
Data Engineering Weekly #206
The Weekly Data Engineering Newsletter


Automate Airflow deploys with built-in CI/CD.
Streamline code deployment, enhance collaboration, and ensure DevOps best practices with Astro's robust CI/CD capabilities.
Jay Alammar: The Illustrated DeepSeek-R1
DeepSeek triggered quite a conversation and had an economic impact last week. Many articles explain how DeepSeek works, and I found the illustrated example much simpler to understand. DeepSeek development involves a unique training recipe that generates a large dataset of long chain-of-thought reasoning examples, utilizes an interim high-quality reasoning model, and employs large-scale reinforcement learning (RL). Notably, the process includes an RL step to create a specialized reasoning model (R1-Zero) capable of excelling in reasoning tasks without labeled SFT data, highlighting advancements in training methodologies for AI models.

https://newsletter.languagemodels.co/p/the-illustrated-deepseek-r1
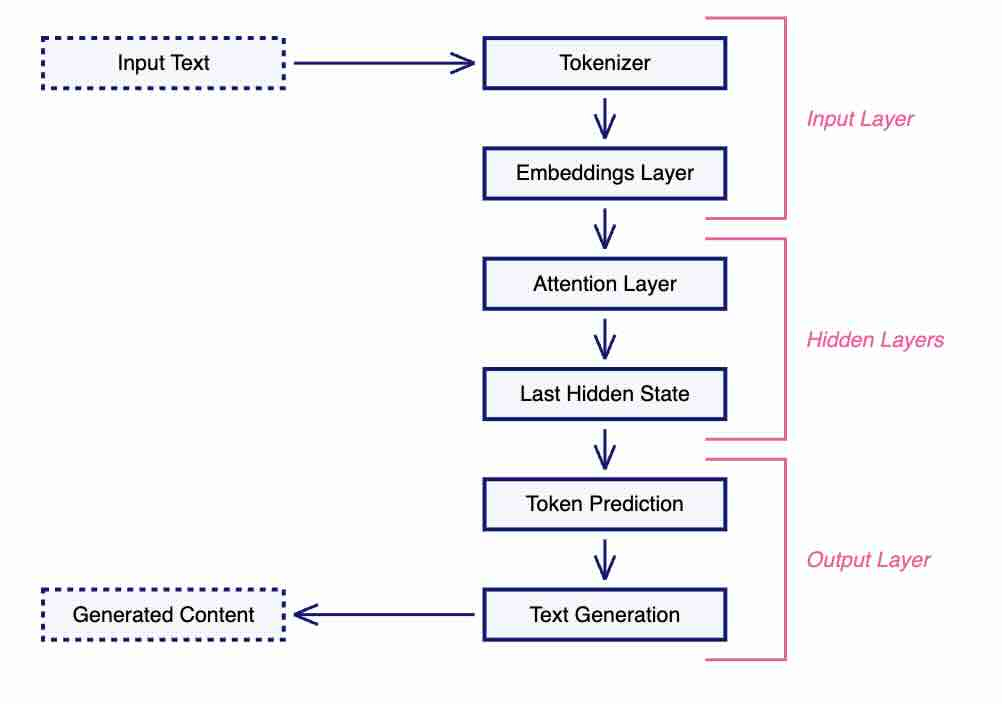
Bharani Subramaniam & Martin Fowler: Emerging Patterns in Building GenAI Products
The article discusses the challenges of transitioning Generative AI products to production and introduces patterns to address these issues, focusing on Direct Prompting, Evals, and embedding. Direct Prompting involves sending user prompts directly to an LLM, which is useful but limited by the model's training data and potential for misuse. Evals are introduced to evaluate LLM responses through various techniques, including self-evaluation, using another LLM as a judge, or human evaluation to ensure the system's behavior aligns with intentions.
https://martinfowler.com/articles/gen-ai-patterns/
Pinterest: Establishing a Large-Scale Learned Retrieval System at Pinterest
Pinterest discusses an embedding-based retrieval system that enhances its recommendation capabilities. It employs a two-tower model approach to learn query and item embeddings from user engagement data. Pinterest implements this system for home feed and notification services, utilizing a combination of long-term user engagement, user profiles, and contextual information to improve user engagement and efficiency significantly. The article covers the implementation details, including an auto-retraining workflow to maintain model freshness and ensure synchronization between the user and item embedding models during deployment.

