
Data Engineering Weekly #185
The Weekly Data Engineering Newsletter


Try Fully Managed Apache Airflow for FREE
Run Airflow without the hassle and management complexity. Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. For a limited time, new sign-ups will receive a complimentary Airflow Fundamentals Certification exam (normally $150).
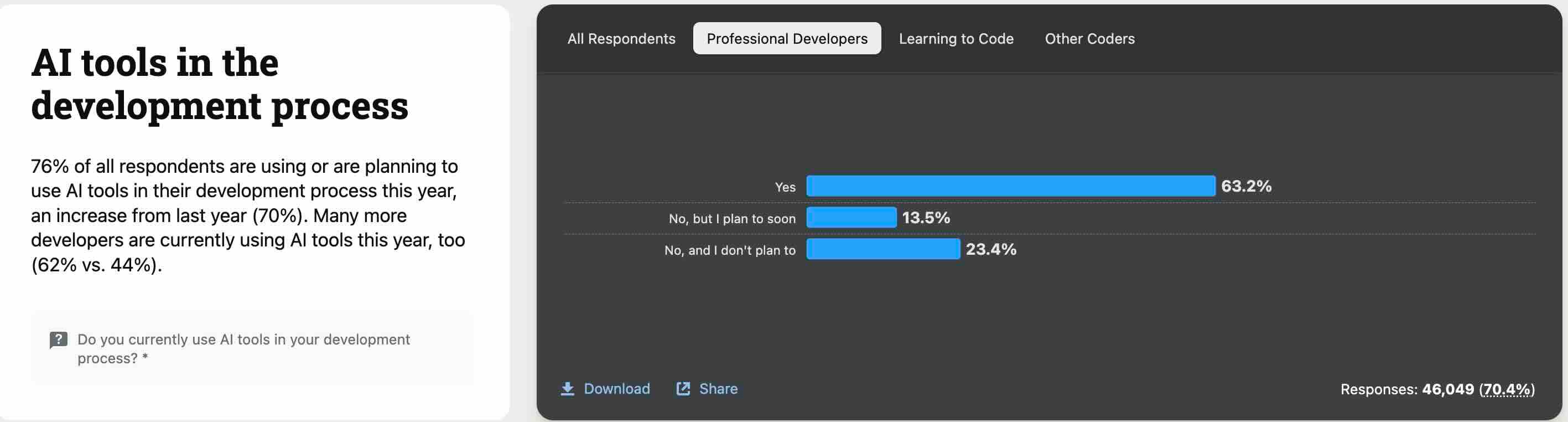
Stack Overflow: 2024 Developer Survey - AI
In last week's edition, we saw a couple of developer stories on how developers use Gen-AI. [How I Use "AI" & Automating away the boring parts of my job]. The recent Stack Overflow survey echoes the statement that the usage of AI tools is gaining popularity in the development process.
https://survey.stackoverflow.co/2024/ai/
Felicis: The agentic web
The blog highlights the current state of agent infrastructure. The next phase of AI innovation will revolve around automating the boring stuff and skills essential to human life, but expertise is hard to obtain. Agents perfectly fit into that, where it expands the scope of LLMs' capabilities by pairing foundation models with customer-specific data, multi-step reasoning, and the ability to take action on users’ behalf.

