
Data Engineering Weekly #198
The Weekly Data Engineering Newsletter

Editor’s Note: Launching Data & Gen-AI courses in 2025
I can’t believe DEW will reach almost its 200th edition soon. What I started as a fun hobby has become one of the top-rated newsletters in the data engineering industry. All credit goes to the incredible data engineering community, where people are constantly writing and sharing their knowledge with the community. DEW is one of the mediums that curates all the incredible work done by many talented data practitioners across the globe.
We are planning many exciting product lines to trial and launch in 2025. One of the common themes I encounter when I meet data engineering leaders worldwide is their single most common question: How can we upskill? With the high demand, We are actively working on launching Data & Gen-AI in Jan-Feb 2025
Course #1: Practical Generative AI: A Step-by-Step Guide
Course #2: Applying Functional Principles in Data Pipeline
You can pre-signup for the courses here
https://forms.gle/wzQFmgbPPBLUvEPo8
AWS: How Amazon Ads uses Iceberg optimizations to accelerate their Spark workload on Amazon S3

The Amazon Ads team writes about their Iceberg optimization usage, which helps them accelerate the Spark workload. The blog highlights how moving from 6-character base-64 to 20-digit base-2 file distribution brings more distribution in S3 and reduces request failures.
Netflix: Netflix’s Distributed Counter Abstraction

Netflix writes about scalable Distributed Counter abstractions for accurately counting events across its global services with millisecond latency. The system leverages a combination of an event-based storage model in its TimeSeries Abstraction and continuous background aggregation to calculate counts across millions of counters efficiently. The service offers configurable counter types optimized for various use cases with a unified Control Plane configuration.
https://netflixtechblog.com/netflixs-distributed-counter-abstraction-8d0c45eb66b2
Jon Osborn: Best Practices for Using QUERY_TAG in Snowflake
The modern data warehouses are good at running at scale, given the cost is not a constraint. However, cost is indeed a constraint for many; hence, understanding the efficiency of the query engine is more important than ever before. The blog is a good summary of how to use Snowflake QUERY_TAG to measure and monitor query performance.
https://medium.com/snowflake/best-practices-for-using-query-tag-in-snowflake-32bfb8d4efba
Canva: Our journey to Snowflake monitoring mastery

Canva leverages Snowflake extensively across the organization for data warehousing and analytics. Due to the platform's diverse user base and workloads, Canva faced challenges maintaining visibility into Snowflake usage and costs. Canva writes about its custom solution using dbt and metadata capturing to attribute costs, monitor performance, and enable data-driven decision-making, significantly enhancing its Snowflake environment management.
https://www.canva.dev/blog/engineering/our-journey-to-snowflake-monitoring-mastery/
JBarti: Write Manageable Queries With The BigQuery Pipe Syntax
Our quest to simplify SQL is always an adventure. BigQuery's pipe syntax seems exciting to watch, and it is an interesting approach to how it gets adopted. The blog narrates a few examples of Pipe Syntax in comparison with the SQL queries.
Booking: Self-Serve Platform for Scalable ML Recommendations

Booking.com writes about evolving its recommendation service into a scalable, self-serve platform that empowers teams to create personalized user experiences efficiently. The Recommendation Platform (RecP) leverages a structured pipeline approach to standardize the resolution of machine learning challenges, allowing for component reusability across various use cases and enabling customers to define complex recommendation logic.
Grab: Metasense V2 - Enhancing, improving, and productionisation of LLM-powered data governance.

Grab has enhanced its LLM-powered data classification system, Metasense, to improve accuracy and minimize manual workload. By utilizing post-rollout data and implementing prompt engineering techniques, Grab has addressed weaknesses in the previous model, such as identifying PII data in large, mixed datasets. Integrating LangChain and LangSmith frameworks has streamlined prompt optimization and fostered collaboration among data scientists and engineers, resulting in transparent performance metrics and a more efficient solution.
https://engineering.grab.com/metasense-v2
Snir Israeli: Mastering Airflow DAG Standardization with Python’s AST: A Deep Dive into Linting at Scale

