
Data Engineering Weekly #194
The Weekly Data Engineering Newsletter

Notion: A brief history of Notion’s data catalog

Notion writes about its journey in adopting data catalogs and describes how a vanilla data catalog solution will only be effective if it adopts a strong data platform foundation. Adopting Typescript rather than the specialized IDL languages is a good strategy, although I wonder how it works in cross-language systems like Android & iOS. I presume the typescript-to-js conversion helps here.
https://www.notion.so/blog/a-brief-history-of-notions-data-catalog
Zach Wilson: How GenAI will impact data engineering
An excellent overview of the potential impact of GenAI in data engineering workflow that can change the pipeline authoring, shipping pipeline, and maintaining the pipeline. Suppose you think of data pipeline building as a manufacturing process that goes from sourcing the raw material to delivering a finished (data) product. There are tons of optimizations we can do to improve the efficiency. The problem statement is something I’m excited about, and I write about it here as something I’m working on.
https://blog.dataengineer.io/p/how-genai-will-impact-data-engineering
Uber: Open Source and In-House - How Uber Optimizes LLM Training

Uber’s latest blog post dives into how the company trains large language models (LLMs) by blending open-source models with domain-specific expertise. Uber leverages open-source tools and infrastructure to streamline the training process while fine-tuning and optimizing the models with in-house techniques. Uber’s post outlines its infrastructure stack and training pipeline, emphasizing the balance of open-source and custom solutions to drive generative AI advancements.
https://www.uber.com/blog/open-source-and-in-house-how-uber-optimizes-llm-training/
Sponsored: IMPACT Summit

If you haven't registered for the IMPACT Summit yet, now's the perfect time 🔈
Here’s what we’ve got in store:
- A half-day virtual event created to elevate your 2025 data strategy
- Sessions jam-packed with industry experts sharing how they're driving data and AI adoption
- Practical tips and best practices from Monte Carlo customers
- Opportunities to connect and network with other data professionals
- Giveaways and raffles for attendees, including three All-Access subscriptions to DataExpert.io!
- And more!
What are you waiting for? Register for IMPACT today!
Apurva Mehta: Stop embedding RocksDB in your Stream Processor!
The most important reason streaming is difficult is to embed the state (RocksDB) in the stream processor. The blog narrates the drawbacks, including increased downtime due to state rebuilds, inflexibility in scaling compute and storage resources, limited visibility into the state, and a lack of advanced functionality like time-to-live (TTL) management and easy state inspection and patching.
Life is too short to scale storage and computing together, and this space requires a fundamental rethinking.
https://www.responsive.dev/blog/stop-embedding-rocksdb-in-kafka-streams
Pinterest: Ray Batch Inference at Pinterest
The search quality team at Pinterest saw over a 30x decrease in annual cost for one of their inference jobs after migrating it from Spark(™) to Ray(™).

There is an increased desire to find a computing engine that is less costly but robust than Apache Spark. Pinterest's three-part series about Ray batch inference is an exciting read about running batch jobs in Ray.
https://medium.com/pinterest-engineering/last-mile-data-processing-with-ray-629affbf34ff
https://medium.com/pinterest-engineering/ray-infrastructure-at-pinterest-0248efe4fd52
https://medium.com/pinterest-engineering/ray-batch-inference-at-pinterest-part-3-4faeb652e385
Confluent: Shift Left: Bad Data in Event Streams

Confluent writes about the challenges of handling bad data in event streams, specifically focusing on the differences in dealing with bad data in batch processing compared to event streaming. State events, which represent the entire state of an entity, are much easier to correct as they can be compacted, allowing for the deletion of older versions and the propagation of updated data. Delta events, which describe changes or actions, are significantly harder to fix due to their immutable nature.
The blog concludes with a final strategy, "rewind, rebuild, and retry," highlighting the importance of preventative measures like schemas, data quality checks, and robust testing to avoid such costly interventions.
https://www.confluent.io/blog/shift-left-bad-data-in-event-streams-part-2/
Christophe Oudar: Microbatch on dbt?
The article is an excellent narration of the recent dbt support for microbatch incremental workload. I’m happy about the support coming in dbt, as I worked out a similar incremental batch processing strategy that the author explains here in dbt-core with Airflow. I still remember a veteran data engineer at work telling me how dbt got away with it til now without this feature :-) I’m sure we are not alone here. Many companies would have done something similar, so I’m glad it is finally coming.
https://medium.com/@kayrnt/microbatch-on-dbt-93d600ced394
Barbara Galiza: You don’t have a “data problem”
We marketers sometimes think of data as a boolean: either we have it or don’t. However, data problems come in many shapes and forms.
The blog is an excellent summary of data problems. The author breaks down “data problems” into five distinct categories: measurement, quality, accessibility, literacy, and activation. The author further narrates the symptoms of each and possible remedies.
https://www.021newsletter.com/p/you-dont-have-a-data-problem
Shopify: How Shopify improved consumer search intent with real-time ML
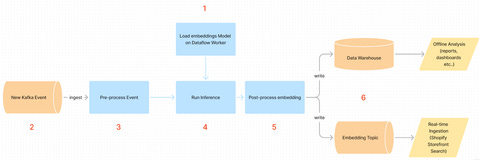
Shopify writes about its real-time pipeline design for building the image embedding engine to improve consumer search experience. The blog describes the trade-off between parallel data processing and memory usage while processing images.
https://shopify.engineering/how-shopify-improved-consumer-search-intent-with-real-time-ml
Netflix: Investigation of a Workbench UI Latency Issue
Internal tools, especially data tools, should address performance and user experience. Netflix writes about how the data platform team investigated the UI latency issue in Jupyter Notebook. What I like most about the blog is not only the investigation but also the authors' explanation of how they use LLM in their debug workflow to understand the issue in more depth.
Moreover, after several rounds of discussion with ChatGPT, we learned more about the architecture and realized that, in theory, the usage of pystan and nest_asyncio should not cause the slowness in handling the UI WebSocket
https://netflixtechblog.com/investigation-of-a-workbench-ui-latency-issue-faa017b4653d
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.