Github: How we evaluate AI models and LLMs for GitHub Copilot
GitHub Copilot shares its approach to evaluating AI models. It focuses on automated offline evaluations to assess performance, quality, and safety before integrating new models like Anthropic's Claude 3.5 Sonnet and Google's Gemini 1.5 Pro. The evaluation process includes over 4,000 automated tests, measuring the percentage of passing unit tests, similarity to known passing states, and token usage. It also includes manual and automated assessments of chat capabilities using a separate LLM for quality assurance. All these efforts aim to maintain high standards for code generation and assistance.
https://github.blog/ai-and-ml/generative-ai/how-we-evaluate-models-for-github-copilot/
Navid Rekabsaz: Bias and Fairness in Natural Language Processing
The article discusses bias and fairness in AI and NLP applications, emphasizing how societal biases encoded in training data can lead to unfair model predictions. The author highlights methods to identify and measure these biases, such as using counterfactual examples and analyzing gender-specific associations in word embeddings. The article advocates for a three-pronged approach to mitigate biases—pre-processing, post-processing, and in-processing methods—and stresses the importance of defining fairness in specific application contexts, measuring bias, and implementing appropriate mitigation strategies to ensure responsible and equitable NLP system deployment.
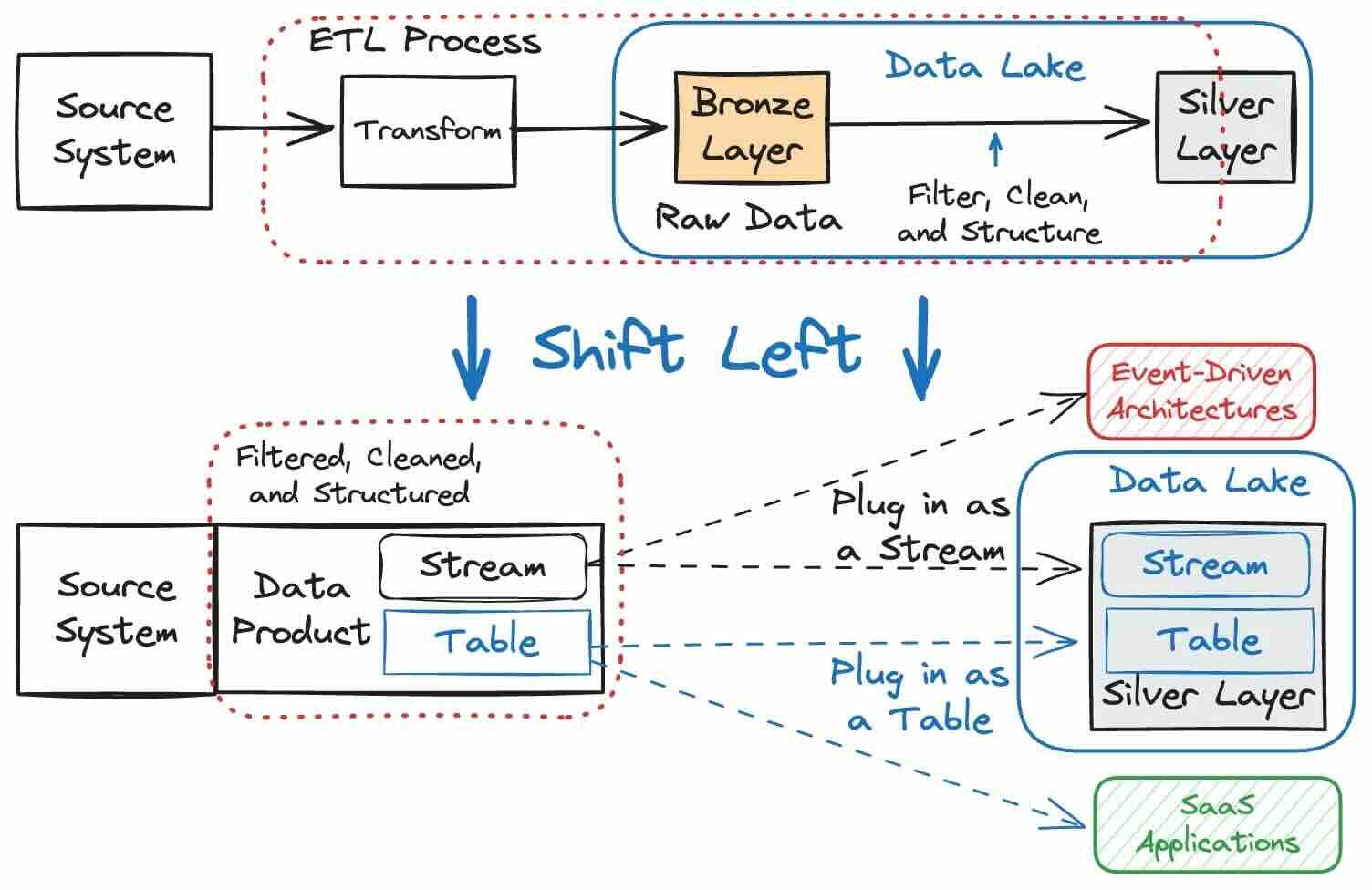
Adam Bellemare & Thomas Betts: The End of the Bronze Age: Rethinking the Medallion Architecture
I’m always a bit uncomfortable with medallion architecture since it is a glorified term for the traditional ETL process. I finally found a good critique that discusses its flaws, such as multi-hop architecture, inefficiencies, high costs, and difficulties maintaining data quality and reusability.
