
Data Engineering Weekly #207
The Weekly Data Engineering Newsletter


Automate Airflow deploys with built-in CI/CD.
Streamline code deployment, enhance collaboration, and ensure DevOps best practices with Astro's robust CI/CD capabilities.
Hugging Face: Mixture of Experts Explained
The mixture of Experts (MoEs) are transformer models efficiently gaining traction in the open AI community. MoEs necessitate less compute for pre-training compared to dense models, facilitating the scaling of model and dataset size within similar computational budgets. The article further details techniques, such as load balancing, expert capacity, and parallelism strategies, to enhance MoE training and inference efficiency.
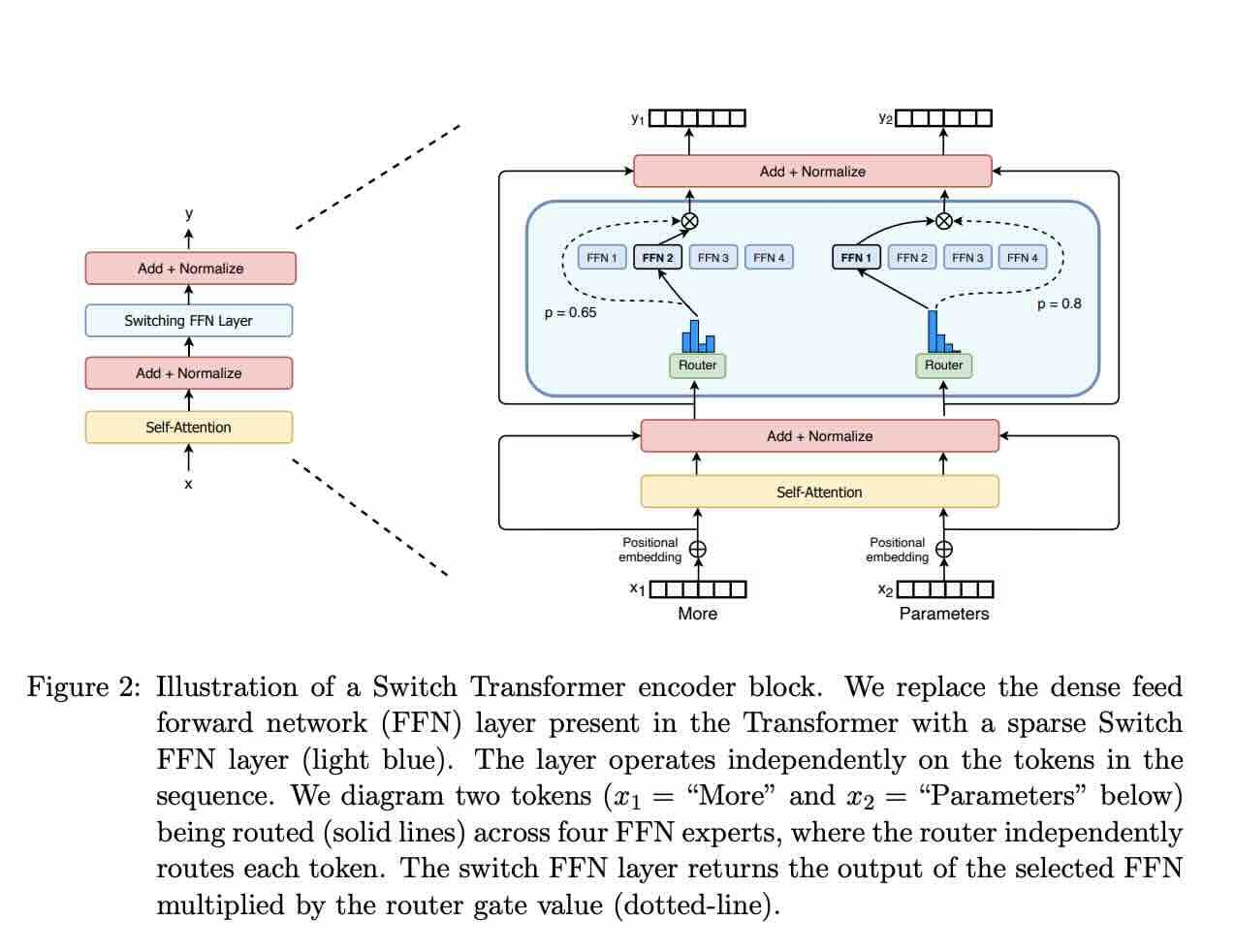
https://huggingface.co/blog/moe
QuantumBlack: Solving data quality for gen AI applications
Unstructured data processing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in data processing and quality, but what data quality means in unstructured data is a top question for every organization. I found the product blog from QuantumBlack gives a view of data quality in unstructured data.
