
Data Engineering Weekly #183
The Weekly Data Engineering Newsletter


Try Fully Managed Apache Airflow for FREE
Run Airflow without the hassle and management complexity. Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. For a limited time, new sign-ups will receive a complimentary Airflow Fundamentals Certification exam (normally $150).
Editor’s Note: The Data Engineering Evaluation Series
For the last two weeks, we met several CDC experts and multiple iterations of preparing the evaluation guide for CDC tools. The CDC evaluation guide will be an open license to distribute and contribute freely. Thank you, everyone, for contributing to the evaluation guide. We will be releasing the CDC guide next Wednesday!! Stay Tuned.
As the next edition of the evaluation series, we are looking to take Data Observability. We would like to hear from you if you have an opinion on data observability evaluation or have done any recent evaluations. Please DM us through LinkedIn; Let’s connect!!!
Snowflake: Polaris Catalog Is Now Open Source
It is finally here. Snowflake opensource Polaris catalog, an Apache Iceberg’s REST catalog specification. The Iceberg’s REST catalog support naturally extends to supporting Doris™, Apache Flink™, Apache Spark™, Daft, DuckDB, Presto, SingleStore, Snowflake, Starburst, Trino, Upsolver, and more, and I’m sure more to follow.
From this vantage point, it seems data lakehouse vendors have accidentally stumbled upon the wedge that traditional data catalogs have been struggling to find. - Chris Riccomini https://twitter.com/criccomini/status/1808554909375344719
It will be interesting to observe the convergence of technical and governance catalogs within the emerging trend of open-source data catalog implementations, as these catalogs have historically been separate entities.
https://www.snowflake.com/blog/polaris-catalog-open-source/
Jason Liu & Eugene Yan: 10 Ways to Be Data Illiterate (and How to Avoid Them)
If you ask any executives in an organization, they will say they are data-driven. It is often an expression of desire rather than reality. Thus, the data team has more responsibility than just ingesting and building the data pipeline. The blog makes an excellent point on what makes data illiterate. I’m curious how data platforms can automate such things to make these mistakes disappear.
https://jxnl.co/writing/2024/06/02/10-ways-to-be-data-illiterate-and-how-to-avoid-them/
Pinterest: Delivering Faster Analytics at Pinterest
Pinterest writes about its adoption of StarRocks and migration from Apache Druid. The migration yields Pinterest a 50% reduction in p90 latency and a 3-fold reduction in cost.

The Archmage thrift proxy layer to hide the infrastructure and enable easier version upgrades is a good engineering practice that I would recommend for any platform team.
https://medium.com/pinterest-engineering/delivering-faster-analytics-at-pinterest-a639cdfad374
Sponsored: Full-Stack Orchestration in the Age of the Data Product

Modern, full-stack orchestration unifies observability across all layers of your data environment, enhancing data product reliability, increasing development speed, and lowering costs. This guide provides key insights into developing a unified data orchestration framework that enhances data reliability, business agility, and operational efficiency.
Uber: How Uber Accomplishes Job Counting At Scale
Uber writes about using Apache Pinot to serve subsecond latency analytics at scale. The blog narrates the challenges of implementing Apache Pinot at scale and the optimization techniques in Pinot to yield high performance. The p99 read latency of ~1 second is impressive, considering Uber’s scale.