The article advocates for a "shift left" approach to data processing, improving data accessibility, quality, and efficiency for operational and analytical use cases. Shifting left involves moving data processing upstream, closer to the source, enabling broader access to high-quality data through well-defined data products and contracts, thus reducing duplication, enhancing data integrity, and bridging the gap between operational and analytical data domains.
https://www.infoq.com/articles/rethinking-medallion-architecture/
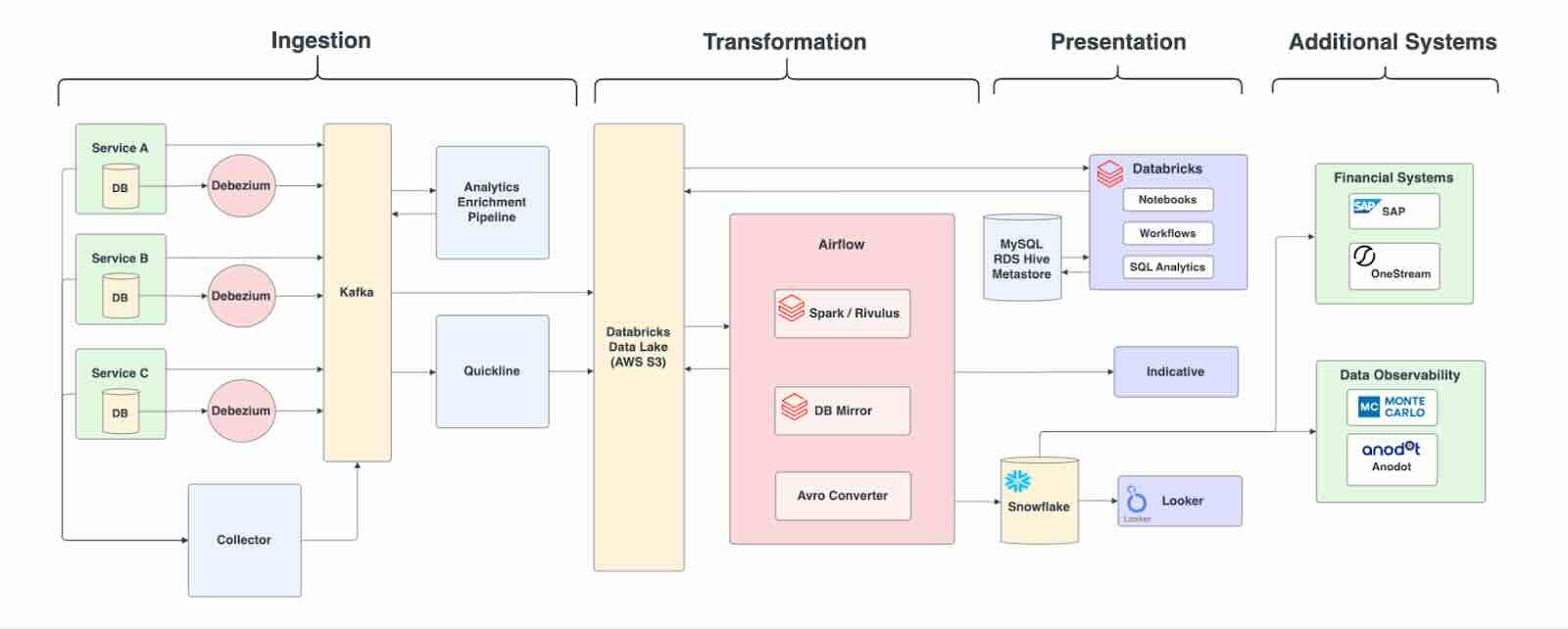
Get Your Guide: From Snowflake to Databricks: Our cost-effective journey to a unified data warehouse.
