
Data Engineering Weekly #186
The Weekly Data Engineering Newsletter


Try Fully Managed Apache Airflow for FREE
Run Airflow without the hassle and management complexity. Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. For a limited time, new sign-ups will receive a complimentary Airflow Fundamentals Certification exam (normally $150).
Conference Alert: Data Engineering for AI/ML
This is a virtual conference at the intersection of Data and AI. It is not a conference for the hype. It’s real users talking about real experiences.
You will not hear the words AGI. Instead, you will see engineers, product managers, and founders talking about the data engineering practices of AI/ML. It will be fun and educational.
- 40+ speakers
- 12th September 2024
- Three simultaneous virtual tracks
- Panels, Workshops, Lighting Talks, Keynotes, Fireside Chats and Entertainment.
https://home.mlops.community/public/events/dataengforai
Mario Fischer: How Google Search ranking works
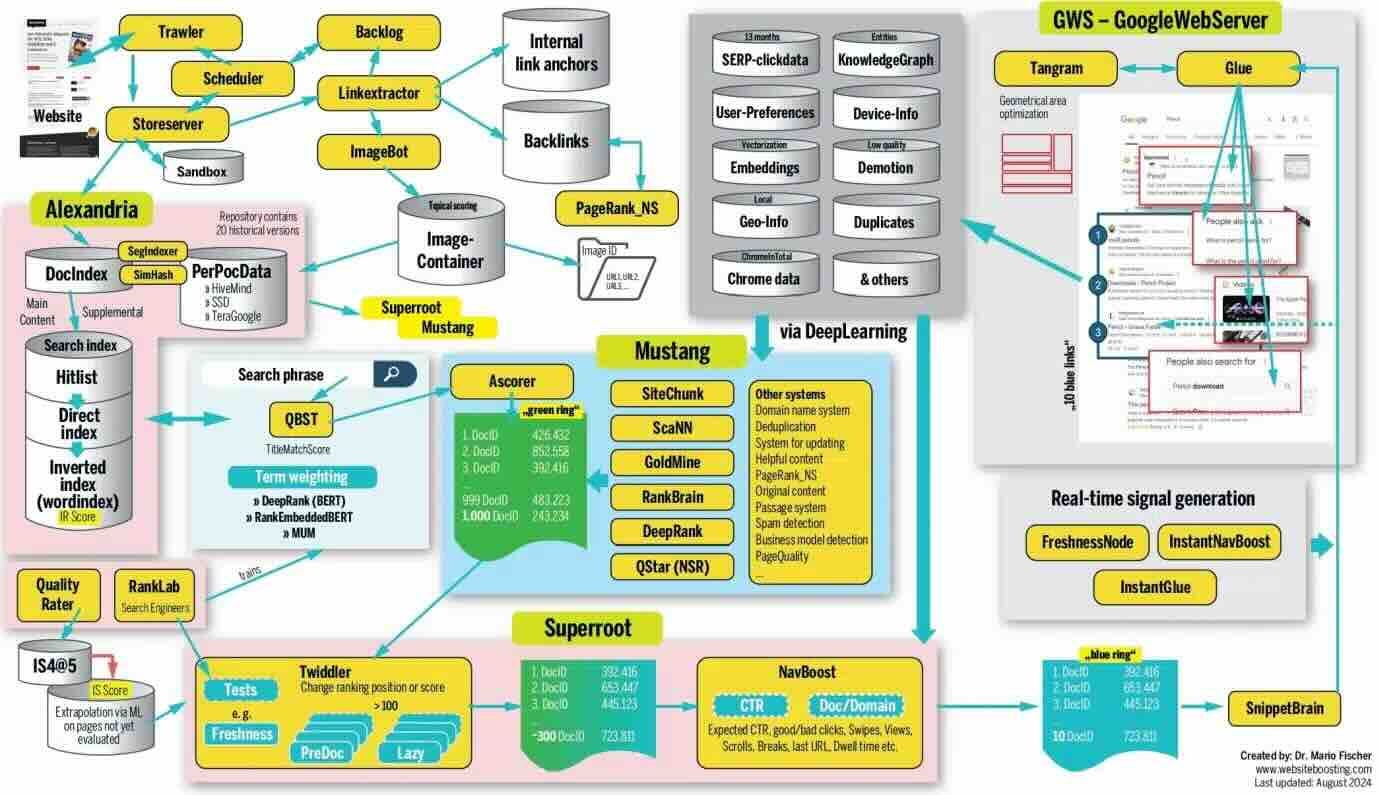
One of the educational reads for me this week is about how Google search ranking works. The author summarizes the learning from the Google Search Engine paper leak and various public hearing documents from antitrust cases. Google’s search ranking system is a complex, multi-step process that begins with indexing new content, assigning it a unique DocID, and calculating its relevance based on keyword presence. It then passes through various ranking systems like Mustang, Superroot, and NavBoost, which refine the results to the top 10 based on factors like content quality, user behavior, and link analysis.
https://searchengineland.com/how-google-search-ranking-works-445141
FourSquare: Modern Data Platform: An Unbundling of a Traditional Data Warehouse

When building their data platform, companies face a critical decision: adopt an all-in-one solution from vendors like Databricks, Snowflake, or AWS or compose a custom platform using tools from different providers. The blog is a good overview of various components in a typical data stack.
