
Data Engineering Weekly #201
The Weekly Data Engineering Newsletter


Try Fully Managed Apache Airflow for FREE
Run Airflow without the hassle and management complexity. Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. For a limited time, new sign-ups will receive a complimentary Airflow Fundamentals Certification exam (normally $150).
Meta: Typed Python in 2024: Well adopted, yet usability challenges persist
It is almost 10 years since the introduction of type hinting in Python. Meta published the state of the type hint usage of Python. Python is undeniably becoming the de facto language for data practitioners.
88% of respondents “Always” or “Often” use Types in their Python code. The blog further gives insight into IDE usage and documentation access.
https://engineering.fb.com/2024/12/09/developer-tools/typed-python-2024-survey-meta/
Coiled: DataFrames at Scale Comparison: TPC-H
Dataframe is the fundamental component of many data analysis libraries. Every DataFrame implementation has its pros and cons. The coiled team published the TPC-H benchmark study on various dataframe and recommendations on when to use what.
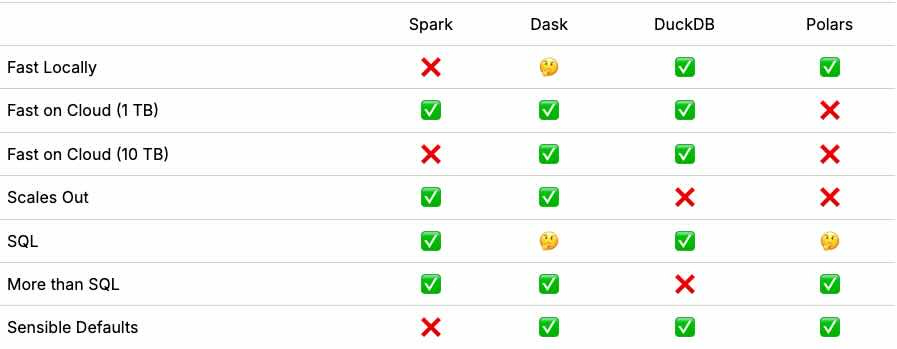
https://docs.coiled.io/blog/tpch.html
Dani: Apache Iceberg: The Hadoop of the Modern Data Stack?

We can’t deny the tug-of-war in the industry over Apache Iceberg. The comment on Iceber, a Hadoop of the modern data stack, surprises me. However, I 100% agree with the complex stack to maintain. Iceberg has not reduced the complexity of the data stack, and all the legacy Hadoop complexity still exists on top of Apache Iceberg.
https://blog.det.life/apache-iceberg-the-hadoop-of-the-modern-data-stack-c83f63a4ebb9
Sponsored: Apache Airflow® Best Practices: ETL and ELT Pipelines
If you're reading this... this guide is for you!

Your comprehensive 44-page guide to one of the most common data engineering use cases on the top open-source orchestrator.
LinkedIn: Practical text-to-SQL for data analytics

LinkedIn writes about its internal SQL Bot, an AI-powered assistant that translates natural language into SQL queries, enabling employees to access data insights independently. The tool leverages a multi-agent system built on LangChain and LangGraph, incorporating strategies like quality table metadata, personalized retrieval, knowledge graphs, and Large Language Models (LLMs) for accurate query generation. These features, combined with a user-friendly interface and options for customization, resulted in high adoption rates and positive feedback, with 95% of users rating SQL Bot's accuracy as "Passes" or above.
https://www.linkedin.com/blog/engineering/ai/practical-text-to-sql-for-data-analytics
Miguel: Nobody Gets Fired for Picking JSON, but Maybe They Should?
If you control the data source's origin, always choose ProtoBuf or Avro formats rather than JSON. While widely used for data interchange, JSON presents several challenges that can impact system compatibility and efficiency. The article demonstrates various challenges in adopting JSON formats.
Number Handling: JSON's lack of specific number types can cause problems with large integers and special values like Infinity and NaN.
Text Encoding: Allowing unpaired surrogates in strings can lead to compatibility issues between systems.
Lack of Byte String Support: It is difficult to handle binary data efficiently.
Streaming Limitations: JSON doesn't natively support streaming, causing issues with large datasets.
Canonicalization and Data Loss: Canonicalizing JSON for digital signatures can lead to data loss.
Parser Diversity: The varying behavior of JSON parsers can cause interoperability problems.
https://mcyoung.xyz/2024/12/10/json-sucks/
Simon Willison: Storing times for human events
The author argues against storing event times solely in UTC, advocating instead for recording the user's intended time and location to avoid issues stemming from user error or timezone changes. The article highlights the complexities of storing event times due to incorrect user timezone selection and unexpected changes in international timezone rules, as exemplified by the Lebanon DST dispute and the Microsoft Exchange DST update 2007. The author recommends storing the user's intended time alongside the event's location and timezone, allowing for accurate representation and updates.
https://simonwillison.net/2024/Nov/27/storing-times-for-human-events/
Adeshola Afolabi: Evaluating Quality in Large Language Models: A Comprehensive Approach using the legal industry as a use case

