
Data Engineering Weekly #184
The Weekly Data Engineering Newsletter


Try Fully Managed Apache Airflow for FREE
Run Airflow without the hassle and management complexity. Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. For a limited time, new sign-ups will receive a complimentary Airflow Fundamentals Certification exam (normally $150).
Nicholas Carlini: How I Use "AI"
I don't think that "AI" models (by which I mean large language models) are over-hyped.
But the reason I think that the recent advances we've made aren't just hype is that, over the past year, I have spent at least a few hours every week interacting with various large language models and have been consistently impressed by their ability to solve increasingly difficult tasks I give them.
I second the author’s thoughts here, and I’m sure many share similar experiences. The author wrote a comprehensive article highlighting how LLM helped with tasks that were otherwise much harder.
https://nicholas.carlini.com/writing/2024/how-i-use-ai.html
Paige Bailey: Automating away the boring parts of my job with Gemini 1.5 Pro + long context windows
Following people sharing how LLM improves their quality of life by automating repetitive tasks, the author highlights the use of LLM from a different perspective. The product feedback analysis from Github issues and analyzing user experience from video/ audio are very helpful in enriching knowledge on certain technologies, too.
Sponsored: Join Astronomer for the 10th anniversary of Apache Airflow at this year's AirflowSummit in San Francisco, Sept 10-12

This event will be packed with practical and insightful sessions around everything data orchestration, GenAI, ETL Orchestration, the future of Airflow and more. Check out the sessions and speakers here, and use discount code 30DISC_ASTRONOMER for 30% off your ticket! 🎟️
Malaikannan: Chunking & Embedding
Embedding and chunking are critical natural language processing (NLP) and information retrieval techniques. Embedding transforms the text into dense vector representations that capture semantic meaning, enabling more effective similarity searches, clustering, and classification. On the other hand, chunking refers to breaking down large texts or data into smaller, manageable units, often for more efficient processing or to preserve context. The author writes a comprehensive overview of Embedding and Chunking.

https://malaikannan.github.io//2024/08/05/Chunking/
https://malaikannan.github.io//2024/07/31/Embeddings/
Gwen Shapira: AI Code Assistant SaaS built on GPT-4o-mini, Langchain, Postgres, and pg_vector
AI coding assistant is one of the widely used applications of LLM. What would be the logical next step once you know about embedding & chunking? Well, build your own AI code assistant. The author writes a comprehensive guide on building AI code assistance, and the best part is the code is open source.

https://www.thenile.dev/blog/building_code_assistant
Analytics at Meta: Scaling Analytics @ Instagram: The power of deterministic sampling
As data volumes continue growing, Storing and processing the data that powers these metrics comes with significant costs related to storage, computational resources, and processing power. Meta narrates how it builds deterministic sampling to reduce the event volume and how it helps in testing and QA environments.

Uber: Enabling Security for Hadoop Data Lake on Google Cloud Storage
Uber writes about securing a Hadoop-based data lake on Google Cloud Platform (GCP) by replacing HDFS with Google Cloud Storage (GCS) while maintaining existing security models like Kerberos-based authentication. The blog narrates the development of a layered access model and built a Storage Access Service (SAS) to bridge the security differences between HDFS and GCS, with the implementation of a multi-layer caching strategy to scale the system, enabling the handling of high request volumes with low latency.

https://www.uber.com/blog/securing-hadoop-on-gcp/
Jack Vanlightly: Understanding Delta Lake's consistency model

Jack Vanlightly’s article delves into Delta Lake’s consistency model, highlighting its support for ACID transactional guarantees with a focus on consistency and isolation. Delta Lake uses a write-ahead log (the delta log) to maintain atomicity, and it achieves snapshot isolation for reads through multi-version concurrency control (MVCC). The article also explains the role of optimistic concurrency control in handling multiple concurrent writers, ensuring data integrity, and avoiding conflicts during transactions on Delta Lake.
https://jack-vanlightly.com/analyses/2024/4/29/understanding-delta-lakes-consistency-model
Miles Cole: Decoding Delta Lake Compatibility Between Fabric and Databricks
Miles Cole’s article explores the compatibility issues between Delta Lake implementations in Databricks and Microsoft Fabric, highlighting key differences and challenges. The article provides a detailed compatibility matrix and offers guidance on managing features like Liquid Clustering and V2 Checkpoints to ensure interoperability between different Delta Lake environments. It is a fast-moving field, so I suppose this comparison will get outdated pretty soon.

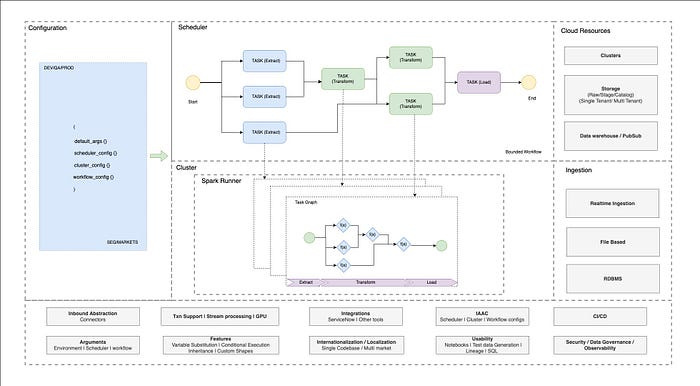
Walmart: Achieve million-dollar savings with unified code and configuration-driven data pipelines
Once the data pipeline reaches a critical adoption, the abstract pipeline brings much-needed standardization to improve developer productivity and reduce cost. Walmart wrote about how it saved millions of dollars with unified configuration-driven data pipelines.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.