
Data Engineering Weekly #205
The Weekly Data Engineering Newsletter


Automate Airflow deploys with built-in CI/CD
Streamline code deployment, enhance collaboration, and ensure DevOps best practices with Astro's robust CI/CD capabilities.
Hugging Face: ComplexFuncBench - Exploring Multi-Step and Constrained Function Calling under Long-Context Scenario
Deepseek certainly dispels the myth that building foundation models is expensive. The industry's next wave will focus on strengthening reasoning and instruction-following capabilities. The paper runs the multi-step and constraint function calling and publishes results on various leading foundation models.
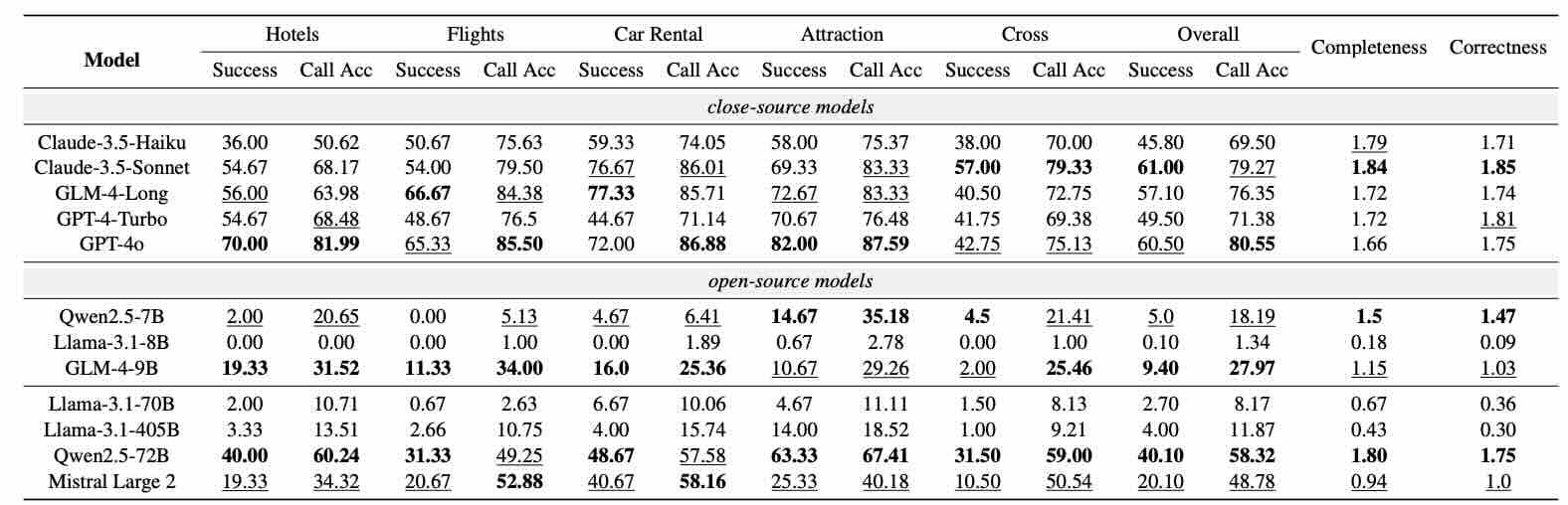
https://huggingface.co/papers/2501.10132
Jason Liu: How to Systematically Improve RAG Applications
The RAG technique is likely one of the first adopted for building Gen AI applications. The author offers a comprehensive guide to enhancing Retrieval-Augmented Generation (RAG) applications, stressing the importance of systematic measurement and iteration rather than random adjustments.
The article discusses common pitfalls such as absence bias and intervention bias while advocating for a user-centric approach that emphasizes evaluating retrieval accuracy through precision and recall, focusing on recall. It also examines techniques like using synthetic data to initiate evaluation, segmenting queries for in-depth analysis, utilizing structured extraction and multimodality for various data types, implementing query routing for specialized indices, fine-tuning embeddings and re-rankers based on user feedback, and improving user experience through feedback loops and strategic UI elements.
Meta: How Meta discovers data flows via lineage at scale
Meta writes about data lineage as a crucial part of its Privacy-Aware Infrastructure (PAI) initiative to track data flows and implement privacy controls, such as purpose limitation. The data lineage system leverages static code analysis, runtime instrumentation, and input/output data matching to collect data flow signals across various technology stacks, creating a comprehensive lineage graph.