GetYourGuide discusses migrating its Business Intelligence (BI) data source from Snowflake to Databricks, achieving a 20% cost reduction. The article highlights the use of Looker for BI analysis and the centralization of its data warehouse to streamline infrastructure. The migration featured an incremental rollout, automated validations, and performance optimizations, leading to 98% of queries functioning correctly and 72% executing in under 10 seconds.
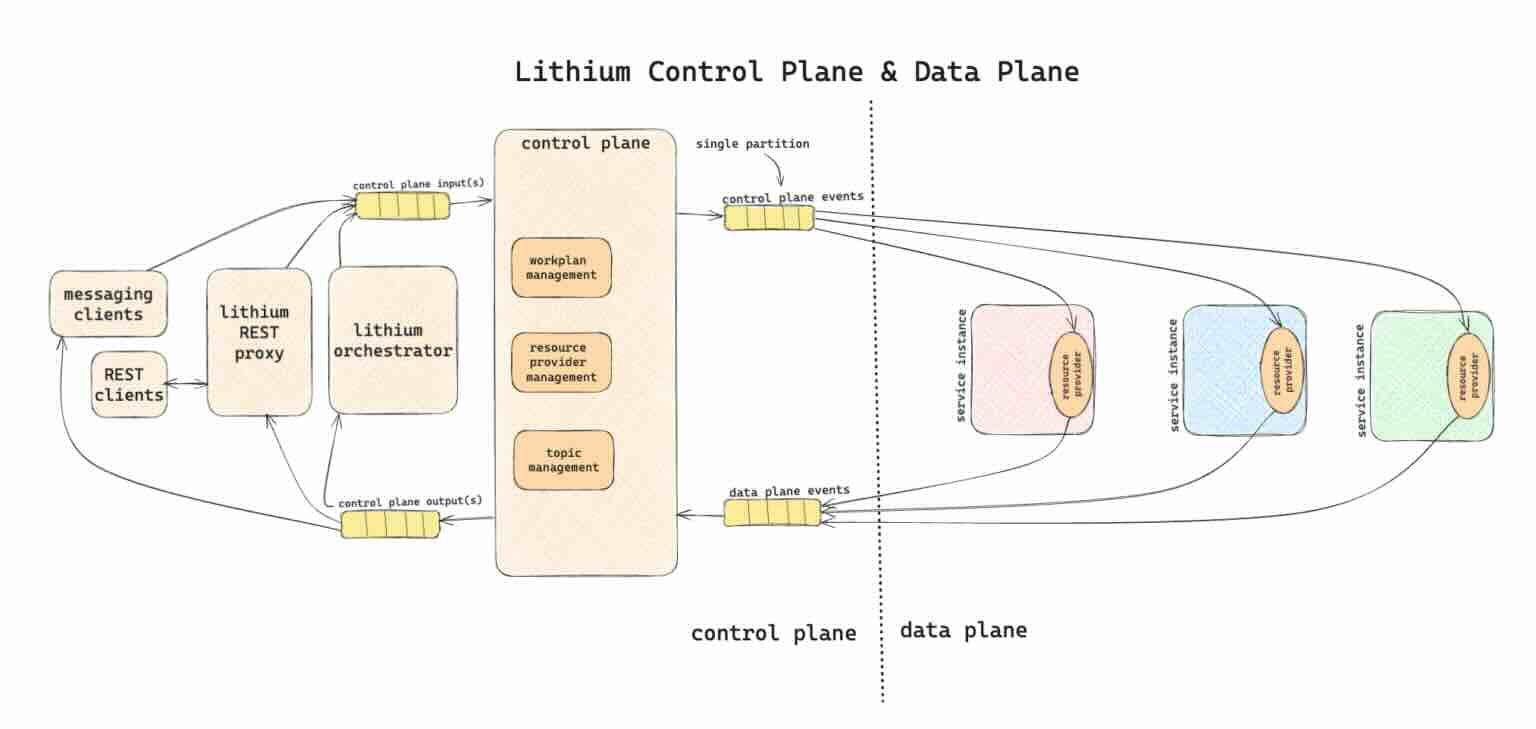
Atlassian: Lithium - elevating ETL with ephemeral and self-hosted pipelines
The article introduces Lithium, an ETL++ platform developed by Atlassian for dynamic and ephemeral data pipelines, addressing unique needs like user-initiated migrations and scheduled backups. Lithium uses a Bring Your Own Host (BYOH) model, allowing developers to integrate custom processors within their services and ensuring data proximity and tenant isolation. Key features include workplan auctioning for resource allocation, in-progress remediation for handling data validation failures, and integration with external Kafka topics, achieving a throughput of 1.2 million entities per second in production.