https://www.uber.com/en-GB/blog/job-counting-at-scale/
Dune: How we've improved Dune API using DuckDB
Continuing our case studies with low latency, user-facing analytics stories from Pinterest and Uber, Dune writes about its usage of DuckDB. I am interested in the emerging pattern around DuckDB.
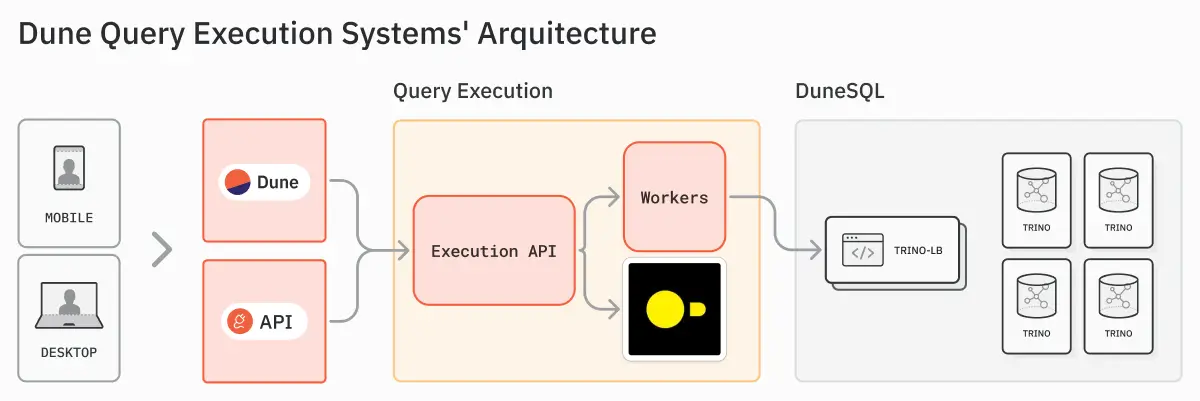
Dune writes about its re-architecture of introducing DuckDB as a caching layer with Trino to make interactive queries run faster.
https://dune.com/blog/how-weve-improved-dune-api-using-duckdb
Jack Vanlightly: Understanding Apache Hudi's Consistency Model
Consistency models are crucial in Lakehouse formats because they define the rules governing how and when data updates are visible to different users and processes.

The blog is an excellent overview of the consistency model in Apache Hudi. The author provides a comprehensive guide on other Lakehouse consistency models, which we will cover in later editions.
https://jack-vanlightly.com/analyses/2024/4/24/understanding-apache-hudi-consistency-model-part-1
https://jack-vanlightly.com/analyses/2024/4/24/understanding-apache-hudi-consistency-model-part-2
https://jack-vanlightly.com/analyses/2024/4/25/understanding-apache-hudi-consistency-model-part-3
Dipankar Mazumdar: Hudi-rs with DuckDB, Polars, Daft, DataFusion — Single-node Lakehouse
Data exploration for data science and machine learning typically requires a sample data set to be available for faster iteration. Hudi-rs project is an interesting one that provides an abstraction to bring part of Hudi data to DuckDB for interactive analytics.

If you want to expose Apache Hudi table to data scientists or sub-second latency user-facing analytics, Hudi-rs fits perfectly into the bill.
Bwilliams: Token efficiency with structured output from language models
Most LLM chat & embedding APIs charge the users by the number of tokens per request model. I won’t be surprised to hear the term “Token Tax” soon, as AI companies want to be profitable. The article analyzes methods to optimize token usage, particularly in creating JSON and YAML formats. It also introduces innovative constrained generation techniques that promise to revolutionize how we approach structured data generation.
Walmart: Using Predictive and Gen AI to Improve Product Categorization at Walmart
With over 400 million SKUs, Walmart writes about using Gen AI to improve product categorization. By incorporating domain-specific features and human-labeled data, Walmart avoids reliance on noisy customer engagement data, thus improving the categorization accuracy for both common and uncommon products on the platform.

Thomson Reuters Labs: Performance Engineering in Document Understanding
Data processing efficiency has taken center stage as we starkly moved away from the big data and massively parallel computing era. We look at efficiency in data processing within a single node, which increases the momentum for systems like DuckDB, Arrow, and Polaris. Rust is becoming a defacto tool for data toolings with excellent Python binding. Echoing a similar trend, Thomson Reuters writes about challenges in processing documents at scale and how it started utilizing Parquet, Arrow, and Polaris to improve efficiency.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.