehensive guide on Kafka’s tiered storage and explains the interface design, which helps you write your tiered storage support.
https://www.uber.com/blog/kafka-tiered-storage/
Booking.com: The Engineering Behind High-Performance Ranking Platform: A System Overview
Booking.com writes about its ranking platform, which is pivotal in its wider search platform. The blog highlights key challenges with building a system with a subsecond latency and three 9’s availability.

Databricks: Databricks on Databricks - Kicking off the Journey to Governance with Unity Catalog
It is always exciting to read how you internally use a tool you build and sell to your customers. Databricks shares one such story: adopting Unity Catalog and its migration journey from the Hive Meta Store.

The phase-by-phase approach is an excellent case study for migrating your data catalogs to the unity catalog.
https://www.databricks.com/blog/databricks-databricks-kicking-journey-governance-unity-catalog
Murat Demirbas: Understanding the Performance Implications of Storage-Disaggregated Databases
Serverless of anything (Postgres, Kafka, Redis) is the hot trend in infrastructure development. Decoupling computing from storage allows for independent and elastic scaling of computing and storage resources. The blog highlights the 2024 Sigmod paper Understanding the Performance Implications of the Design Principles in Storage-Disaggregated Databases.

The author summarizes the key design principles of disaggregated databases, including:
Software-level Disaggregation (P1): Decoupling the storage engine from the compute engine.
Log-as-the-Database (P2): Sending only write-ahead logs to the storage side upon transaction commit.
Shared-Storage Design (P3): Allowing multiple compute nodes to share the same storage.
Performance is always a key question when storage and computing are separated, and the author highlights that buffering reduces the performance gap between disaggregated and non-disaggregated databases.
https://muratbuffalo.blogspot.com/2024/07/understanding-performance-implications.html
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.
Really cool topics!