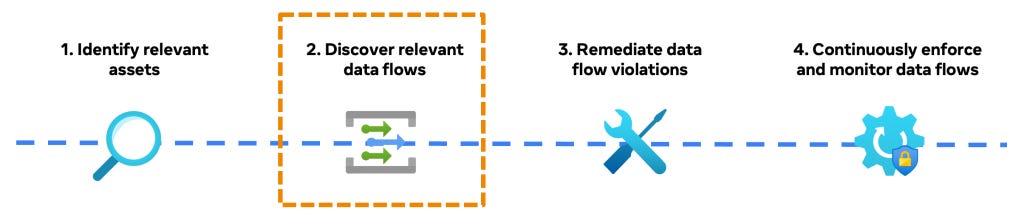
https://engineering.fb.com/2025/01/22/security/how-meta-discovers-data-flows-via-lineage-at-scale/
Sponsored: The Ultimate Guide to Apache Airflow® DAGs

130+ pages of beginner → advanced DAG writing features with plenty of example code.
Alireza Sadeghi: The evolution of business intelligence from monolithic to composable architecture
The semantic layer is a highly debated architectural style in late 2023. The author captures the recent development in the BI layer from a monolithic BI system → bottomless BI tools → universal semantic layer.
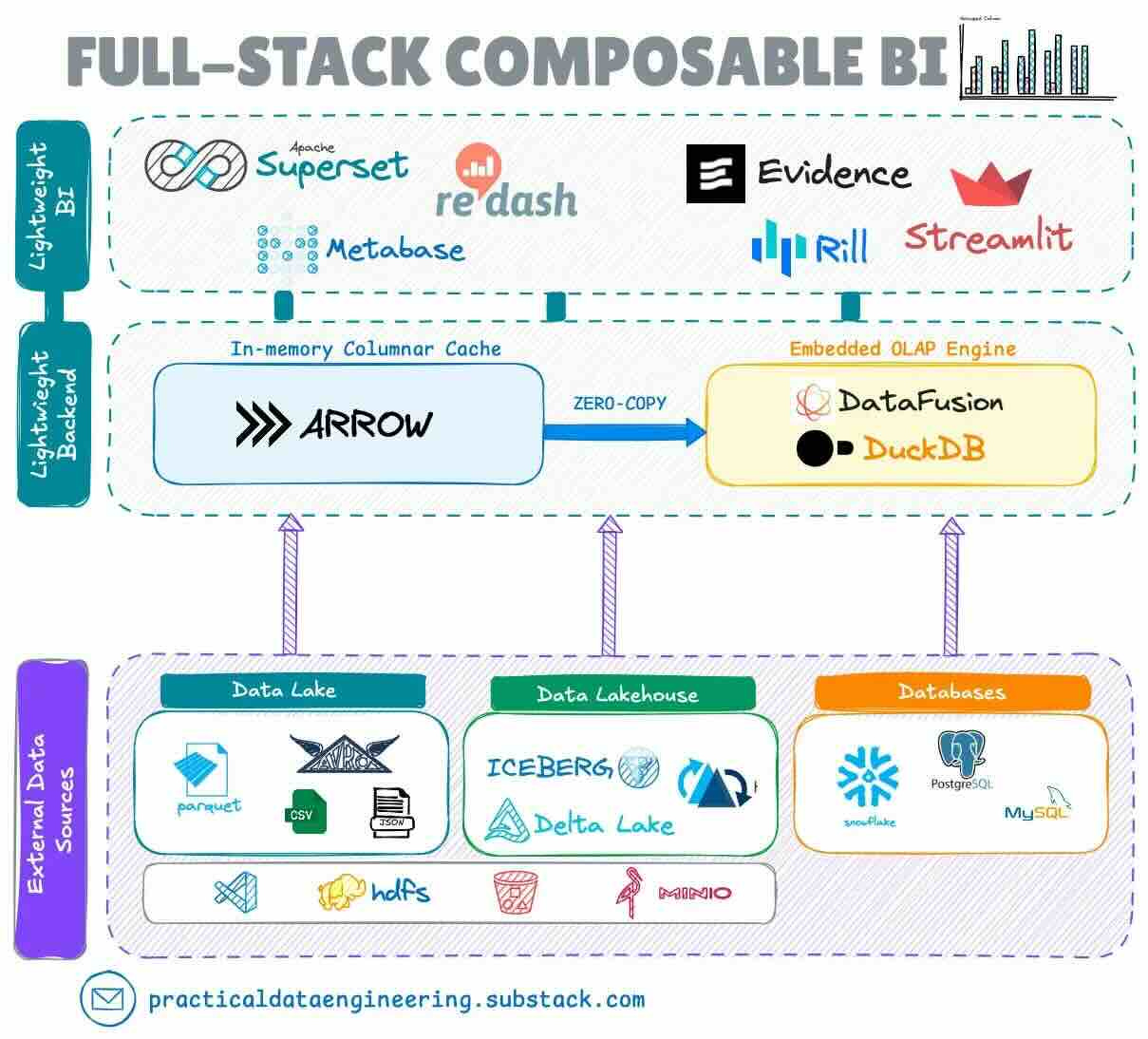
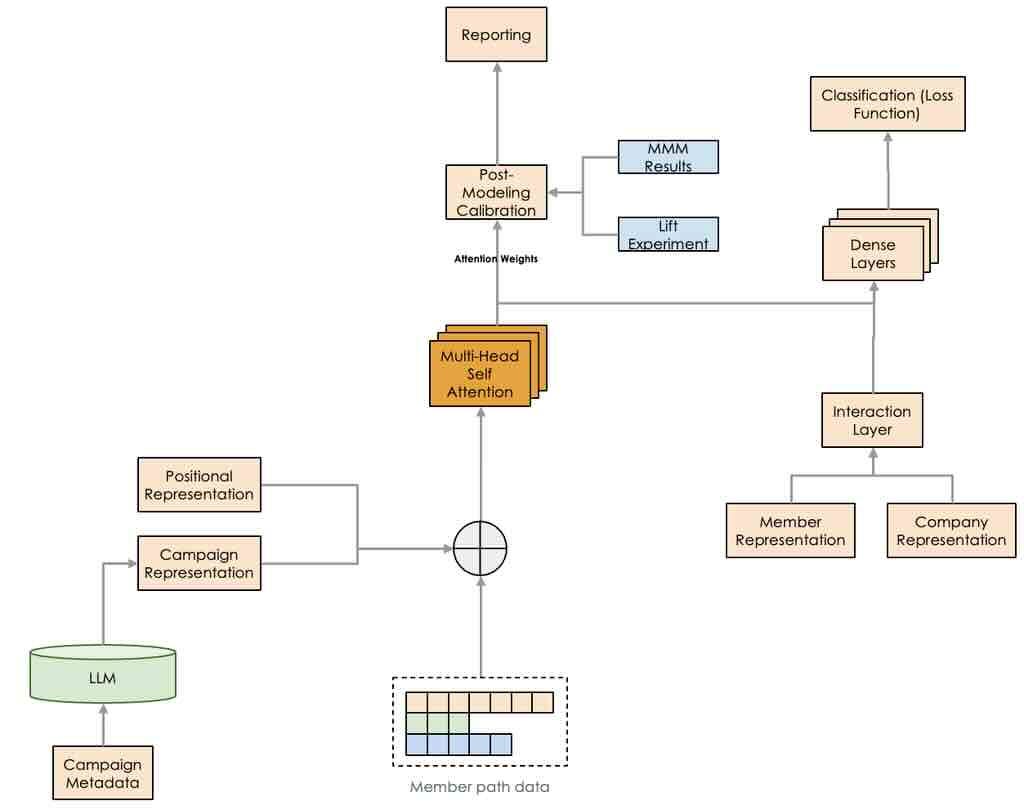
LinkedIn: Buyer journey insights with data-driven attribution
Understanding the customer journey and a data-driven attribution model is vital for successful marketing operations. The blog narrates the difference between rule-based and data-driven attribution models and how LinkedIn is leveraging Multi-Touch Attribution (MTA) and Marketing Mix Modeling (MMM).
Strava: Rain: A key-value store for Strava’s scale
The Strava Geo team developed Rain, a new service that acts as a key-value store for large, immutable datasets generated in Spark, to address challenges related to efficiently serving these datasets. Rain, which behaves like a distributed cache, allows for distributed writes from Spark, immutable data hot-swapping, and cost savings using an LRU Redis cache and a single distributed datastore. This system enables faster iteration, reduced memory footprint, significant cost savings, and the ability to serve terabyte-scale datasets at low latency.
https://medium.com/strava-engineering/rain-a-key-value-store-for-stravas-scale-7f580f5b4848
Glovo: Using Airflow in Glovo for data orchestration
Glovo writes about using Apache Airflow as a central component in its Data Mesh architecture to orchestrate data product computations. Glovo customized Airflow’s components, such as DagFactory, to simplify DAG creation and custom operators, like CheckpointerOperator and CheckpointSensor, to manage data product dependency. Furthermore, the article highlights Glovo's evolution towards a declarative approach to defining data products.