https://www.felicis.com/insight/the-agentic-web
Sponsored: Airflow 2.10 has landed! 🛬
This latest version of Apache Airflow brings greater flexibility and expansion of some of the most widely used features ✨ Join this webinar for an in-depth look at the features that make Apache Airflow even better:

💫 New data-aware scheduling capabilities
✅ Hybrid execution (allows you to use multiple executors in the same Airflow instance)
🖥️ Updates to the UI, including the widely anticipated dark mode
Wherever you are on your data orchestration journey, don’t miss this chance to learn from the experts and have your questions answered 🙋
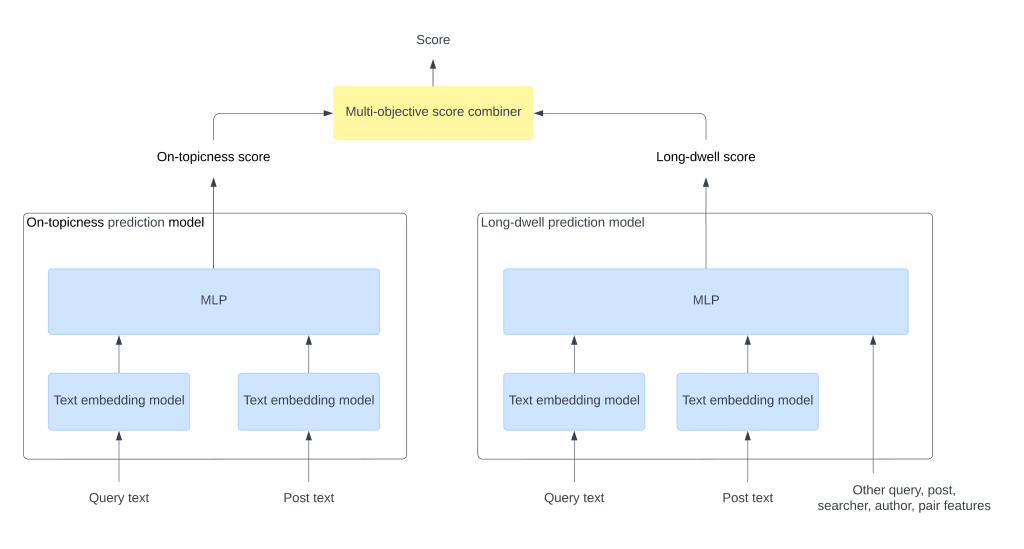
LinkedIn: Introducing Semantic Capability in LinkedIn's Content Search Engine
LinkedIn writes about its semantic search capabilities in content search. The content search engine has two layers: a retrieval layer and a multi-stage ranking layer. When a query is received, the retrieval layer selects a few thousand candidate posts from the overall pool of billions of posts. Then, the multi-stage ranking layer scores these candidate posts in two stages and returns a ranked list of posts.
Etsy: Machine Learning in Content Moderation at Etsy
Etsy writes about its machine learning-based content moderation system, which leverages supervised learning to detect policy violations on its platform. The system utilizes multimodal signals from text and images to train models predicting whether listings violate Etsy’s policies. The architecture includes BERT-based text encoders and EfficientNet image encoders, with a final softmax layer for classification.

https://www.etsy.com/codeascraft/machine-learning-in-content-moderation-at-etsy
Uber: Sparkle - Standardizing Modular ETL at Uber
The industry is also moving towards writing ETL jobs similarly to any other software development practice, with features such as modular ETL, test-driven development, data quality checks, observability, version control, etc

I can’t agree with this enough. The need to adopt software development practices in the ETL process is much higher, as the success of AI-driven applications depends on data quality. The tooling in this area is still not well developed and has a long way to go. Uber writes about Sparkle, a modular ETL framework that brings the best software engineering practices into the ETL process.
https://www.uber.com/blog/sparkle-modular-etl/
DoorDash: DoorDash Empowers Engineers with Kafka Self-Serve
Every infrastructure will require automation and standardization to accelerate the adoption after reaching a critical mass. DoorDash writes about its Kafka Self-Serve platform, which enables engineers to manage Kafka resources, such as topics and user access, with minimal reliance on infrastructure teams. It simplifies configurations, enforces best practices, and offers a user-friendly interface via its internal DevConsole.
https://doordash.engineering/2024/08/13/doordash-engineers-with-kafka-self-serve/
Jack Vanlightly: Table format comparisons - How do the table formats represent the canonical set of files?
This is another insightful blog from the author on the LakeHouse format. It compares how the table formats represent the canonical set of files. The approach essentially falls into two categories.
The log of deltas approach (Hudi and Delta Lake)
The log of snapshots approach (Iceberg and Paimon)
The key highlights are,
Delta Lake periodically writes a checkpoint to the log, which rolls up all deltas to make a snapshot as a Parquet file.
Hudi maintains the current snapshot in the metadata table.
Iceberg and Paimon use a log of snapshots but register the changes made in each snapshot.