Next Insurance writes about its internal tool, DAGLint, which uses Python's Abstract Syntax Tree (AST) to enforce consistent structures and best practices across their Airflow DAGs. By creating custom linting rules tailored to their team's needs, Next Insurance has improved its data workflows' maintainability, scalability, and quality, making it easier for engineers to collaborate and debug issues. The company has also integrated DAGLint into its CI/CD pipelines and created a monitoring dashboard to ensure ongoing compliance with its standards.
Xiangpeng Hao: Parquet pruning in DataFusion
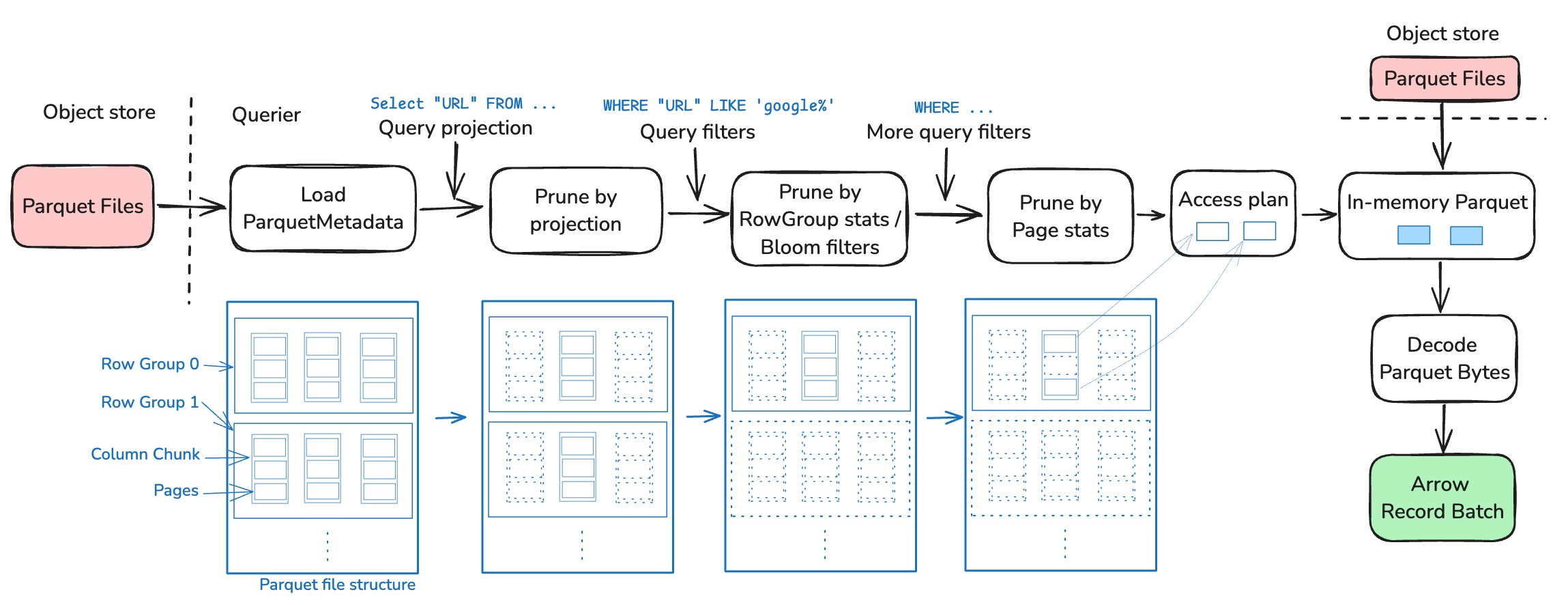
Apache DataFusion recently announced that it is the fastest query engine for querying Apache Parquet format on a single machine. The blog post made me curious to understand DataFusion's internals. The blog made me wonder about the datawarehouse query pattern, which always writes once and reads many; perhaps if we can pre-load parquet metadata into the DuckDB/SQLite table, the reads will be much faster.
I’ve seen a similar work by Ben E. C. Boyter on Bloom Filters and SQLite.
https://blog.haoxp.xyz/posts/parquet-to-arrow/
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.