
Data Engineering Weekly #200
The Weekly Data Engineering Newsletter


Try Fully Managed Apache Airflow for FREE
Run Airflow without the hassle and management complexity. Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. For a limited time, new sign-ups will receive a complimentary Airflow Fundamentals Certification exam (normally $150).
Editor’s Note: Celebrating the 200th Edition of Data Engineering Weekly
As we publish the 200th edition of Data Engineering Weekly, I want to take a moment to express my deepest gratitude to each of you—our readers, contributors, and supporters. What began as a fun initiative to share insights and learnings has grown into a thriving community of global data practitioners.

Your engagement, feedback, and passion for data engineering have been the cornerstone of this journey. Thank you for your continued support and for making this milestone possible. Here’s to the next 200 editions of learning and growing together!
Menlo Ventures: 2024 - The State of Generative AI in the Enterprise
2024 marks the year that generative AI became a mission-critical imperative for the enterprise. The Menlo Ventures state of Gen AI highlights the growing impact of Gen AI in the enterprise landscape.

https://menlovc.com/2024-the-state-of-generative-ai-in-the-enterprise
Meltware: A First Look at S3 (Iceberg) Tables
AWS's announcement of the S3 Table is the biggest news in the data industry. The blog is an excellent first look at S3 tables. The idea of object storage supporting the table format is excellent progress and gives a path to many interesting innovations like this. I'm excited about the S3 table and its potential. Remember, without S3, there would be no Iceberg.

https://meltware.com/2024/12/04/s3-tables
AWS: How Amazon S3 Tables use compaction to improve query performance by up to 3 times
AWS wrote the first tech blog highlighting the S3 Table's 3X performance by improving compaction. The blog compares the performance of compacted tables vs. uncompacted tables. However, the blog does not explain the S3 table compaction strategy in depth. This talk gives an excellent summary of how AWS Glue handles Iceberg compaction.
Talk: AWS Glue's Iceberg Optimizations: Compaction, Snapshot Expiration & Future Plans
Sponsored: Airflow Best Practices: Debugging & Testing