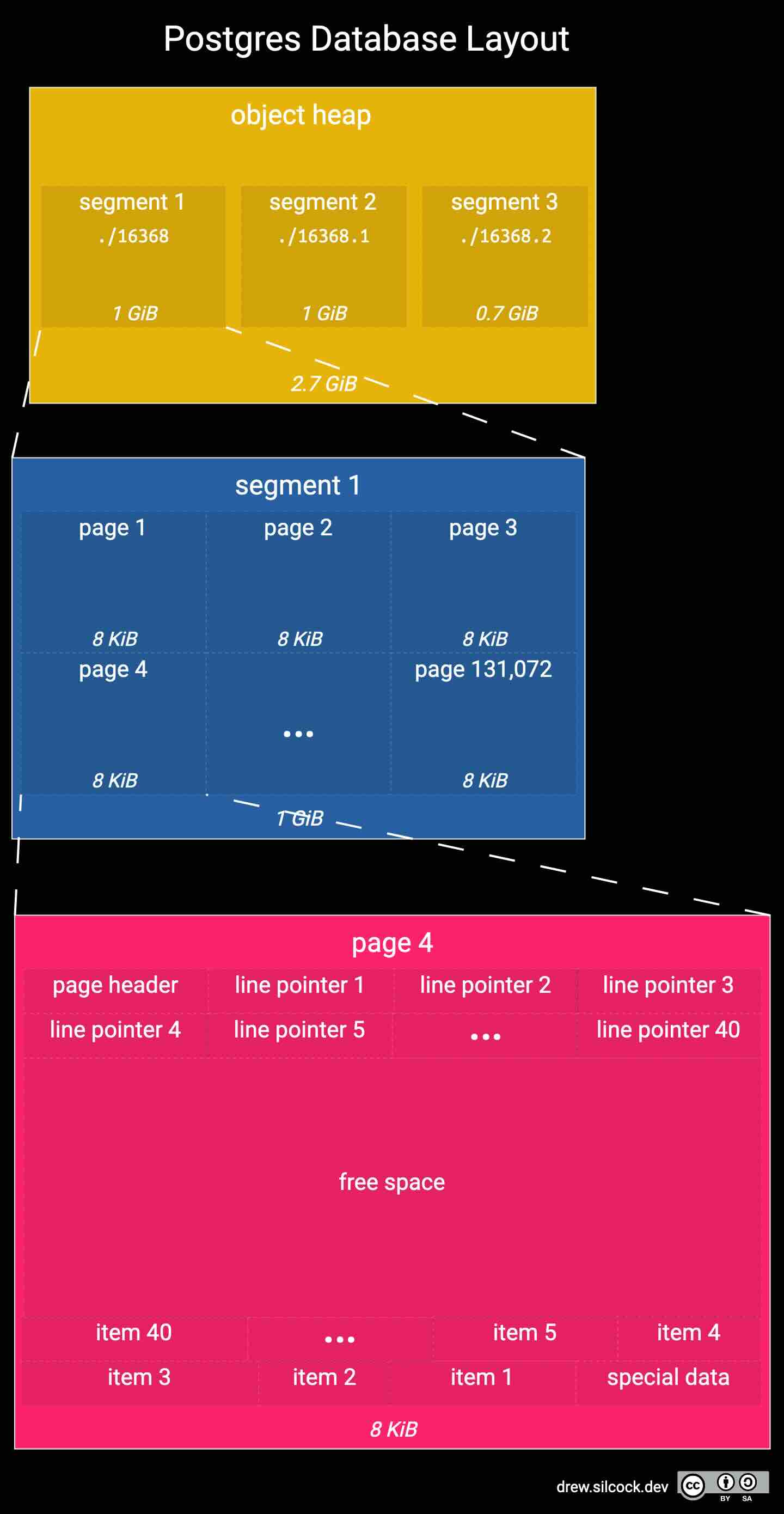
Drew: How Postgres stores data on disk – this one's a page-turner
In the spirit of learning how the LakeHouse systems represent canonical files, the blog about how Postgres stores data gives me an excellent comparison read.
https://drew.silcock.dev/blog/how-postgres-stores-data-on-disk/
Flipkart: Iceberg vs Hudi — Benchmarking TableFormats
Staying on LakeHouse formats, Flipkart writes about benchmarking results on Iceberg and Hudi. It is good to see Flipkart publish the configurations and benchmarking results.