https://medium.com/glovo-engineering/using-airflow-in-glovo-6754a2fe79a5
BlaBlaCar: Data Pipelines Architecture at BlaBlaCar

BlaBlaCar writes about its data pipeline architecture. It follows the typical ELT (Extract, Load, Transform) model orchestrated by Airflow, utilizing tools like Google Dataflow, Rivery, custom Python scripts for ingestion, and dbt for transformations. It is interesting to see more Data Mesh approaches, organizing data into domains with dedicated teams and implementing a robust software development lifecycle for its data pipelines, including version control, code reviews, and automated testing.
https://medium.com/blablacar/data-pipelines-architecture-at-blablacar-3ca43403cb39
Andy Sawyer: C4 Modelling for Data Teams: From Chaos to Clarity
C4 diagram is predominant in defining the software architecture, and never thought through C4 for data teams. The author explores the idea of C4 modeling for the data teams.
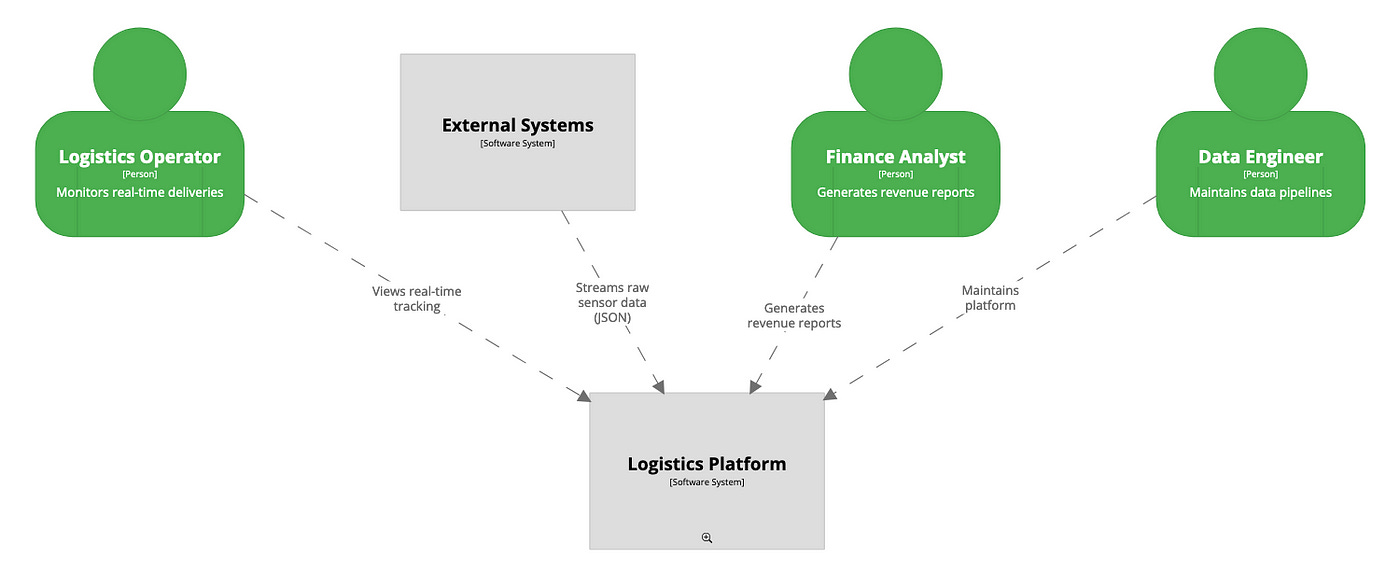
https://blog.datatraininglab.com/c4-modelling-for-data-teams-from-chaos-to-clarity-a9f499007e20
Pranav Aurora: How to improve DuckDB performance on Parquet
With Polaris, Unity Catalog, and Glue Catalog, I’m excited about the potential of having table metadata, such as summary statistics, stored for efficient and quick look-up to accelerate query performance. The author describes how pg_mooncake, a Postgres extension, surpasses DuckDB in certain analytical workloads while using DuckDB internally and storing data in Parquet files. Pg_mooncake utilizes Postgres to store table and detailed Parquet metadata, including column statistics, which allows for effective filtering of data files and row groups during query execution.
https://www.mooncake.dev/blog/duckdb-parquet
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
No doubt, Airflow is one of the best scheduling tools for data engineering pipeline. Thanks for sharing
Thank you for the share. My article is also available on SubStack for those not wanting to leave the platform: https://open.substack.com/pub/datatraininglab/p/c4-modelling-for-data-teams-from?r=2egmtf&utm_medium=ios