https://medium.com/quantumblack/solving-data-quality-for-gen-ai-applications-11cbec4cbe72
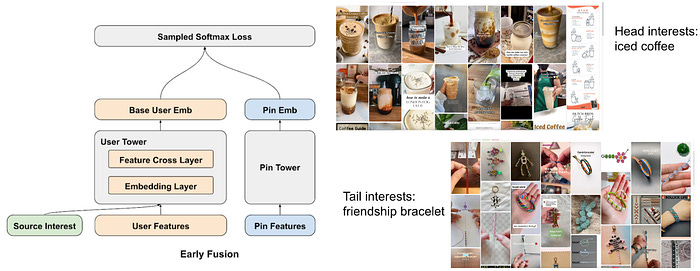
Pinterest: Advancements in Embedding-Based Retrieval at Pinterest Homefeed
Pinterest writes about its embedding-based retrieval system enhancements for Homefeed personalization and engagement. The system improves user interactions by integrating MaskNet and DHEN feature crossing, scaling embeddings via contrastive learning, and refining the serving corpus with time-decayed scoring mechanisms. The blog post highlights the industry trend of search engines transitioning towards embedding-based systems, moving beyond traditional IDF models.
Sponsored: Webinar - Implementing CI/CD workflows for your Airflow pipelines
Want to automate key parts of your Apache Airflow pipeline development lifecycle?

In this session, Marc Lamberti and Kenten Danas will cover everything you need to know about using CI/CD to manage your Airflow DAGs, including:
→ The basics of using CI/CD with Airflow
→ How to leverage Astro’s built-in Github integration and other CI/CD features
→ Strategies for choosing and implementing the best deployment options
Airbnb: Improving Search Ranking for Maps
Airbnb writes about the challenge of ranking search results on maps, which is distinct from list-based rankings due to uniform user attention across map pins. Airbnb restricted the range of booking probabilities for map pins, which led to significant booking improvements. Further iterations included tiered map pins and a map re-centering algorithm based on booking probabilities. The system design is an excellent reminder of thinking from a user's perspective.
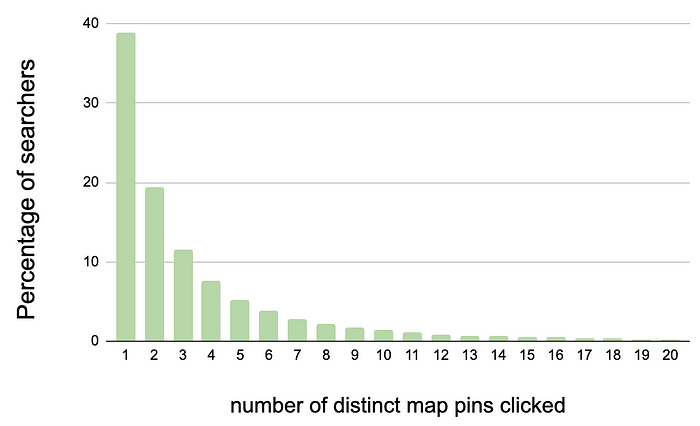
https://medium.com/airbnb-engineering/improving-search-ranking-for-maps-13b03f2c2cca
Yelp: Search Query Understanding with LLMs: From Ideation to Production
Yelp's blog discusses integrating large language models (LLMs) to enhance its understanding of millions of daily search queries. The blog narrates a multi-stage process, from ideation to production rollout, leveraging LLMs for tasks like query segmentation and review highlighting, significantly improving user experience. The blog emphasizes a strategic approach involving proof-of-concept testing, fine-tuning smaller models for cost-effectiveness, and iterative prompt engineering to achieve scalable and impactful results in real-world search applications.