I think an all-in-one solution or best-of-breed will be a big decision in the industry in the coming years. The Data Engineering Weekly is trying to address this issue with our buyer’s guide, starting with CDC.
RazorPay: Structuring the Analytics Team: Distributed vs. Centralized Approaches
Structuring the analytical organization to align with the business goal is always challenging. Several companies have written about centralized vs. decentralized organization structures, and RazorPay has made solid recommendations on approaching the problem.

Sponsored: Guide to Data Orchestration for Generative AI
When it comes to success with Generative AI, it’s all about the data — specifically, your data. Powerful deep learning models are becoming smarter, more accessible and cost-effective. However, it’s only by combining these with rich proprietary datasets and operational data streams that organizations can find true differentiation. This guide discusses the criticality of orchestrated data pipelines for the most common use cases in Generative AI and covers how to build differentiated, resilient, and governed AI applications.
Marc Olson: Continuous reinvention: A brief history of block storage at AWS.
Since its introduction, EBS has come a long way, and we prefer EBS over instance stores in many use cases. The author narrates a fascinating perspective on the journey of EBS, queueing theory with an amazing analogy, and the importance of comprehensive instrumentation in improving the systems. This is a must-read for this week.
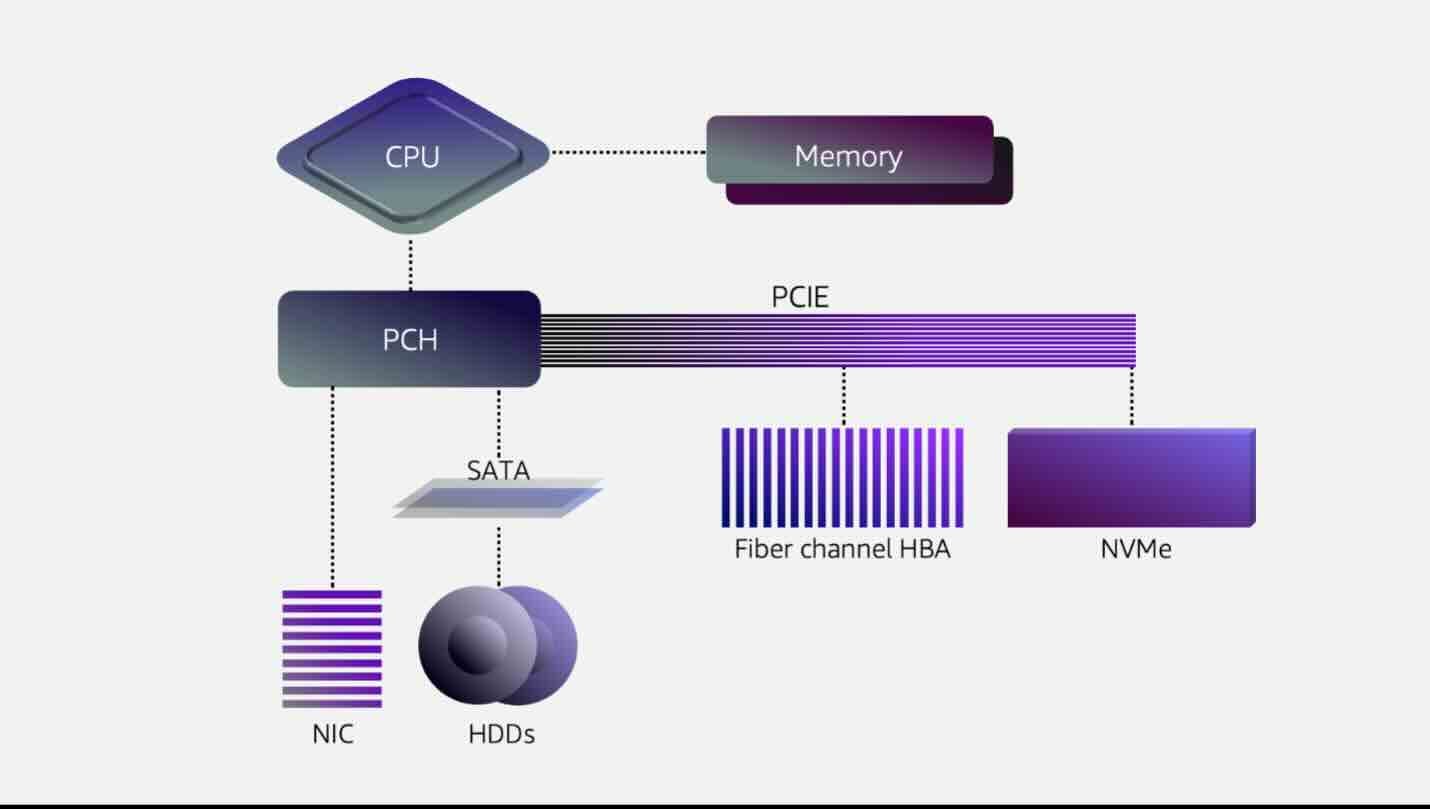
Murat: Understanding the Performance Implications of Storage-Disaggregated Databases
The separation of storage and computing certainly brings a lot of flexibility in operating data stores. We witnessed the uprising of serverless/S3-dependent message queues and Postgres engines. The author writes an overview of the performance implication of disaggregated systems compared to traditional monolithic databases.
