
Data Engineering Weekly #187
The Weekly Data Engineering Newsletter


Try Fully Managed Apache Airflow for FREE
Run Airflow without the hassle and management complexity. Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. For a limited time, new sign-ups will receive a complimentary Airflow Fundamentals Certification exam (normally $150).
Conference Alert: Data Engineering for AI/ML
This is a virtual conference at the intersection of Data and AI. It is not a conference for the hype. It’s real users talking about real experiences.
You will not hear the words AGI. Instead, you will see engineers, product managers, and founders talking about the data engineering practices of AI/ML. It will be fun and educational.
- 40+ speakers
- 12th September 2024
- Three simultaneous virtual tracks
- Panels, Workshops, Lighting Talks, Keynotes, Fireside Chats and Entertainment.
https://home.mlops.community/public/events/dataengforai
Spotify: Unlocking Insights with High-Quality Dashboards at Scale

There is no shortage of criticism of dashboards. :-) Dashboards are not going anywhere. Dashboards create a shared sense of reality and a standardized interpretation of the associated data. Spotify writes an excellent overview of its dashboard standardization process, including when to use Tableau over Looker and the internal search portal to find the dashboards.
https://engineering.atspotify.com/2024/08/unlocking-insights-with-high-quality-dashboards-at-scale/
Foundation Capital: Goodbye AIOps - welcome AgentSREs—the next $100B opportunity
Many companies are trying to build smarter AI Engineers, but I do think there is more repeatable and manual work that we do that can be potentially automated. In a way, augmenting engineers is more appealing than creating a clone. The blog provides an excellent narrative and opportunity in the SRE space, which is true for data ops, too.
https://foundationcapital.com/goodbye-aiops-welcome-agentsres-the-next-100b-opportunity/
Uber: Pinot for Low-Latency Offline Table Analytics
Uber writes about the offline table creation process with Apache Pinot. The blog narrates the offline data modeling support and integration with frameworks like Apache Spark.
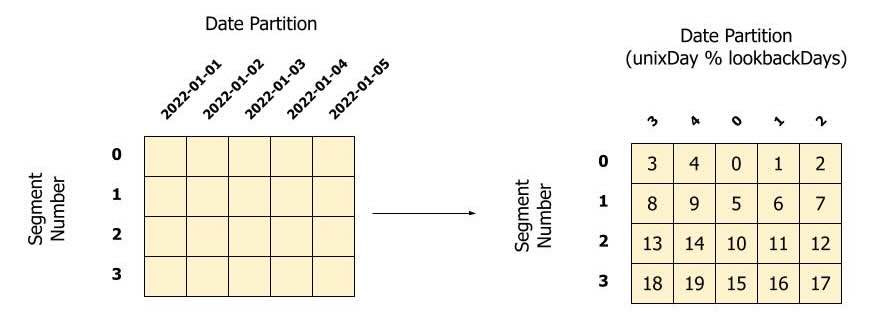
One of Apache Pinot's highlights is creating a Pinot index offline and simply uploading it via calling /segment API. The design plays a major role when we reindex/ backfill the production clusters.
https://www.uber.com/blog/pinot-for-low-latency/
Sponsored: Data Pipelines with Apache Airflow

If you're looking to build, maintain, and more efficiently manage your data pipelines, check out our comprehensive guide, Data Pipelines with Apache Airflow. This ebook covers practical use cases, and provides an overview of key concepts and best practices, including how to set up Airflow in production environments, along with best practices for building, testing, and deploying Airflow DAGs.
Chris Riccomini: Unpacking the Buzz around ClickHouse
The simplicity of ClickHouse with one click install and the developer experience stands out among the other OLAP engines. The author evaluates ClickHouse's advantages, challenges in the design, and the ongoing innovations on top of Postgres to become the OLAP system.
We often think of OLAP as a storage engine for immutable events but fail to notice the mutable dimensions required to produce an analytical view. While evaluating the OLAP engines, I encountered one challenge with ClickHouse: its inefficiency in handling upsert operations. I don’t know the current state, so please point out any articles that discuss ClickHouse upsert ops.
https://materializedview.io/p/unpacking-the-buzz-around-clickhouse
Jack Vanlightly: Table format comparisons - Streaming ingest of row-level operations
In this post, I’ll focus on merge-on-read as copy-on-write is just a bad idea for any streaming ingest workload. 🎯
This is an excellent blog comparing the streaming ingest of row-level operation comparison among the LakeHouse formats. We can broadly classify the support into two categories.
Native primary key support - LSM-like design - [Hudi, Paimon)
No native primary key support - offload the row-level ops to the compute engines (Iceberg, Delta)
Sponsored: Save the Date for IMPACT - The Data Observability Summit on November 14th!
This one-day event will feature the world’s top data leaders, architects, and practitioners coming together to discuss best practices and strategies for designing, building, and scaling trusted data and AI systems that drive real growth and business value.

Trust me, you don't want to miss it. Register here:
Nguyễn Mạnh: How we migrated the current batch-processing log pipeline to a near-real-time streaming system
Classi discusses adopting an event-driven ingestion pipeline design connecting AWS and Google Cloud. I see a pattern where the data warehouse is in Google BigQuery, and the core infrastructure is in AWS. Is it a failure in Redshift? Could it be a time for AWS to consider buying Snowflake?
Gunnar Morling: Leader Election With S3 Conditional Writes
S3 support for conditional writing certainly sparks a lot of excitement. In a nutshell, the S3 PutObject operation now supports an optional If-None-Match header. When specified, the call will only succeed when no file with the same key exists in the target bucket; otherwise, you’ll get a 412 Precondition Failed response. The blog narrates how one could build a leader election with S3; otherwise, it requires specialized infrastructure like Zookeeper.
https://www.morling.dev/blog/leader-election-with-s3-conditional-writes/
Netflix: Recommending for Long-Term Member Satisfaction at Netflix
Netflix writes about the reward function in a recommendation engine that focuses on long-term member satisfaction out of implicit feedback like click or skip. It is an insightful read emphasizing the reward function aligned with the business objective.
https://netflixtechblog.com/recommending-for-long-term-member-satisfaction-at-netflix-ac15cada49ef
DoorDash: How DoorDash is pushing experimentation boundaries with interleaving designs
Interleaving design involves alternating between two options within the same user experience to observe and compare user reactions in real time. This method ensures a fair and immediate comparison by minimizing external factors and focusing on how users respond to each option as they encounter it.

DoorDash writes about how it adopted interleaving designs and its advancement in the sensitivity gain of experimentation.
https://doordash.engineering/2024/08/27/doordash-experimentation-with-interleaving-designs/
Instacart: Using Surrogate Indices to Estimate Long-Run Heterogeneous Treatment Effects of Membership Incentives
Every business has this at the top of its mind: What kinds of potential users should we give an incentive to, and for how much? Instacart writes about measuring the customers' iLTV (Incremental Lifetime Value) after applying incentives. These articles about surrogate indexes, contextual bandits, etc., have provided many follow-up reads for me.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.