https://engineeringblog.yelp.com/2025/02/search-query-understanding-with-LLMs.html
Meta: Data logs - The latest evolution in Meta’s access tools
Meta writes about its access tool's system design, which helps export individual users’ access logs. The blog highlights the challenges of Hive-style large data warehouses not fitting for finding the needle-in-the-haystack problem and the importance of batching such requests.
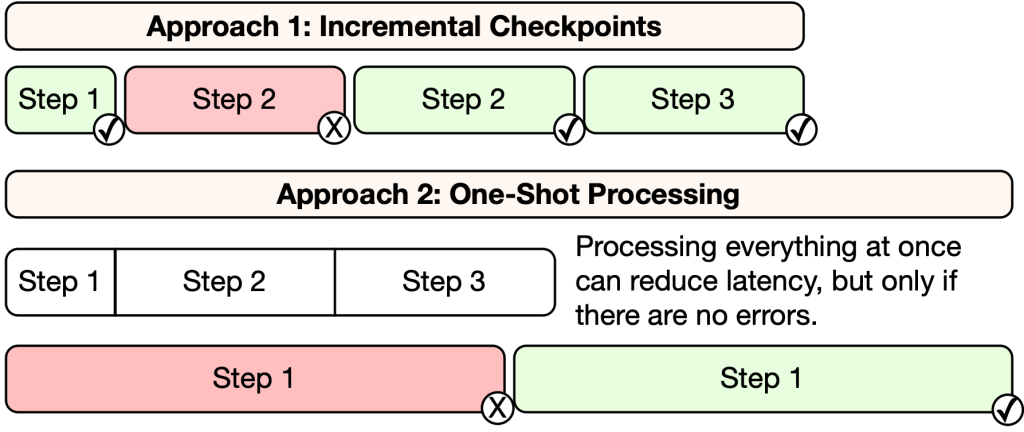
https://engineering.fb.com/2025/02/04/security/data-logs-the-latest-evolution-in-metas-access-tools/
GetInData: Data Quality in Streaming: A Deep Dive into Apache Flink
Data Quality in a real-time streaming system is always challenging. Though sophisticated row-based quality frameworks like CEL (Common Expression Language) provide efficient checking, the challenge is always measuring data quality over a period of time. GetInData writes an excellent summary of adding data quality checks in a Flink streaming pipeline.
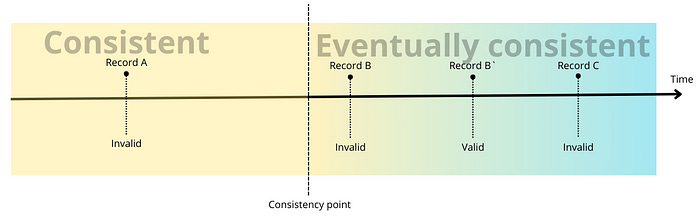
Fernando Borretti: Composable SQL
One of the biggest challenges in SQL is the unit testing. The author highlights three key challenges in SQL.
Intractability of Testing: Even simpler queries require a larger, complex object graph of test data
Lake of reusable business logic: CTE & Views are there, but not as efficient as functions in high-level languages.
Lack of composability: SQL queries operate on concrete table names, making it difficult to build reusable query fragments.
The author proposes a Functor-style programming pattern for SQL, which is similar to the Table-Value parameter in SQL Server (T-SQL)
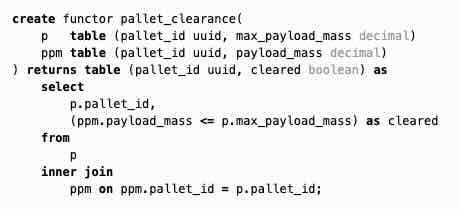
https://borretti.me/article/composable-sql
Phuong Le: How Protobuf Works—The Art of Data Encoding
Protobuf (Protocol Buffers) can serialize data into a compact binary format, making it smaller and faster to transmit over the network than human-readable formats like Json & csv. The blog narrates how Protobuf serialization converts structured data into a compact binary format by encoding each field with a tag (field number and wire type) and a value, using efficient methods like variable-length integers and length-prefixed strings.

https://victoriametrics.com/blog/go-protobuf/index.html
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.