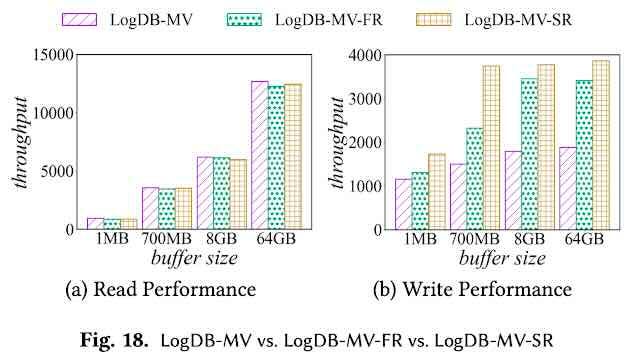
https://muratbuffalo.blogspot.com/2024/07/understanding-performance-implications.html
Colin Break: Predicting the Future of Distributed Systems
Many systems—everything from relational databases, time-series databases, message queues, data warehouses, and services for application metrics—use object storage as a core part of their architecture.
I often wonder if we are building a pyramid infrastructure scheme on top of the object storage. The author gave a different perspective with the one-way-door vs. two-way-door analogy, stating that object storage has been around for 20+ years now. The prediction around the innovation of the programming model is an interesting read.
https://blog.colinbreck.com/predicting-the-future-of-distributed-systems/
Max Meldrum: Introducing datafusion-uwheel, A Native DataFusion Optimizer for Time-based Analytics
µWheel is an event-driven aggregate management system for ingesting, indexing, and querying stream aggregates. The author writes about integrating uwheel with DataFusion (a query engine for building high-quality data-centric systems in Rust, using the Apache Arrow in-memory format). The temporal aggregation and pruning using custom indices, which drastically reduce query execution times, is exciting, and I look forward to trying this out soon.
https://uwheel.rs/post/datafusion/
https://uwheel.rs/post/datafusion_uwheel/
Lyft: Protocol Buffer Design - Principles and Practices for Collaborative Development
The blog discusses the key design principles and best practices for collaborative development using protobuf. More than that, I included this blog to remind you of the importance of event governance and a structured eventing approach, which is critical for an organization to build a strong data foundation.
Treat Events as a first-class citizen, and remember that it is always the upstream that causes the failure.
Airbnb: Personal Data Classification
Airbnb writes about the criticality of data classification and the impact on user trust if we fail to do so. The blog narrates the shift-left approach in data governance with three critical principles.
Shift data classification from data to schema
Shift classification from offline to online
Shift from Data Steward to Data Owner

https://medium.com/airbnb-engineering/personal-data-classification-2d816d8ea516
Vu Trinh: I spent 8 hours learning Parquet. Here’s what I discovered
Apache Parquet becomes the defacto columnar storage for LakeHouse formats, and it is a must for data engineers to know its internals. The author did an amazing job of describing how Parquet stores the data and compression and metadata strategies.
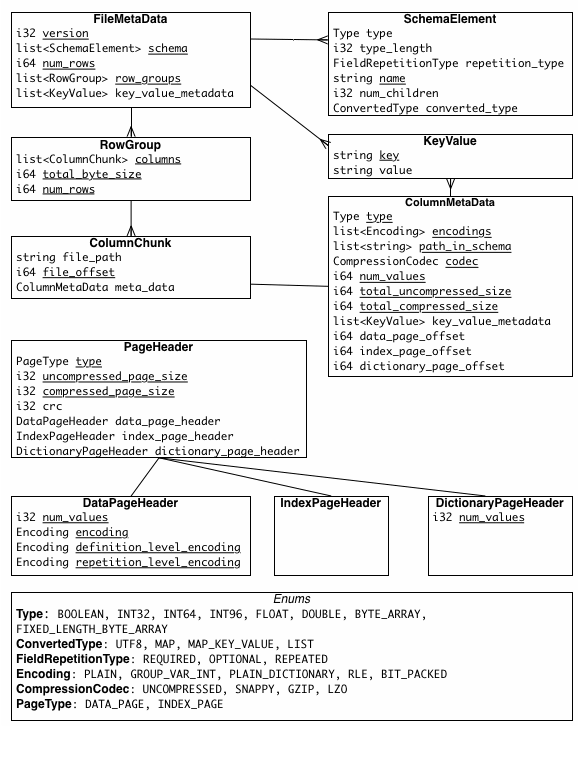
https://medium.com/@vutrinh274/i-spent-8-hours-learning-parquet-heres-what-i-discovered-97add13fb28f
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.
Wow, it's such an honor. Thank you for featuring my Parquet article.