
Data Engineering Weekly #199
The Weekly Data Engineering Newsletter

Stanford HAI: Global AI Power Rankings: Stanford HAI Tool Ranks 36 Countries in AI

“AI has increased as a topic of national interest for countries across the globe, and correspondingly narratives about which countries lead in AI have become more prominent than ever”
In the next few years, we will see countries actively trying to capture the leadership in AI, which is envisioned as the next big industrialization. It is an exciting time to be a data practitioner.
https://hai.stanford.edu/news/global-ai-power-rankings-stanford-hai-tool-ranks-36-countries-ai
Uber: Introducing the Prompt Engineering Toolkit

We started to see the pattern, like a software starter pack or framework to build applications quickly, and prompt engineering started to have its starter pack. Uber writes about a prompt engineering toolkit integrating essential components like prompt template management, revision control, and evaluation pipelines, enabling teams to create, iterate, and deploy well-crafted prompts with built-in safety measures and performance tracking.
https://www.uber.com/blog/introducing-the-prompt-engineering-toolkit/
Grab: Supercharging LLM Application Development with LLM-Kit
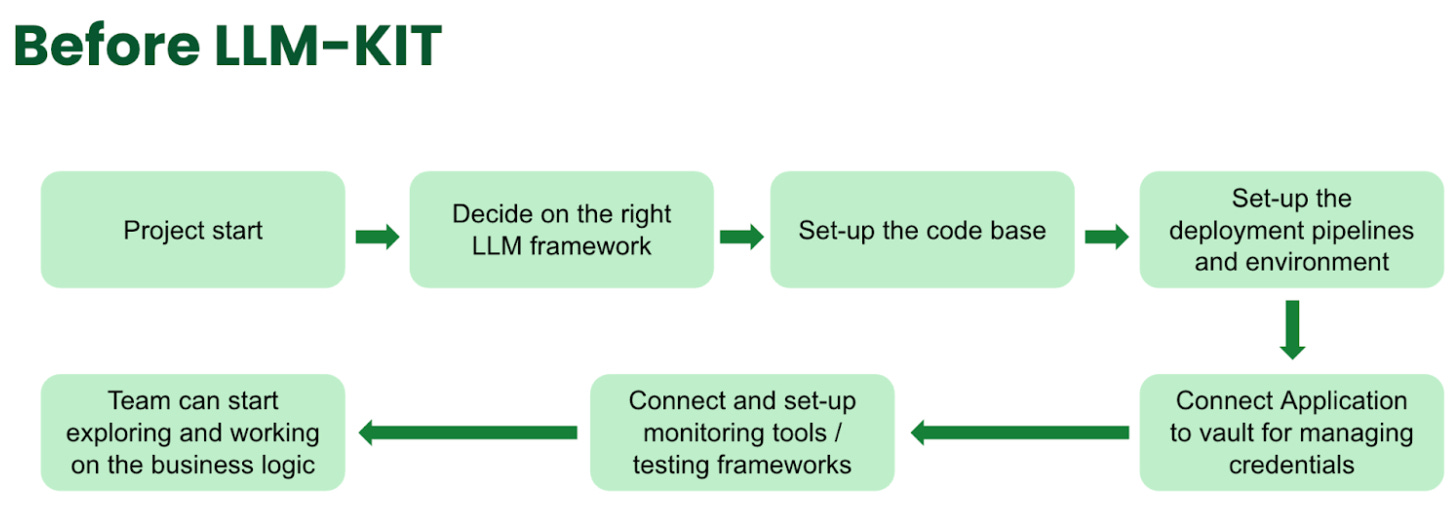

It is almost like Grab and Uber engineering shadow each other; Grab writes about its LLM kit. Grab's LLM-Kit focuses on providing a pre-configured structure and integrated tech stack specifically designed to accelerate the development of production-ready Generative AI applications. The blog emphasizes using a "cookbook" within the organization to provide developers with practical resources.
https://engineering.grab.com/supercharging-llm-application-development-with-llm-kit
LinkedIn: Behind the platform: the journey to create the LinkedIn GenAI application tech stack
LinkedIn rightly pointed out that the adoption of LLM is rapidly increasing among enterprises.
(LinkedIn moved from) simple “prompt in, string out” solutions to crafting assistive agent experiences that offered multi-turn conversation capabilities supported by advanced contextual memory.
As the adoption and functionality increase, we can’t deny the complexity also increases. The LinkedIn GenAI platform story is a precursor for many enterprise adoptions of Gen AI.
Fiverr: Democratize Data and Information With Text-To-Code Models (text2sql)
For years, many tried to build abstractions or alternates on top of SQL, but not much with success. Will Gen AI be the closest abstract that is potentially suited as an alternative to SQL? Maybe; I’m not sure yet. It is great to see more companies write about the adoption of text2sql. Fiverr writes about such adoption and publishes the accuracy of different models.

Airbnb: From Data to Insights: Segmenting Airbnb’s Supply

One of my favorite articles this week is Airbnb, which discusses how it segments Airbnb’s supply. Segmentation brings a unique challenge as diverse datasets bring different facts at different lifecycle points. The blog also demonstrates the value of segmentation & data engineering in a business operation when it is done right.
https://medium.com/airbnb-engineering/from-data-to-insights-segmenting-airbnbs-supply-c88aa2bb9399
Domenic Cassisi: Why is Kafka not Ideal for Event Sourcing?
Event sourcing is the core of data engineering, and Kafka is a standard tool for data pipelines. But is Kafka the ideal solution for event sourcing? The question has haunted me for almost 5 years now, and all my architecture designs always have a workaround for Kafka limitation, where it can’t efficiently handle multi-tenant, head-of-the-line blocking issues. I stumbled upon this blog where the author reflected some of my thoughts on Kafka.
https://dcassisi.com/2023/05/06/why-is-kafka-not-ideal-for-event-sourcing/
Vu Trinh: How does Netflix ensure the data quality for thousands of Apache Iceberg tables?

This is an excellent summarization of Netflix's usage of the WAP pattern on Apache Iceberg to ensure data quality. At DEW, we wrote extensively about WAP patterns and data quality management, which tightly coupled the data contract concept. The author narrates how Iceberg's branching and tag feature helps build a zero-copy WAP pattern.
Elad Shaabi: BigQuery HLL: How we cut COUNT(DISTINCT) query costs by 93% using HyperLogLog

Never use count(distinct), use approax_count_distinct as a default
The data team should emphasize adopting a probabilistic data structure to improve the cost efficiency and speed of the query. The author walks through how the HyperLogLog approach of approx count gives better performance at a lower cost.
Tom Moertel: Sampling with SQL
Sampling is another efficient approach to improve speed and lower costs to produce statistically significant results. The blog is elegant and well-written, discussing the sampling algorithms and their efficiency.
https://blog.moertel.com/posts/2024-08-23-sampling-with-sql.html
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.
Thank you for featuring my article, 'How does Netflix ensure the data quality for thousands of Apache Iceberg tables?' It’s always an honor for me.
Did AI produce that map? That is not where Japan is located and Singapore is listed but Malaysia is in color…