Evaluating Large Language Models (LLMs) in the legal field requires a multifaceted approach, considering jurisdictional accuracy, legal terminology, contractual precision, compliance, and the currency of legal knowledge. The article discusses various methodologies, including traditional metrics like Precision, Recall, F1 Score, and BLEU, but emphasizes their limitations in capturing the nuances of legal language and context. It highlights the emerging trend of using LLMs as evaluators, multi-agent debates for nuanced assessments, and the indispensable role of subject matter experts (SMEs) for contextual understanding and risk assessment while also introducing tools like Scorecard and DeepEval to streamline the evaluation process.
Spotify: Building Confidence: A Case Study in How to Create Confidence Scores for GenAI Applications

The article discusses the challenge of determining confidence scores for Generative AI (GenAI) responses in financial applications, particularly in automating invoice parsing at Spotify. The authors evaluated three methods: calibrator models, logarithmic probabilities (logprobs), and majority voting, finding that majority voting, an ensemble method selecting the most common response from multiple models, demonstrated the strongest positive correlation with accuracy. Despite its simplicity, implementing majority voting required careful consideration of factors such as the number of models, weight assignment, and score calibration, ultimately leading to a reliable solution for generating confidence scores in their GenAI application.
Dropbox: Selecting a model for semantic search at Dropbox scale
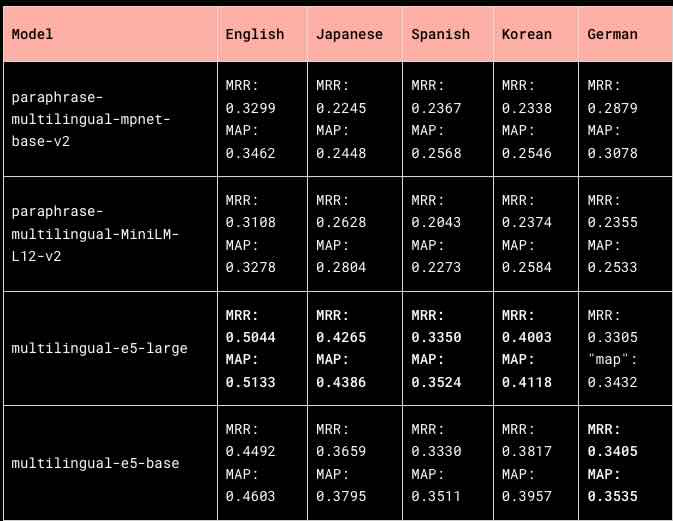
Dropbox writes about its semantic search implementation to enhance its functionality by understanding the meaning behind user queries and document content rather than relying on exact keyword matches. The semantic search implementation, which includes cross-lingual search capabilities, resulted in a 17% reduction in zero-results rate and a 2% increase in qualified click-through rate. Dropbox narrates the extensive evaluation process to choose the multilingual-e5-large model for its speed and quality.
https://dropbox.tech/machine-learning/selecting-model-semantic-search-dropbox-ai
AWS: Build Write-Audit-Publish pattern with Apache Iceberg branching and AWS Glue Data Quality
If you’ve not adopted the WAP (Write-Audit-Publish) pattern in your data pipeline, I highly recommend taking a deeper look at it. At Data Engineering Weekly, we published a comprehensive guide on An Engineering Guide to Data Quality - A Data Contract Perspective. Along the line, AWS writes about implementing the WAP pattern leveraging Iceberg’s branching feature.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.