
Data Engineering Weekly #189
The Weekly Data Engineering Newsletter

Uber: DataMesh - How Uber laid the foundations for the Data Lake Cloud migration

Many companies are slowly adopting DataMesh, and Uber writes about adopting the data mesh principle. Whether or not Data Mesh is a separate product is debatable, but it is certainly an impactful framework for scaling data platforms. I expect more and more frameworks to be built on top of the existing compute and orchestration layer.
https://www.uber.com/blog/datamesh/
Miro: Data Products Reliability - The Power of Metadata
Miro writes about its adoption of Data Contracts. The approach talks about moving the data contract coded approach from Airflow code to DataHub yaml specification to provide more visibility to the stakeholders. Miro and Uber case studies emphasize framework simplification and the need for simplified tooling around the data mesh concept to scale a data platform.
https://miro.com/careers/life-at-miro/tech/data-products-reliability-the-power-of-metadata/
dbt: The Analytics Development Lifecycle (ADLC)
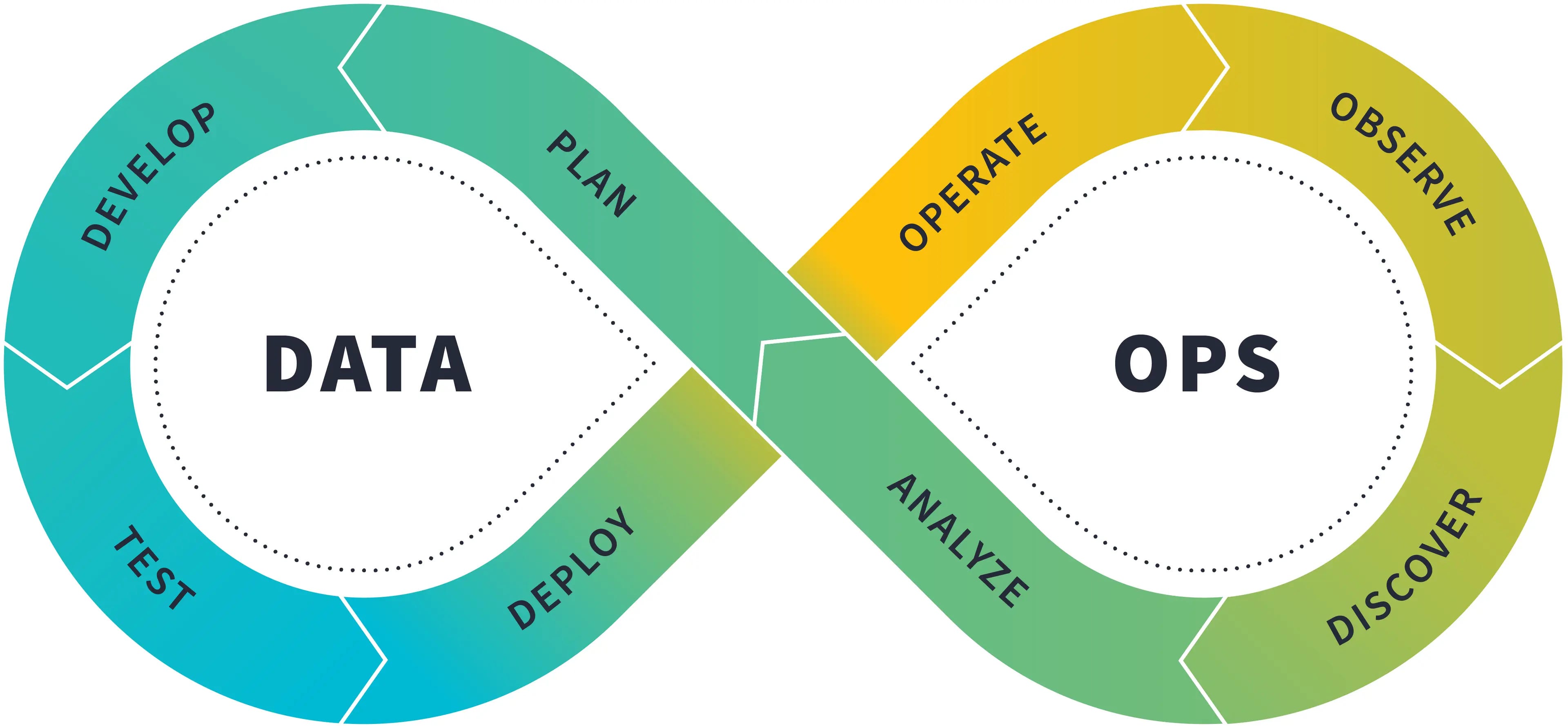
dbt publishes a whitepaper about the Analytical Development Lifecycle aligning with the software development lifecycle. It is a good summarization of various phases of the data asset creation. The whitepaper does not discuss the implementation of this lifecycle; it would be nice to have a follow-up with implementation references similar to AWS's well-architected framework.
https://www.getdbt.com/resources/guides/the-analytics-development-lifecycle
Sponsored: IMPACT - Speaker Promo
We know high-quality data is powerful. But can it predict presidential elections?