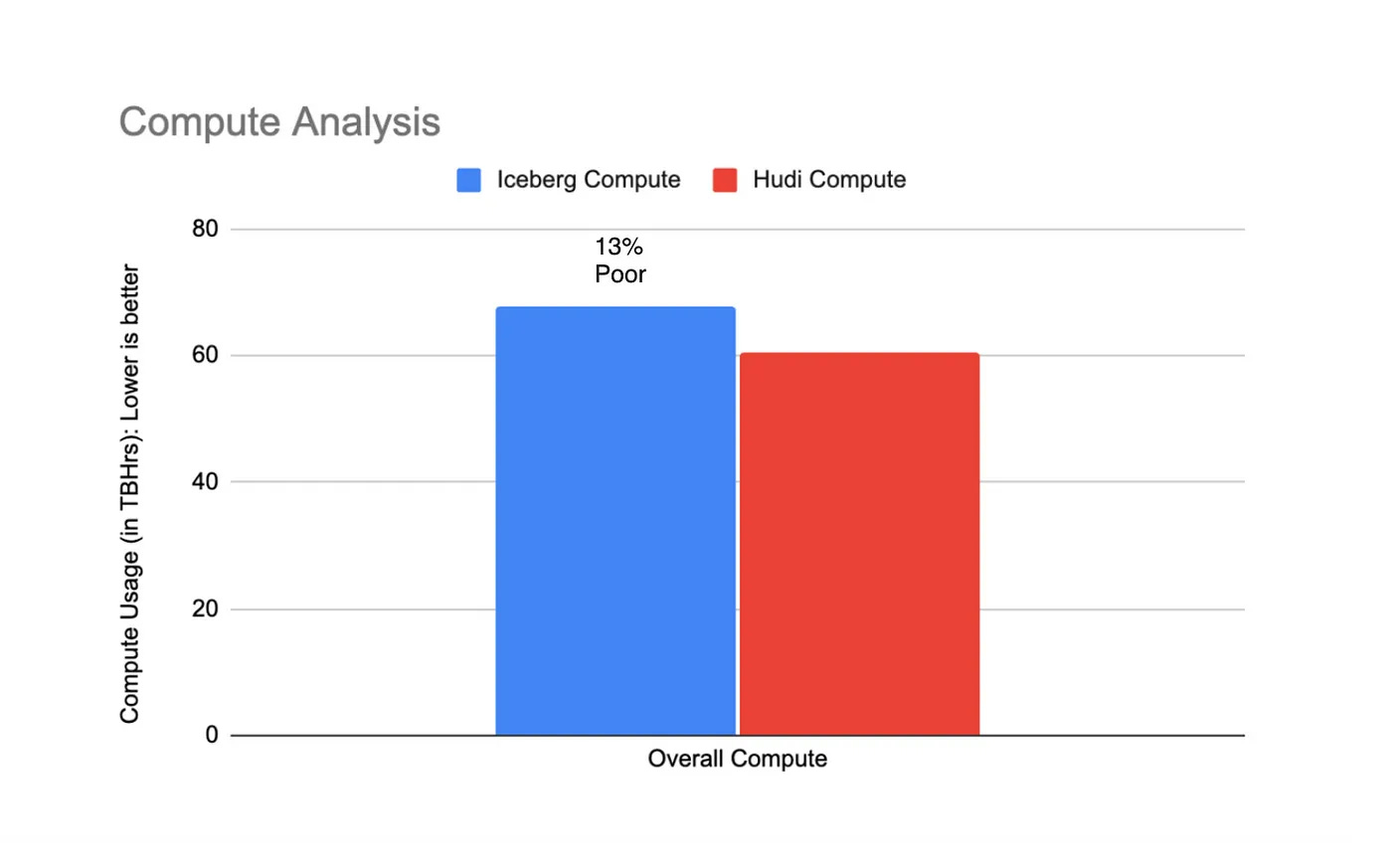
Flipkart concludes that Iceberg performs better on load profiles and upserts, whereas Hudi performs better in query performance, especially at larger data sizes.
https://blog.flipkart.tech/iceberg-vs-hudi-benchmarking-tableformats-dffe6f81f26e
Yelp: dbt Generic Tests in Sessions Validation at Yelp
Yelp writes about extending dbt’s generic test framework by demonstrating the importance of building a standard set of quality checks for their user session data mart. The approach certainly triggered my thoughts on the possibility of building a standard set of domain-specific quality tests in finance, marketing, and so on.
https://engineeringblog.yelp.com/2024/08/dbt-Generic-Tests-in-Sessions-Validation-at-Yelp.html
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.