
Data Engineering Weekly #192
The Weekly Data Engineering Newsletter

PyTorch: PyTorch Conference 2024 Recap - On Fire 🔥
PyTorch plays a significant role in the latest development of AI in the industry. The article nicely summarizes the key takeaways from the conference. All the talks are now available on YouTube. If you are new to PyTorch and want to learn, the tutorial from freecodecamp is the best.
https://pytorch.org/blog/pytorch-conference-2024-recap/
Medium: Learnings from optimising 22 of our most expensive Snowflake pipelines
A blog about real-world learning is always a delight to read. The author narrates the learning from optimizing the most expensive Snowflake pipelines. The learning goes back to the fundamentals of pipeline design principles.

Regularly review if pipelines are still required.
Minimize the data used in pipelines, aka do incremental data pipeline design.
Optimize pipeline schedules. Ask if it should run hourly? can it be daily or weekly?
Filter data effectively to make sure the query uses partition pruning.
Use time windows for analysis. Don’t query two years of data.
Rachel Foong: Customer + Business metrics matrix for Digital Product Managers
The author discusses evaluating a product's performance from a digital product manager’s perspective. The matrix goes beyond traditional customer-focused metrics and incorporates business costs and benefits to help product managers make well-rounded decisions. It updates the popular Pirate metrics (AARRR) framework by adding concepts like Attention and Adoption. It emphasizes balancing customer impact with business objectives such as ROI, brand value, and operational costs.
Sponsored: Monte Carlo Demo - October

You want to deliver reliable business insights to your organization, but that probably means you’re spending a whole lotta time writing a whole lotta of rules.
Data quality rules, that is.
But, what if you could automate them instead – and spend more time delivering value for your stakeholders?
Join us on October 10th at 9am PT | 12pm ET as I walk through how data observability platforms like Monte Carlo can help data analytics teams reduce time spent on data quality by 80% or more.
Uber: Making Uber’s ExperimentEvaluation Engine 100x Faster