At IMPACT 2024, we’re thrilled to host Allan Lichtman, American historian and the mastermind behind the Keys to the White House, a model that has successfully predicted U.S. presidential winners for decades, as our keynote speaker!
During his keynote, he’ll share his insights into how data and pattern recognition shape the world, build trust, and—sometimes—even help us predict the future.
Ravi Vedula: The evolution of a data platform - The story of the Microsoft IDEAS team
Microsoft IDEAS (Insights, Data, Engineering, Analytics, Systems) team writes about the evolution of the data platform. The blog narrates how the lack of neutral guidance or standards leads to ambiguity and the formation of a central team to bring trust in data. I hope to see more in-depth technical articles about the DataCop and Nitro orchestration engine.
Airbnb: Riverbed Data Hydration
Airbnb Engineering's Riverbed project addresses the challenges of optimizing real-time data access in hybrid cloud environments by implementing a "data hydration" layer. This approach efficiently fetches and caches data for services, reducing latency and cloud costs. The article explains how data hydration can balance performance and cost in modern data platforms.
https://medium.com/airbnb-engineering/riverbed-data-hydration-part-1-e7011d62d946
Instacart: Optimizing search relevance at Instacart using hybrid retrieval
Instacart optimizes search relevance by combining traditional keyword-based and vector searches in a hybrid retrieval system. This approach improves search results by balancing precision and coverage for customer queries. The article provides a great overview of how Instacart enhances the shopping experience through search relevance. The growing adoption of pgvector is exciting as it greatly simplifies the overall architecture complexity.

Vinted: Vinted Search Scaling Chapter 8 - Goodbye Elasticsearch, Hello Vespa Search Engine
The widespread adoption of vector search increases the migration from Elasticsearch to a more simplified design. Like Instacart, Vinted writes about its adoption story of hybrid search with Vespa. I suppose the migration triggers Elasticsearch Open Source again?

The article talks about the migration challenges and the hybrid search testing strategies.
https://vinted.engineering/2024/09/05/goodbye-elasticsearch-hello-vespa/
GreyBeam: A Deep Dive into Snowflake's Query Cost Attribution: Finding Cost per Query
Having a proprietary query engine that charges the users by query execution time with no visibility on how optimal the technology is a suboptimal solution. I’m happy that Snowflake provides visibility to per-query execution cost with the query_attribution_history model. Is it sufficient? The article walkthrough is insufficient and provides a framework to measure the cost more accurately. Kudos to the GreyBeam team for posting the full SQL to measure the cost.
https://blog.greybeam.ai/a-deep-dive-into-snowflakes-query-cost-attribution-finding-cost-per-query/
Simon Eskildsen: Napkin Math
Napkin Math is a collection of mental models and calculations designed for software engineers to estimate system behaviors without needing detailed measurements. It covers latency, throughput, and scaling, helping engineers make informed decisions quickly.
Napkin Math is a valuable resource for data platform engineers because it equips them with quick, intuitive calculations for estimating system performance and resource requirements. This can be crucial when making decisions about scaling data pipelines, optimizing query performance, or estimating the cost of infrastructure changes without detailed simulations.
https://github.com/sirupsen/napkin-math
Svetak Sundhar: Unit Testing in Beam - An Opinionated Guide
The blog talks about the Apache Beam pipeline's engineering approach to unit testing. Though the blog talks specifically to Beam, every pipeline can adopt the theme.
Don’t spend more time on framework integration since they are mostly well-tested already.
Separate the business logic from the pipeline code to be well-tested outside the pipeline.
Run the entire pipeline with a sample dataset to verify the chain of tasks executed as expected.
https://beam.incubator.apache.org/blog/unit-testing-in-beam/
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.