No matter how well you know Airflow, DAG errors are inevitable.
Don't miss:
→ Helpful Airflow features for debugging your DAGs
→ How to avoid common issues
→ Unit testing
→ Automating tests as part of a CICD workflow
Gojek: GoSage - How We Detect Fraud Syndicates at Gojek with Graph Neural Networks
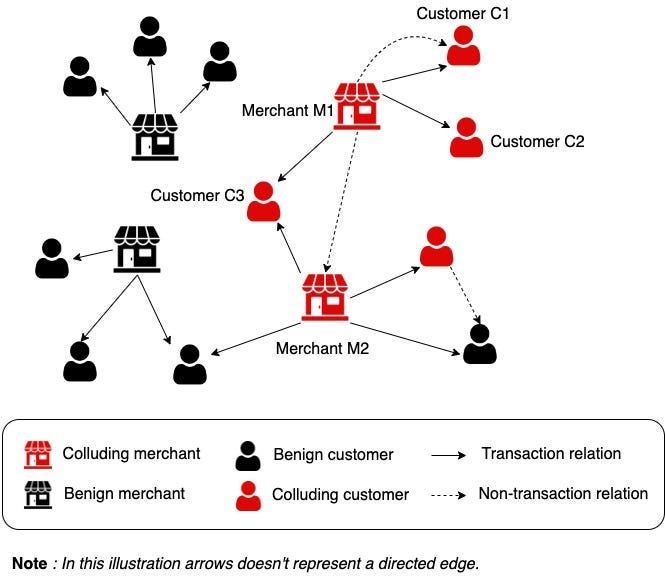
Gojek writes about GoSage, a Graph Neural Network (GNN)- based solution that detects complex fraud patterns by analyzing relationships between entities on its platform. GoSage utilizes a hierarchical attention mechanism to prioritize critical connections, capture higher-order interactions, and identify sophisticated collusion schemes. The approach helped Gojek significantly improve fraud detection capabilities, reducing false positives and enhancing platform security.
Grab: How we seamlessly migrated high-volume real-time streaming traffic from one service to another with zero data loss and duplication
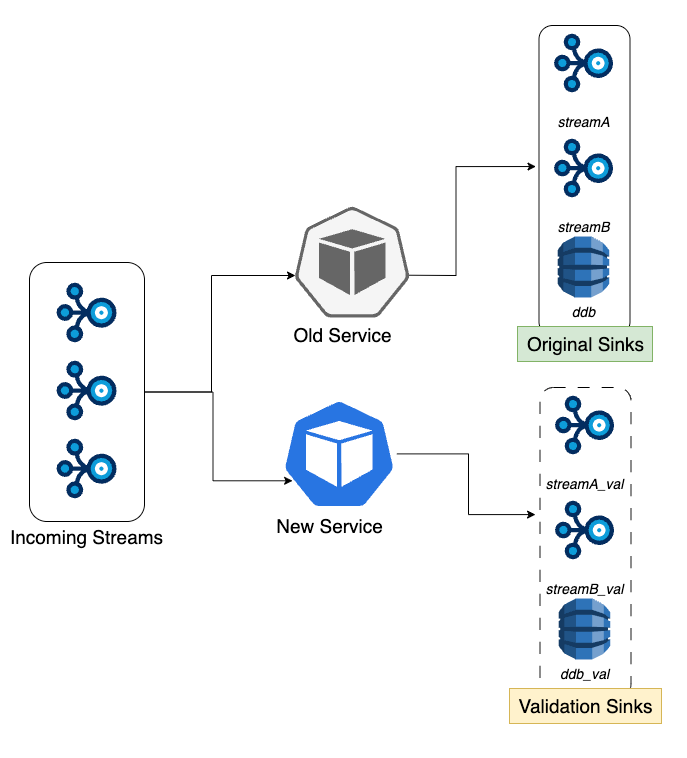
Grab describes migrating a backend service's stream processing functionality to a new service, ensuring zero data loss or duplication while handling 20,000 reads per second. The team implemented a custom time-based switchover logic in shared code, scheduling precise cutover times for each stream to coordinate the transition between services. This strategy and thorough testing and monitoring enabled a seamless migration completed in three weeks without downtime or data inconsistencies.
https://engineering.grab.com/seamless-migration
Christian Winter: The History of the Decline and Fall of In-Memory Database Systems

There is increased activity in the data industry in in-process/single-node OLAP engines like DuckDB. The article discusses the decline of in-memory database systems, which initially gained popularity in the early 2010s due to decreasing memory prices and increasing hardware reliability. Despite their initial promise of speed and simplicity, the stagnation of RAM price drops and the continued growth of data, coupled with the rise of affordable and fast SSDs, led to their diminished adoption.
https://cedardb.com/blog/in_memory_dbms/
Expedia: Turbocharging Efficiency & Slashing Costs: Mastering Spark & Iceberg Joins with Storage-Partitioned
The industry perceives that moving to a LakeHouse format will be inexpensive compared to other preparatory databases. Though this is true to an extent, inefficient data modeling will consume more computing costs. Expedia writes about one such optimization with storage-partitioned join.
Twitch: Views pwn Tables as data interfaces
Twitch describes leveraging Views with its Data Lake to enhance data agility, minimize downtime, and streamline data reprocessing. Views provide a consistent and adaptable interface, enabling actions like atomic swaps for dataset promotion, seamless column renames, and VARCHAR resizing without data restatement. This approach allows Twitch to respond to data quality issues quickly, implement two-way door changes, and improve developer workflows, ultimately supporting over 100 petabytes of data and 8,000 datasets.
https://blog.twitch.tv/en/2024/12/05/views-pwn-tables-as-data-interfaces/
Kirill Bobrov: How to Speed Up Spark Jobs on Small Test Datasets
Most often, we run Spark jobs on data that is small enough. The blog is an excellent read as a reminder that having this hammer for every problem is okay, except you know how to tune it. The author suggests a set of configurations to tune while running the Spark on a single node.
https://luminousmen.com/post/how-to-speed-up-spark-jobs-on-small-test-datasets
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.