https://www.atlassian.com/blog/atlassian-engineering/lithium
Affirm: Expressive Time Travel and Data Validation for Financial Workloads
Affirm migrated from daily MySQL snapshots to Change Data Capture (CDC) replay using Apache Iceberg for its data lake, improving data integrity and governance. The CDC approach addresses challenges like time travel, data validation, performance, and cost by replicating operational data to an AWS S3-based Iceberg Data Lake. The new system automates validation, reduces operational costs by 6x, decreases data storage needs by 1024x, and improves data pipeline performance by 40%.

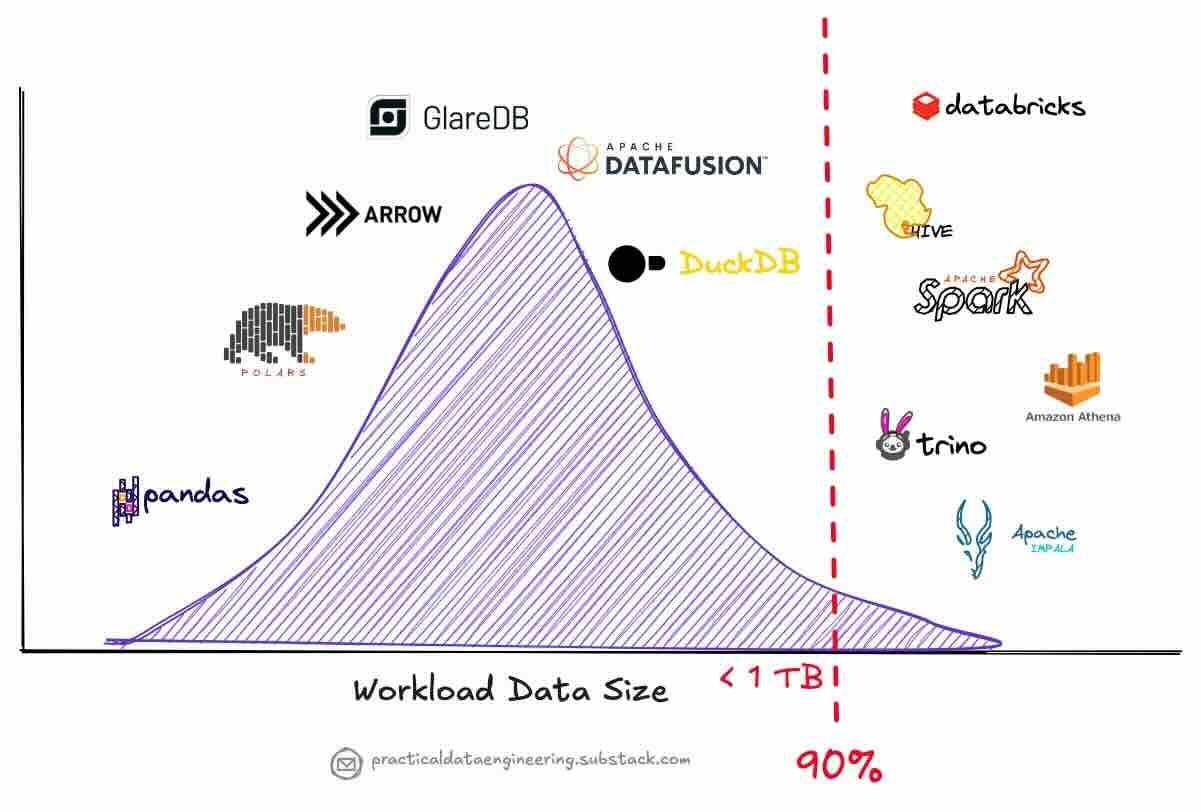
Alireza Sadeghi: The rise of single-node processing engines
The article highlights the growing popularity of single-node processing frameworks like DuckDB, Apache DataFusion, and Polars in 2024, challenging the distributed-first mindset of the "big data" era. It argues that most companies lack true "big data" and that single-node solutions offer a more efficient, cost-effective approach for their analytical needs, especially considering data aging effects and the 90/10 rule of analytical workloads. Moreover, advancements in hardware and the economics of cloud pricing further support the case for single-node processing, offering simplified architecture, better resource utilization, and seamless integration with modern data workflows.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.