Uber writes about redesigning its Experimentation platform to reduce the latency of experiment evaluations by 100x. The new architecture moved from a remote evaluation model, where clients made requests to a central service, to a local evaluation model, where clients compute evaluations locally. The authors discuss the challenges and learnings in implementing this change, including ensuring correctness at scale, addressing log volume concerns, and managing decentralized evaluations.
https://www.uber.com/blog/making-ubers-experiment-evaluation-engine-100x-faster/
Grab: Evolution of Catwalk - Model serving platform at Grab
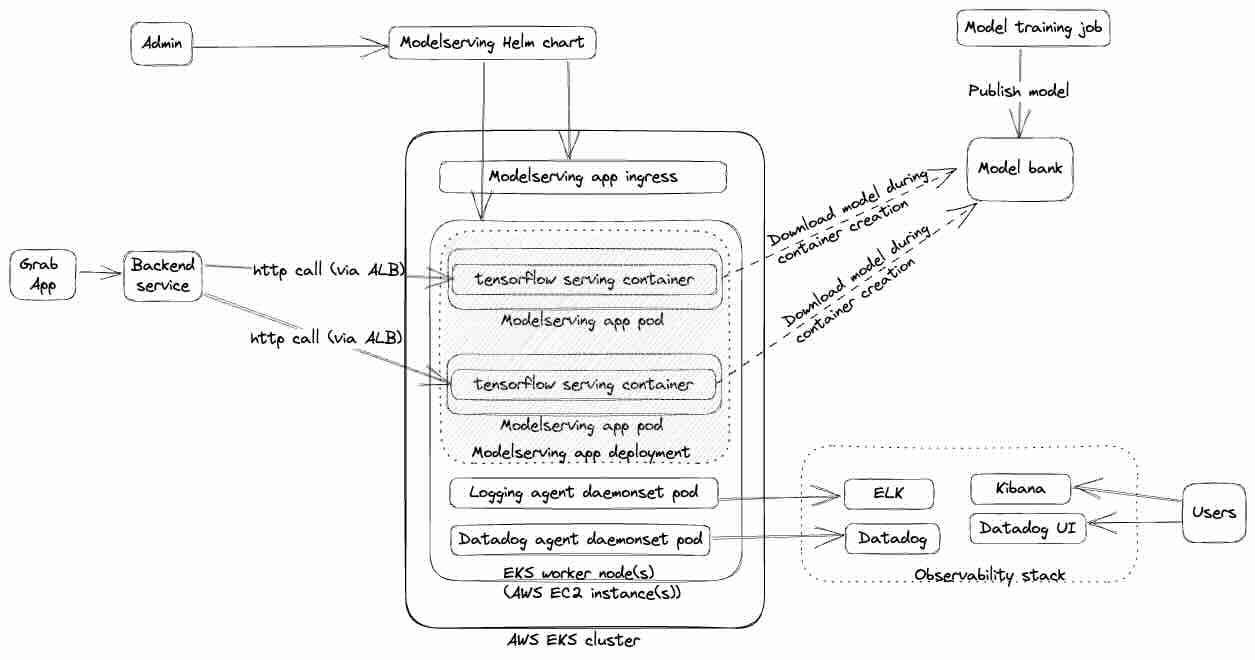
Grab writes about the evolution of its model-serving platform, Catwalk. The article describes four distinct phases of Catwalk's development, highlighting the challenges faced and solutions implemented at each stage.
Phase 0 outlines the need for a dedicated platform due to the inefficiencies of ad-hoc approaches.
Phase 1 introduced a managed platform for TensorFlow Serving models but faced scalability limitations.
Phase 2 transitioned to a self-serving approach, empowering data scientists with greater control over their models.
Phase 3 replaced Helm charts with Kubernetes CRDs for enhanced deployment control and flexibility.
Phase 4 introduced the Catwalk Orchestrator, a high-code orchestration framework that enables users to write custom business logic.
https://engineering.grab.com/catwalk-evolution
LinkedIn: Leveraging Dwell Time to Improve Member Experiences on the LinkedIn Feed
LinkedIn writes about how the company has improved its Feed ranking system by using dwell time, or the amount of time a user spends on a piece of content, as a signal of user interest. The authors describe how they have tackled technical challenges such as noisy dwell time signals, the need for an adaptive threshold, and introducing biases through static thresholds to develop an innovative model that predicts "long dwell" behavior.
Andy Sawyer: 4 Key Benefits of Shift Left
Prevention is better than cure. The author highlights the key benefits of thinking and designing systems to support quality and compliance upfront (shift-left) rather than later. The key benefits are
Improved data quality,
Enhanced data governance
Increased security
Cost efficiency
https://medium.com/@nydas/4-key-benefits-of-shift-left-ff0e4bb74a3f
HomeToGo: How HomeToGo improved our Superset Monitoring Framework

Apache Superset is the most popular open-source BI tool in the industry. The goal of the monitoring framework is to treat every dashboard as a data product, and by ingesting the Superset’s metadata into the Data Warehouse, the HomeToGo data team is trying to lifecycle management and governance more automatedly. Though the blog talks about Superset, every team should strive to adopt a similar framework to manage the lifecycle of their dashboards.
Ravi Vedula: Leveraging AI for next-level data productivity in IDEAS

In the new era of LLM, data engineers strive to improve our interaction with the vast data storage in the data warehouse. “text-to-SQL” and “text-to-insight.” are the dreams we started to chase after, and I’m sure we are not far away from the dream. Microsoft IDEAS team writes about one such system design and the challenges to overcome.
Rachana Aluri: Text-to-SQL’s Power Players: Comparing Claude 3.5 Sonnet, GPT-4o, Mistral Large 2, Llama 3.1

The blog provides an excellent comparison of text-to-SQL conversion accuracy, speed, and cost. While GPT-4o and Claude 3.5 Sonnet consistently lead in handling complex queries with high accuracy, emerging models like Mistral Large V2 and the Llama family show promise in certain areas.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.